MySql分组后随机获取每组一条数据的操作
来到golang学习网的大家,相信都是编程学习爱好者,希望在这里学习数据库相关编程知识。下面本篇文章就来带大家聊聊《MySql分组后随机获取每组一条数据的操作》,介绍一下随机、数据、MySQL分组,希望对大家的知识积累有所帮助,助力实战开发!
思路:先随机排序然后再分组就好了。
1、创建表:
CREATE TABLE `xdx_test` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `class` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2、插入数据
INSERT INTO xdx_test VALUES (1, '张三-1','1'); INSERT INTO xdx_test VALUES (2, '李四-1','1'); INSERT INTO xdx_test VALUES (3, '王五-1','1'); INSERT INTO xdx_test VALUES (4, '张三-2','2'); INSERT INTO xdx_test VALUES (5, '李四-2','2'); INSERT INTO xdx_test VALUES (6, '王五-2','2'); INSERT INTO xdx_test VALUES (7, '张三-3','3'); INSERT INTO xdx_test VALUES (8, '李四-3','3'); INSERT INTO xdx_test VALUES (9, '王五-3','3');
3、查询语句
SELECT * FROM (SELECT * FROM xdx_test ORDER BY RAND()) a GROUP BY a.class
4、查询结果
3 王五-1 1
5 李四-2 2
9 王五-3 3
3 王五-1 1
4 张三-2 2
7 张三-3 3
2 李四-1 1
5 李四-2 2
8 李四-3 3
补充知识:mysql实现随机获取几条数据的方法(效率和离散型比较)
sql语句有几种写法、效率、以及离散型 比较
1:SELECT * FROM tablename ORDER BY RAND() LIMIT 想要获取的数据条数;
2:SELECT *FROM `table` WHERE id >= (SELECT FLOOR( MAX(id) * RAND()) FROM `table` ) ORDER BY id LIMIT 想要获取的数据条数;
3:SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * (SELECT MAX(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id
ORDER BY t1.id ASC LIMIT 想要获取的数据条数;
4:SELECT * FROM `table`WHERE id >= (SELECT floor(RAND() * (SELECT MAX(id) FROM `table`))) ORDER BY id LIMIT 想要获取的数据条数;
5:SELECT * FROM `table` WHERE id >= (SELECT floor( RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`)) + (SELECT MIN(id) FROM `table`))) ORDER BY id LIMIT 想要获取的数据条数;
6:SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`))+(SELECT MIN(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id ORDER BY t1.id LIMIT 想要获取的数据条数;
1的查询时间>>2的查询时间>>5的查询时间>6的查询时间>4的查询时间>3的查询时间,也就是3的效率最高。
以上6种只是单纯的从效率上做了比较;
上面的6种随机数抽取可分为2类:
第一个的离散型比较高,但是效率低;其他5个都效率比较高,但是存在离散性不高的问题;
怎么解决效率和离散型都满足条件啦?
我们有一个思路就是: 写一个存储过程;
select * FROM test t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM test)-(SELECT MIN(id) FROM test)) + (SELECT MIN(id) FROM test)) AS id) t2 where t1.id >= t2.id limit 1
每次取出一条,然后循环写入一张临时表中;最后返回 select 临时表就OK;
这样既满足了效率又解决了离散型的问题;可以兼并二者的优点;
下面是具体存储过程的伪代码
DROP PROCEDURE IF EXISTS `evaluate_Check_procedure`; DELIMITER ;; CREATE DEFINER=`root`@`%` PROCEDURE `evaluate_Check_procedure`(IN startTime datetime, IN endTime datetime,IN checkNum INT,IN evaInterface VARCHAR(36)) BEGIN
-- 新建一张临时表 ,存放随机取出的数据
create temporary table if not exists xdr_authen_tmp ( `ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '序号', `LENGTH` int(5) DEFAULT NULL COMMENT '字节数', `INTERFACE` int(3) NOT NULL COMMENT '接口', `XDR_ID` varchar(32) NOT NULL COMMENT 'XDR ID', `MSISDN` varchar(32) DEFAULT NULL COMMENT '用户号码', `PROCEDURE_START_TIME` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '开始时间', `PROCEDURE_END_TIME` datetime DEFAULT NULL COMMENT '结束时间', `SOURCE_NE_IP` varchar(39) DEFAULT NULL COMMENT '源网元IP', `SOURCE_NE_PORT` int(5) DEFAULT NULL COMMENT '源网元端口', `DESTINATION_NE_IP` varchar(39) DEFAULT