
详细介绍
新的介绍内容:
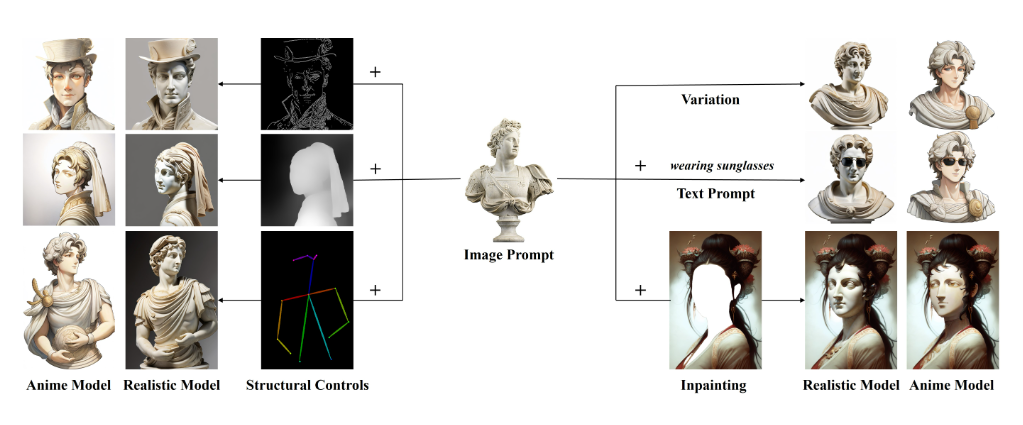
IP-Adapter是什么?
IP-Adapter(Image Prompt Adapter)是腾讯AI实验室推出的一款创新适配器,专为预训练的文本到图像扩散模型(如Stable Diffusion)设计。它通过引入图像提示,显著提升了图像生成的精确度和多样性,解决了仅依赖文本提示时可能遇到的挑战。
主要特点:
- 图像提示集成:通过集成图像作为输入提示,IP-Adapter能够生成更符合用户需求的图像。
- 轻量级设计:仅22M参数,计算资源需求低,部署和使用方便。
- 广泛适用性:适用于基于相同基础模型的各种自定义模型,具有强大的泛化能力。
- 多模态支持:兼容文本和图像提示,实现多模态图像生成。
- 结构控制兼容:可与ControlNet等结构控制工具无缝结合。
- 无需微调:避免对原始扩散模型进行微调,节省时间和资源。
- 多功能支持:包括图像到图像转换和图像修复功能。
主要功能:
- 图像编码:利用CLIP模型提取图像提示的特征。
- 特征投影:将图像特征转换为与文本特征相同的维度。
- 解耦的交叉注意力:分别处理文本和图像特征,提高生成效果。
- 训练优化:仅优化新添加的交叉注意力层参数,保持模型高效。
- 生成过程:结合文本和图像提示特征,生成符合预期的图像。
- 结构控制:在生成过程中加入额外的结构条件,增强生成的灵活性。
使用示例:
- 文本到图像生成:
- 用户输入文本提示和图像提示,IP-Adapter生成与提示高度匹配的图像。
- 图像到图像转换:
- 用户提供源图像和目标图像的草图,IP-Adapter将源图像转换为具有目标特征的新图像。
- 图像修复:
- 用户上传需要修复的图像,IP-Adapter利用图像提示进行修复,恢复图像的完整性。
总结:
IP-Adapter是一款高效、轻量且功能强大的工具,通过引入图像提示,显著提升了文本到图像扩散模型的生成能力。它不仅支持多种图像生成任务,还易于部署和使用,为图像生成领域带来了新的可能性。通过解耦的交叉注意力机制,IP-Adapter能够更好地理解和利用图像信息,生成更精确、更丰富的图像内容。
查看更多
最新文章
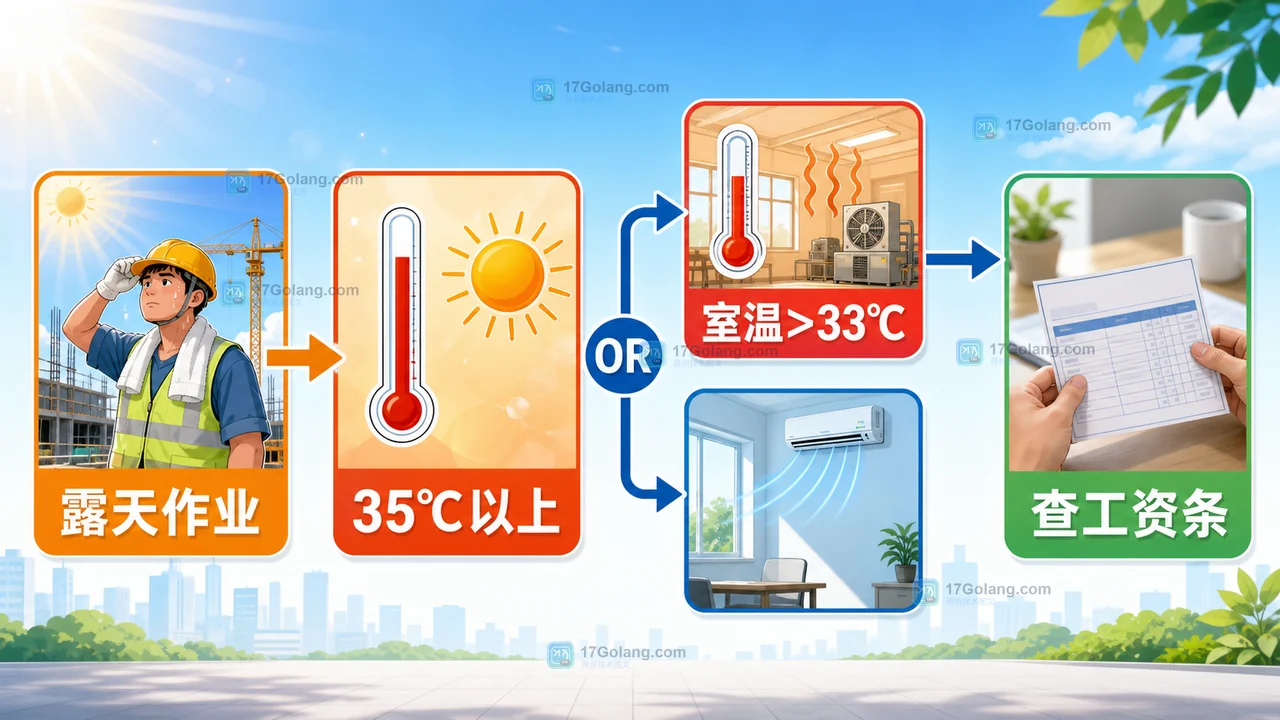
高温津贴哪些人能领?35℃、发放标准和查询方法一次说清
高温津贴不是所有上班族都会自动领取。符合高温天气露天作业,或工作场所不能有效降到 33℃以下等条件的劳动