NULL COMMENT '目的网元IP', `DESTINATION_NE_PORT` int(5) DEFAULT NULL COMMENT '目的网元端口', `INSERT_DATE` datetime DEFAULT NULL COMMENT '插入时间', `EXTEND1` varchar(50) DEFAULT NULL COMMENT '扩展1', `EXTEND2` varchar(50) DEFAULT NULL COMMENT '扩展2', `EXTEND3` varchar(50) DEFAULT NULL COMMENT '扩展3', `EXTEND4` varchar(50) DEFAULT NULL COMMENT '扩展4', `EXTEND5` varchar(50) DEFAULT NULL COMMENT '扩展5', PRIMARY KEY (`ID`,`PROCEDURE_START_TIME`), KEY `index_procedure_start_time` (`PROCEDURE_START_TIME`), KEY `index_source_dest_ip` (`SOURCE_NE_IP`,`DESTINATION_NE_IP`), KEY `index_xdr_id` (`XDR_ID`) ) ENGINE = InnoDB DEFAULT CHARSET=utf8; BEGIN DECLARE j INT; DECLARE i INT; DECLARE CONTINUE HANDLER FOR NOT FOUND SET i = 1;
-- 这里的checkNum是需要随机获取的数据数,比如随机获取10条,那这里就是10,通过while循环来逐个获取单个随机记录;
SET j = 0;
WHILE j = "',startTime,'"',
' AND t1.PROCEDURE_START_TIME = t2.id limit 1');
PREPARE sqlexi FROM @sqlexi;
EXECUTE sqlexi;
DEALLOCATE PREPARE sqlexi;
-- 这里获取的记录有可能会重复,如果是重复数据,我们则不往临时表中插入此条数据,再进行下一次随机数据的获取。依次类推,直到随机数据取够为止;
select count(1) into @num from xdr_authen_tmp where id = @ID; if @num > 0 or i=1 then SET j = j; ELSE insert into xdr_authen_tmp(ID,LENGTH,LOCAL_PROVINCE,LOCAL_CITY,OWNER_PROVINCE,OWNER_CITY,ROAMING_TYPE,INTERFACE,XDR_ID,RAT,IMSI,IMEI,MSISDN,PROCEDURE_START_TIME,PROCEDURE_END_TIME,TRANSACTION_TYPE,TRANSACTION_STATUS,SOURCE_NE_IP,SOURCE_NE_PORT,DESTINATION_NE_IP,DESTINATION_NE_PORT,RESULT_CODE,EXPERIMENTAL_RESULT_CODE,ORIGIN_REALM,DESTINATION_REALM,ORIGIN_HOST,DESTINATION_HOST,INSERT_DATE) VALUES(@ID,@LENGTH,@LOCAL_PROVINCE,@LOCAL_CITY,@OWNER_PROVINCE,@OWNER_CITY,@ROAMING_TYPE,@INTERFACE,@XDR_ID,@RAT,@IMSI,@IMEI,@MSISDN,@PROCEDURE_START_TIME,@PROCEDURE_END_TIME,@TRANSACTION_TYPE,@TRANSACTION_STATUS,@SOURCE_NE_IP,@SOURCE_NE_PORT,@DESTINATION_NE_IP,@DESTINATION_NE_PORT,@RESULT_CODE,@EXPERIMENTAL_RESULT_CODE,@ORIGIN_REALM,@DESTINATION_REALM,@ORIGIN_HOST,@DESTINATION_HOST,@INSERT_DATE); SET j = j + 1; end if; SET i=0; END WHILE;
-- 最后我们将所有的随机数查询出来,以结果集的形式返回给后台
select ID,LENGTH,LOCAL_PROVINCE,LOCAL_CITY,OWNER_PROVINCE,OWNER_CITY,ROAMING_TYPE,INTERFACE,XDR_ID,RAT,IMSI,IMEI,MSISDN,PROCEDURE_START_TIME,PROCEDURE_END_TIME,TRANSACTION_TYPE,TRANSACTION_STATUS,SOURCE_NE_IP,SOURCE_NE_PORT,DESTINATION_NE_IP,DESTINATION_NE_PORT,RESULT_CODE,EXPERIMENTAL_RESULT_CODE,ORIGIN_REALM,DESTINATION_REALM,ORIGIN_HOST,DESTINATION_HOST,INSERT_DATE from xdr_authen_tmp; END; truncate TABLE xdr_authen_tmp; END ;; DELIMITER ;
以上这篇MySql分组后随机获取每组一条数据的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持golang学习网。
以上就是《MySql分组后随机获取每组一条数据的操作》的详细内容,更多关于mysql的资料请关注golang学习网公众号!
 Mysql InnoDB和MyISAM区别原理解析
Mysql InnoDB和MyISAM区别原理解析
- 上一篇
- Mysql InnoDB和MyISAM区别原理解析

- 下一篇
- MySQL之范式的使用详解
-

- 端庄的灯泡
- 这篇文章内容太及时了,太细致了,写的不错,已收藏,关注作者了!希望作者能多写数据库相关的文章。
- 2023-01-25 23:57:02
-
- 洁净的悟空
- 细节满满,已收藏,感谢博主的这篇技术文章,我会继续支持!
- 2023-01-25 13:58:02
-
- 会撒娇的百合
- 太给力了,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享文章!
- 2023-01-25 10:34:27
-
- 失眠的芒果
- 这篇文章真是及时雨啊,师傅加油!
- 2023-01-24 19:51:34
-
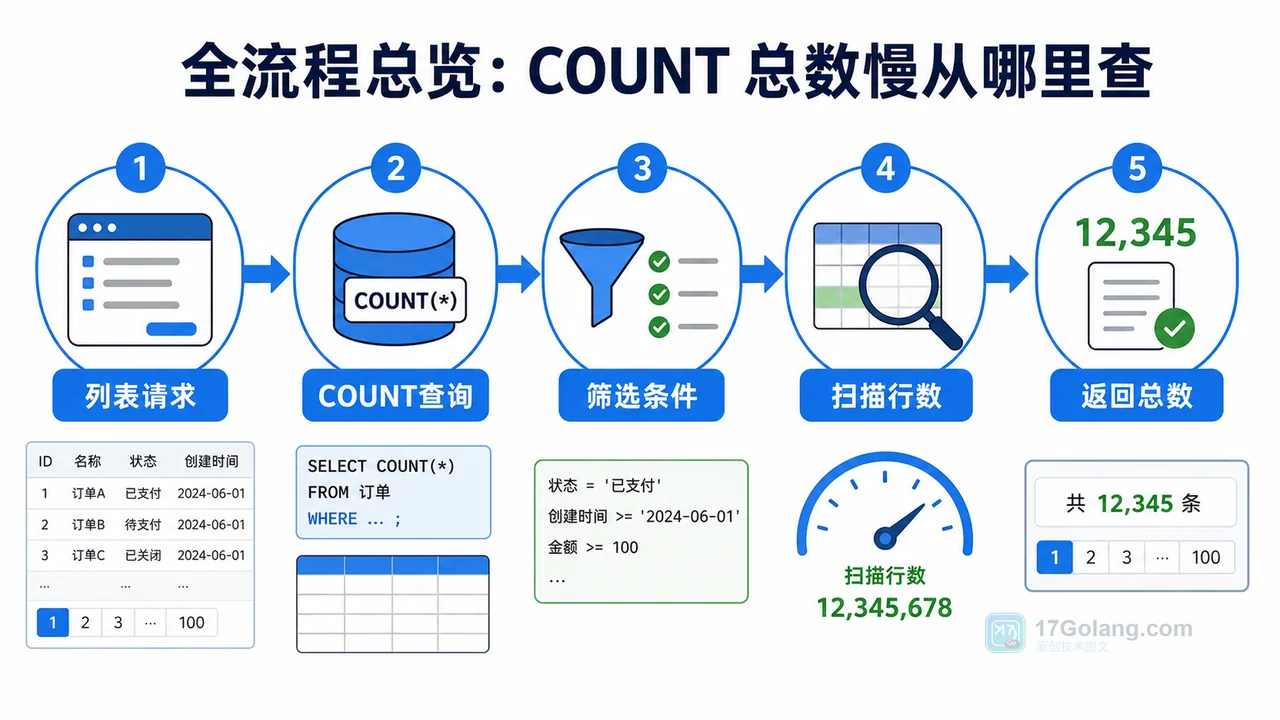
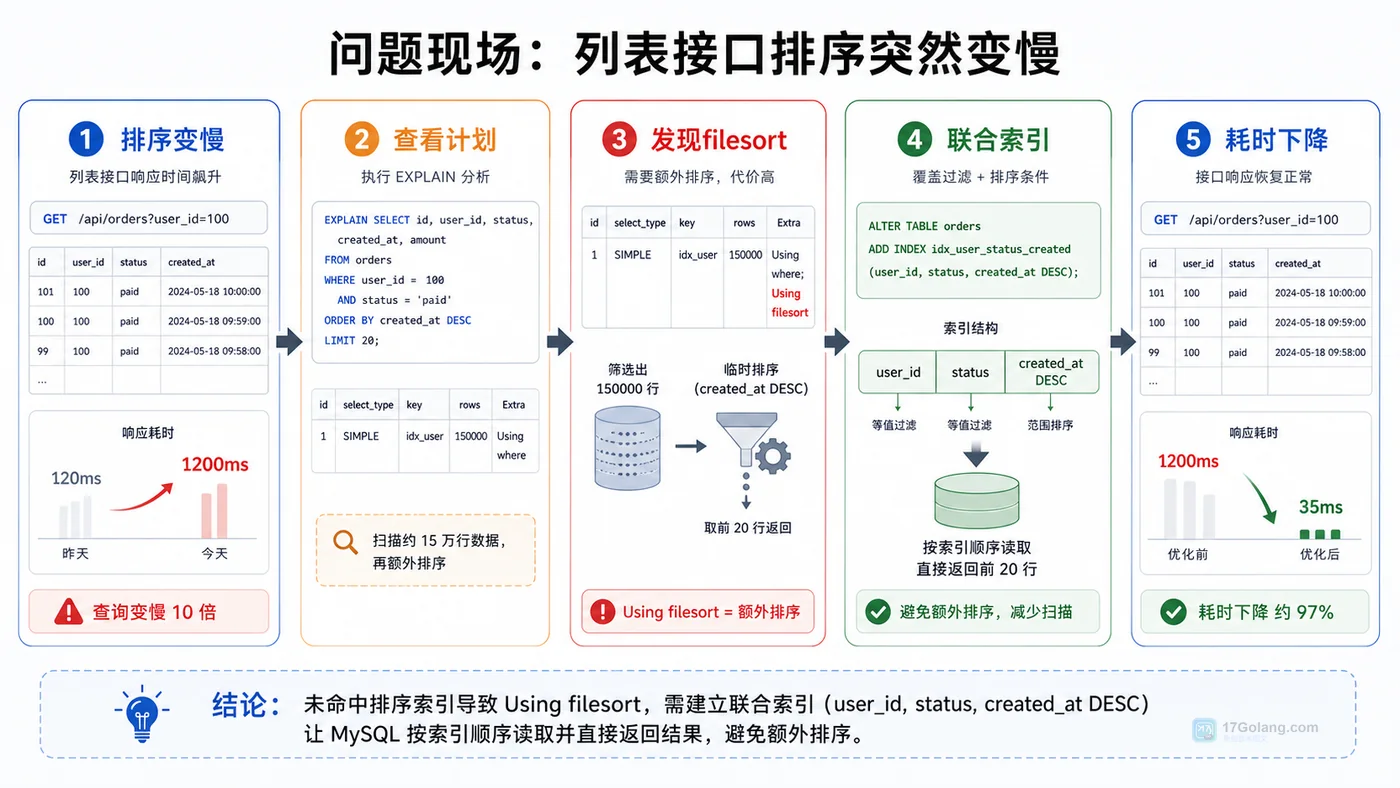
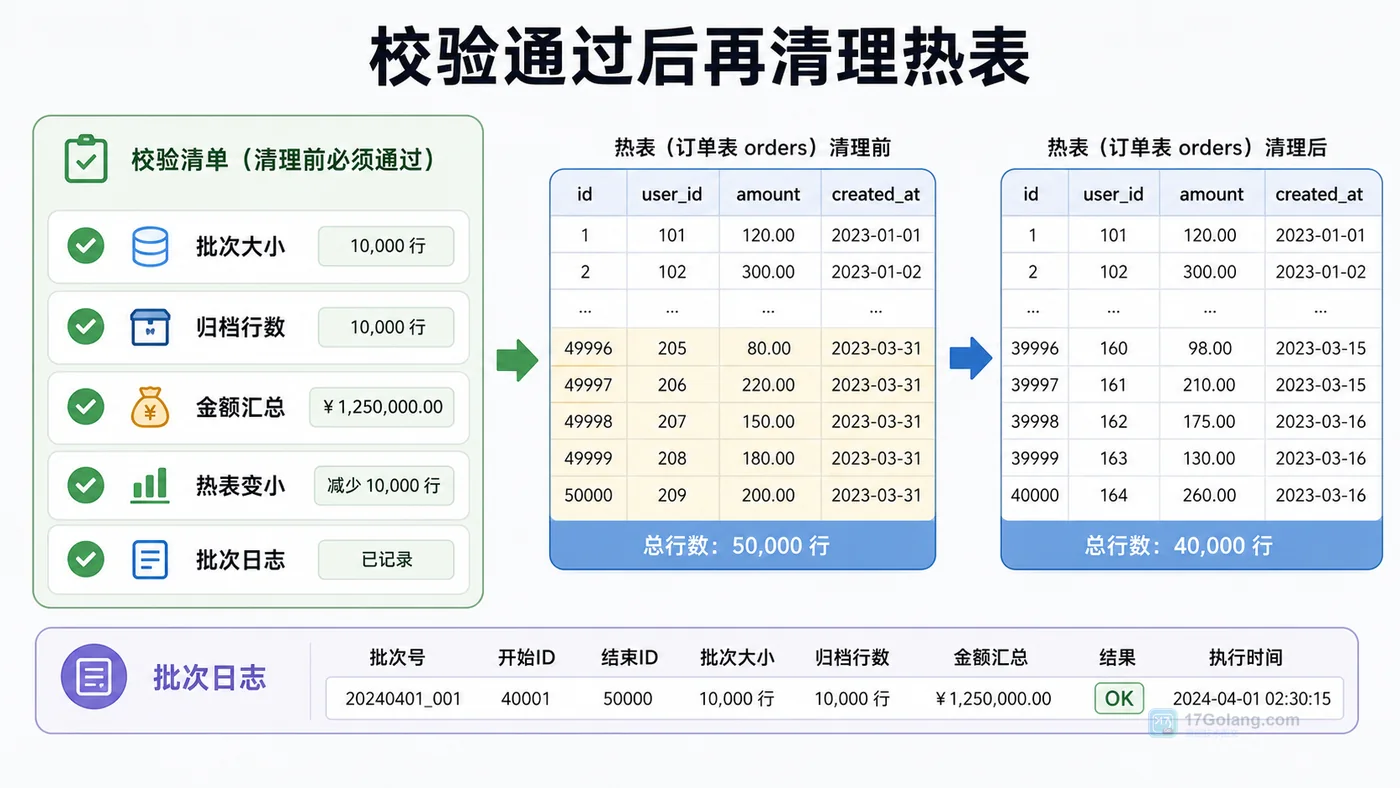
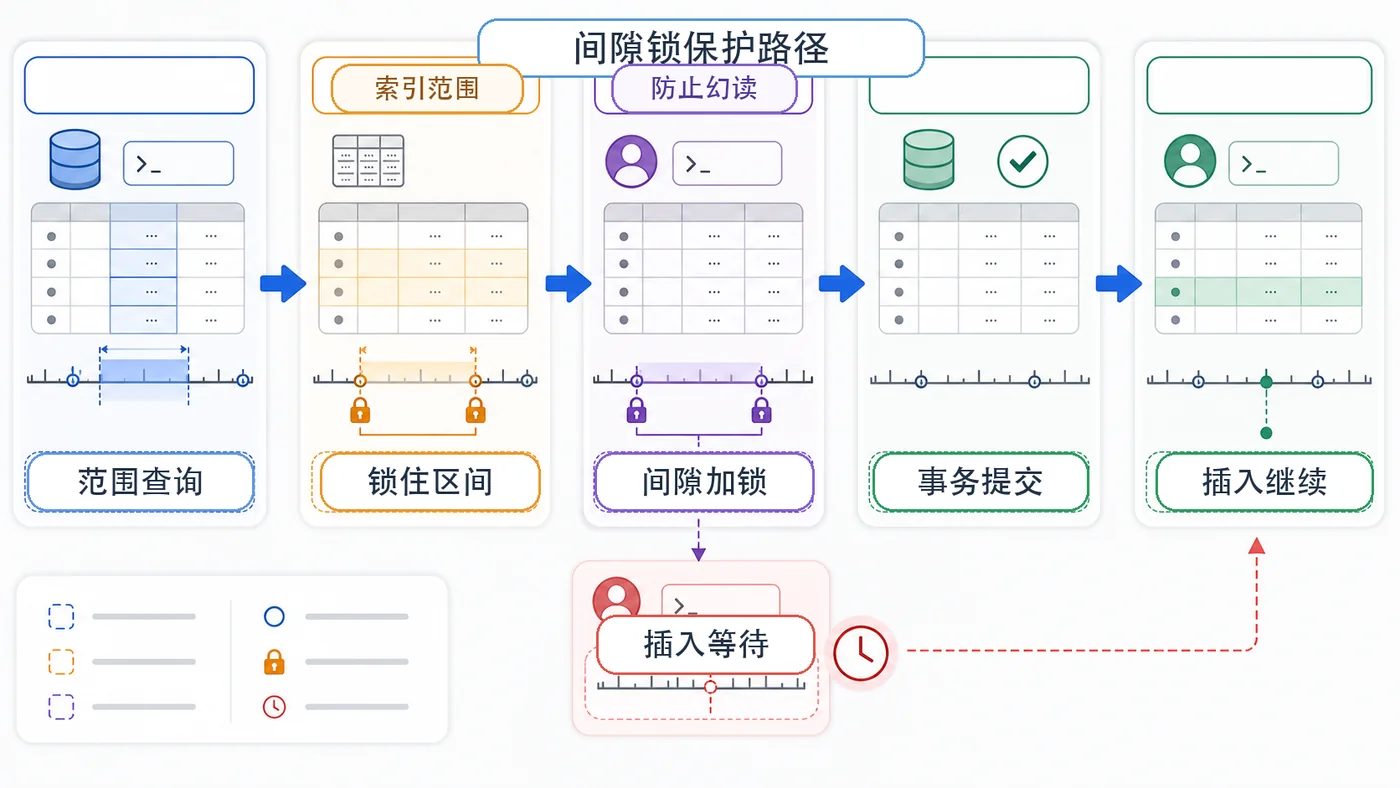