Linux Nginx 配置 COOP 和 COEP:让 SharedArrayBuffer 可用前先做这 4 项检查
页面里使用 SharedArrayBuffer 或 Wasm Threads 时,光改前端代码通常不够。

Linux rsync 大目录同步慢怎么优化:用文件清单和分批校验把 18MB/s 拉回 92MB/s
rsync 同步大目录时,慢的往往不是网卡,而是海量小文件的扫描、元数据比较和落盘节奏。通过先测基线、生
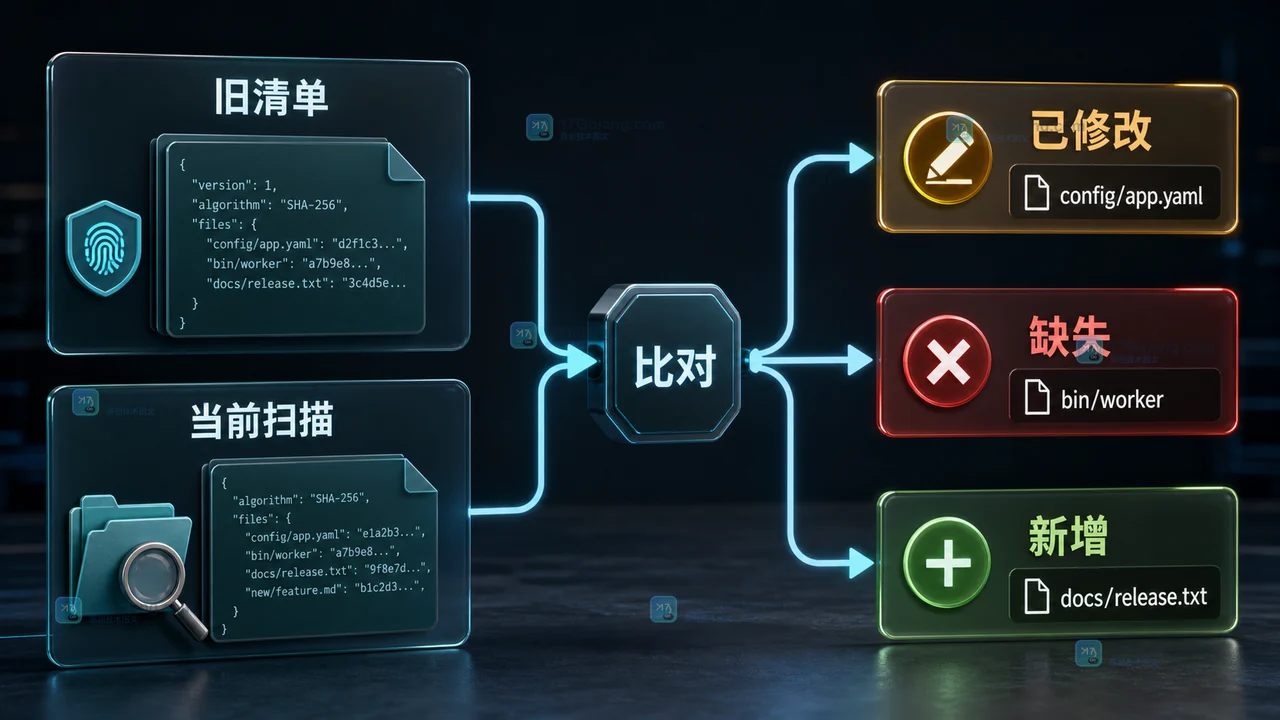
Go 实战:写一个并发 SHA-256 文件清单工具,目录扫描和结果核对一次讲清
发布包、离线资料或备份文件交付前,手工比对文件很容易漏。本文用 Go 标准库做一个并发 SHA-256

Linux 服务器进程被 OOM Killed 怎么排查:从内核日志到 cgroup 内存上限的完整流程
服务突然退出且日志只有 Killed,不要先盯着应用异常。用内核日志确认 OOM 受害进程,再区分主机内

View Transition API 实战:筛选列表切换不再硬跳,兼容回退这样落地
从商品筛选列表切换时的突兀重绘切入,使用 document.startViewTransition 包住