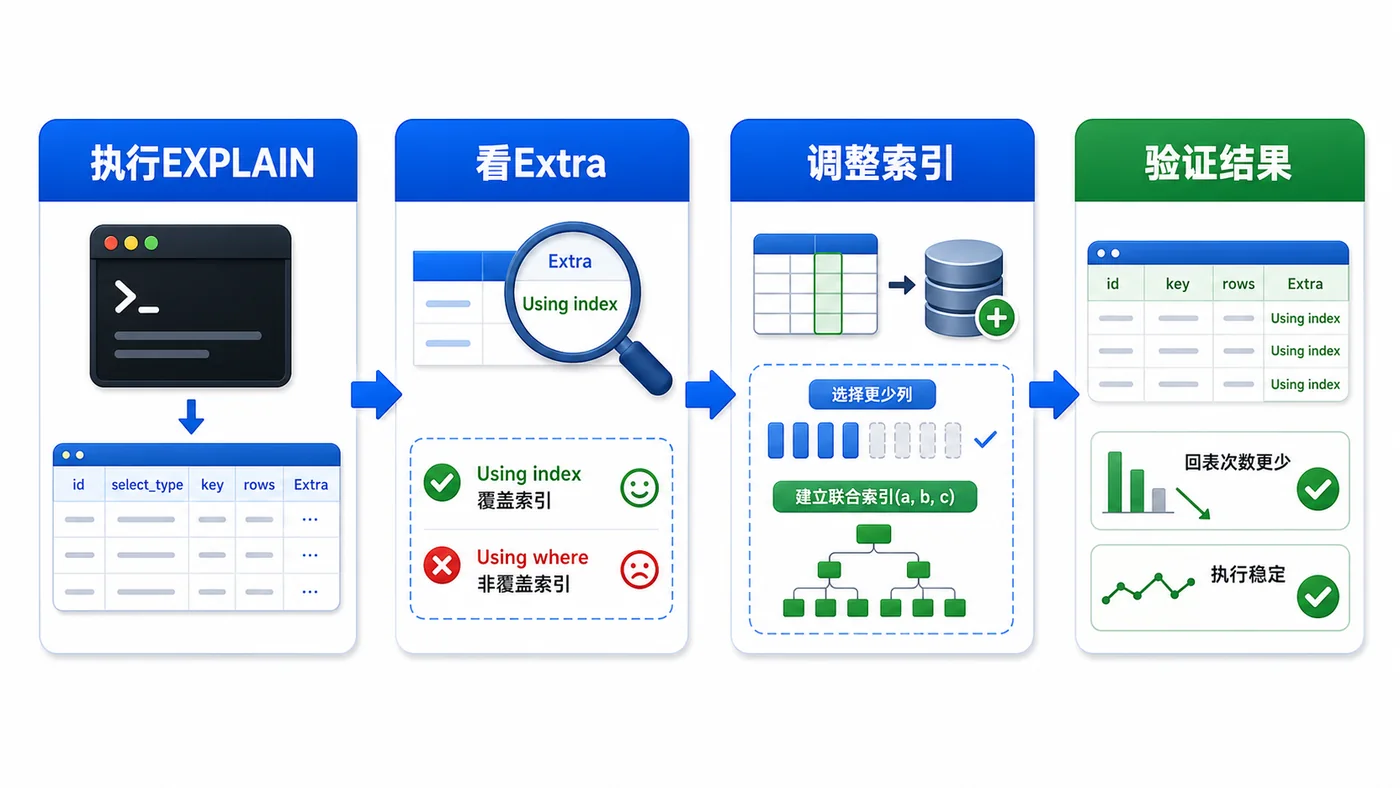
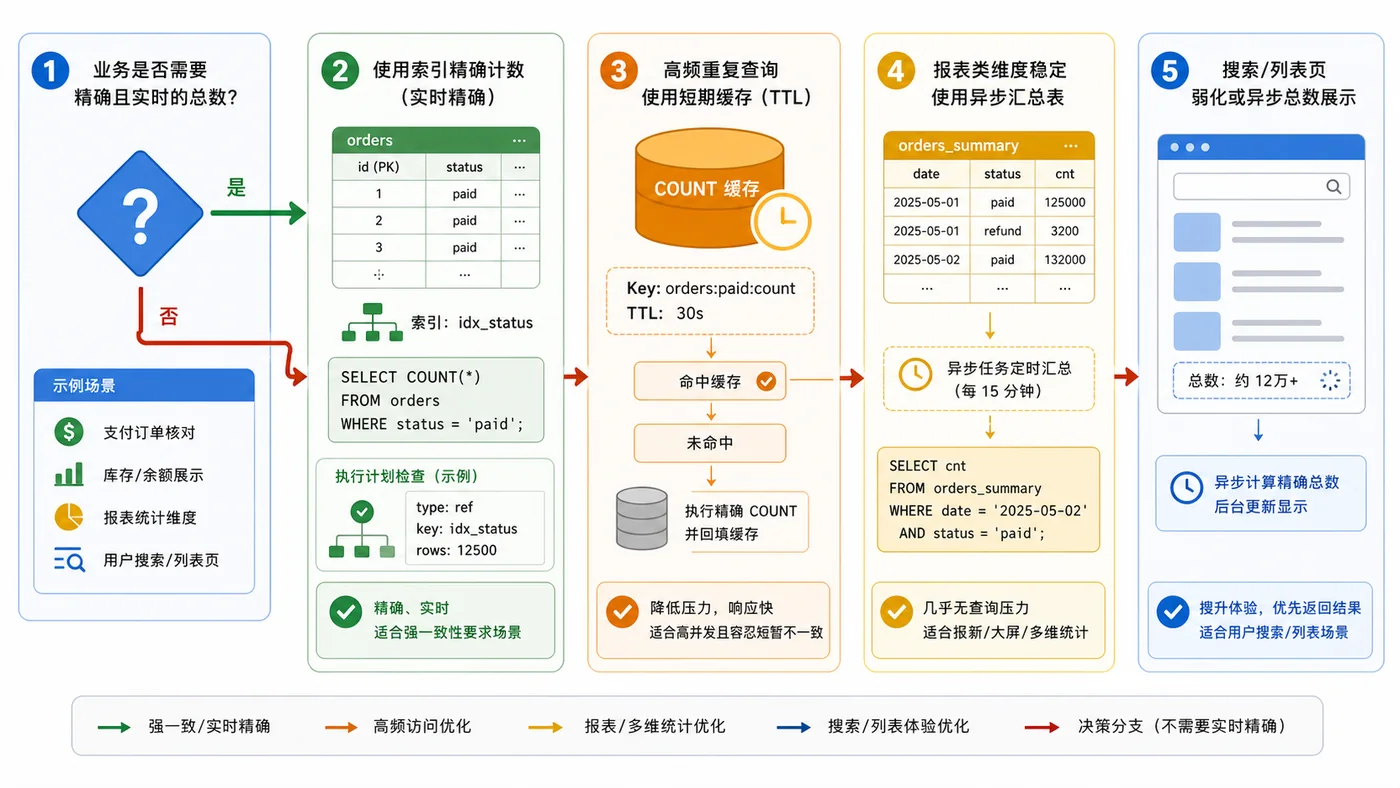
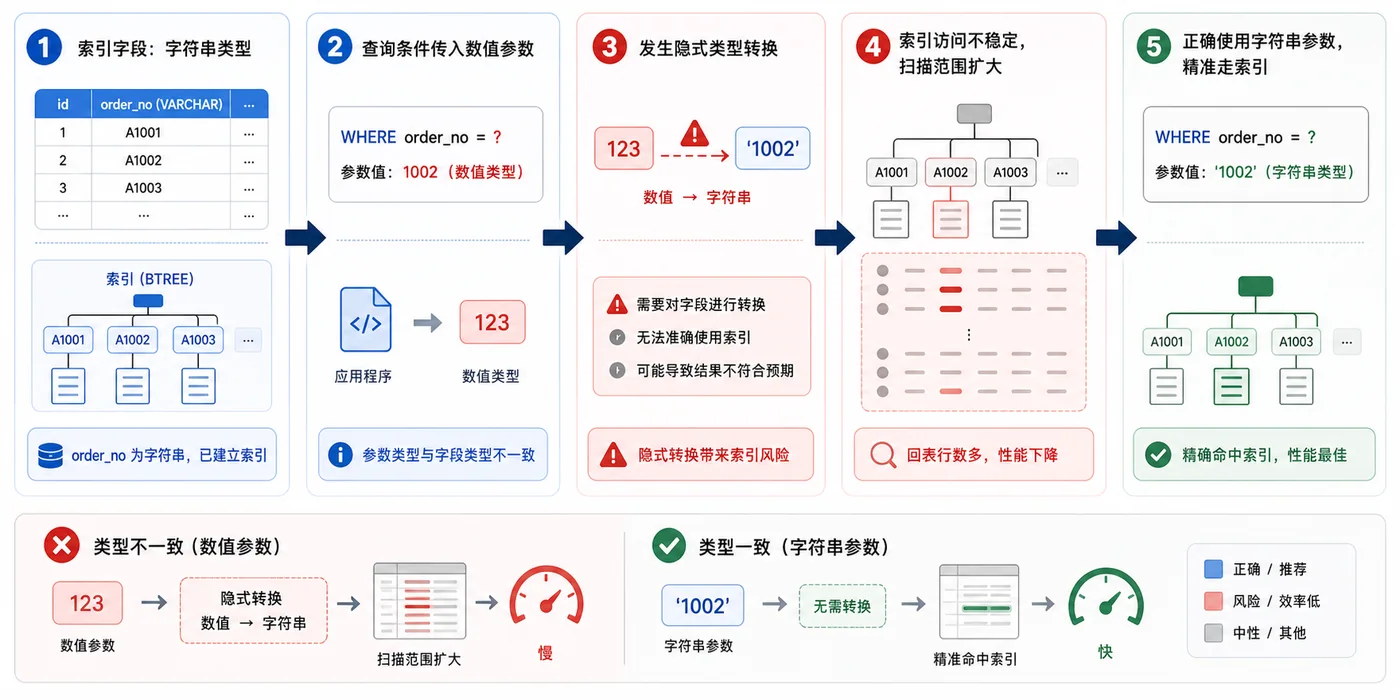
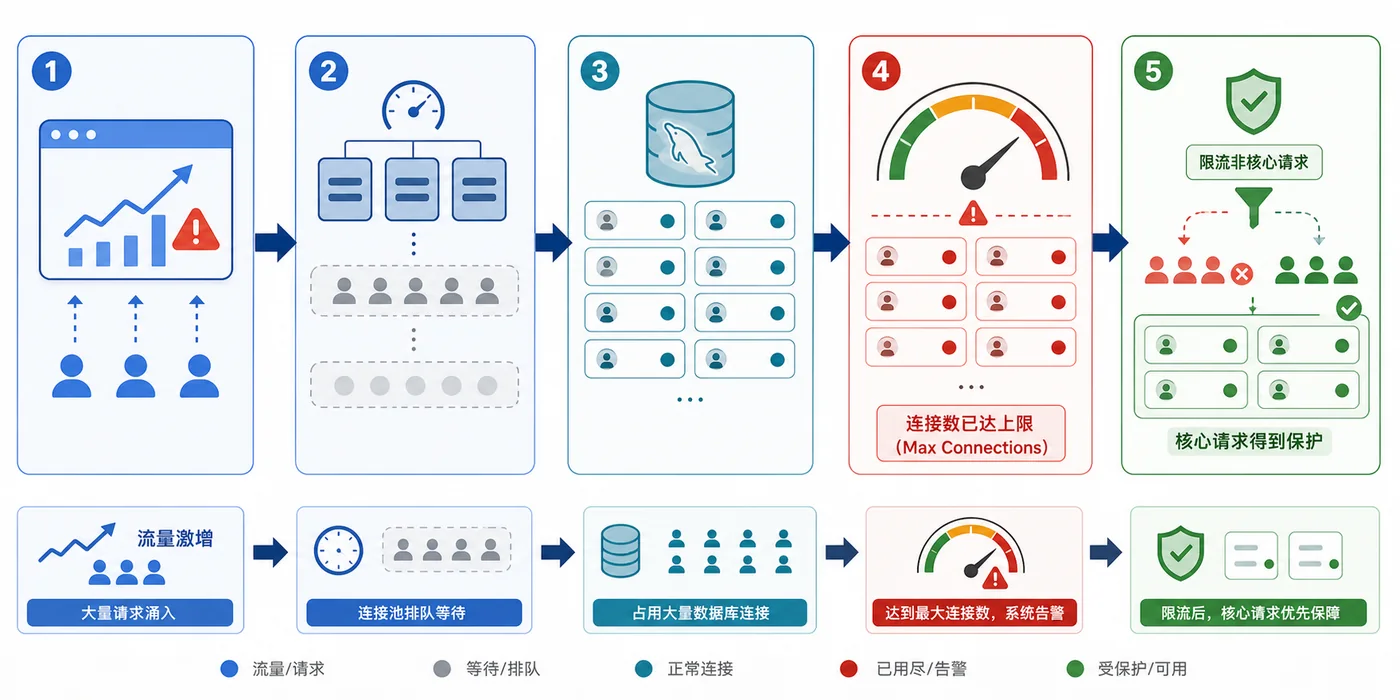
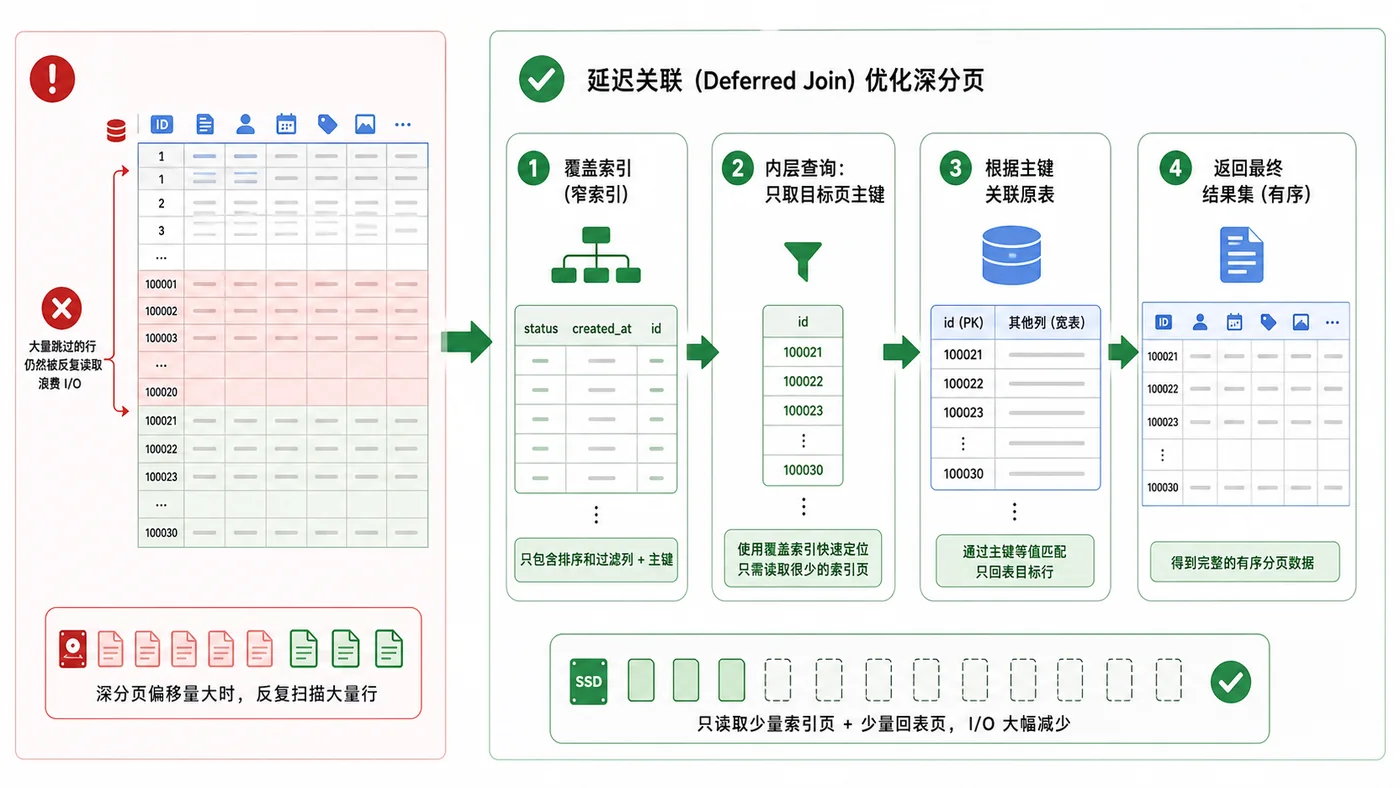
- 数据库 · MySQL | 1天前 | MySQL · 慢查询 · 索引优化 · COUNT查询 · 汇总表 · 联合索引 覆盖索引 汇总表 MySQL COUNT慢 COUNT(*)优化
- MySQL COUNT(*) 总数查询变慢怎么办:从扫描行数到汇总表的完整治理流程
- 329浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 326次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 341次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 310次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 486次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 471次使用
-
- Go实现快速生成固定长度的随机字符串
- 2023-02-24 432浏览
-
- MySQL事务处理特性的实现原理
- 2023-01-20 138浏览
-
- Golang中map数据类型的使用方法
- 2022-12-30 443浏览
-
- 一文详解Golang中的切片数据类型
- 2022-12-31 171浏览
-
- MySql恢复数据方法梳理讲解
- 2023-01-07 424浏览


