我的第一个爬虫项目:博客园爬虫(CnblogsSpider)
有志者,事竟成!如果你在学习数据库,那么本文《我的第一个爬虫项目:博客园爬虫(CnblogsSpider)》,就很适合你!文章讲解的知识点主要包括MySQL、爬虫、python3.x,若是你对本文感兴趣,或者是想搞懂其中某个知识点,就请你继续往下看吧~
一、项目介绍、开发工具及环境配置
1.1 项目介绍
博客园爬虫主要针对博客园的新闻页面进行爬取数据并入库。下面是操作步骤:
1、在打开新闻页面后,对其列表页数据的标题(含文本和链接)、图案(含图片和图片链接)、各个标签进行爬取。
2、根据深度优先遍历原理,再根据列表页的标题链接进行下一步深入,爬取里面的标题、正文、发布时间、类别标签(前面这些说的都是静态页面的爬取)和阅读数、评论数、赞同数(也叫推荐数)(后面这些说的都是基于动态网页技术的)。
3、设计表结构,也即编辑字段和字段类型。同时编写入库函数,进行数据入库。
1.2 开发工具
Pycharm2019.3
Navicat for MySQL11.1.13
1.3 环境配置
使用命令行,cd到你想放置的虚拟环境(virtualenv)的路径下,输入
import sys
import os
from scrapy.cmdline import execute # 执行scrapy的命令
if __name__ == '__main__':
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","cnblogs"])到cnblogs.py(注意这里的文件名要与main里面对应的爬虫名一样)里编写核心代码:
import re
import json
import scrapy
from urllib import parse
from scrapy import Request
from CnblogsSpider.utils import common
from CnblogsSpider.items import CnblogsArticleItem, ArticleItemLoader
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['news.cnblogs.com'] # allowed_domains域名,也即允许的范围
start_urls = ['http://news.cnblogs.com/'] # 启动main,进入爬虫,start_urls的html就下载好了
custom_settings = { # 覆盖settings以防止其他爬虫被追踪
"COOKIES_ENABLED":True
}
def start_requests(self): # 入口可以模拟登录拿到cookie
import undetected_chromedriver.v2 as uc
browser=uc.Chrome() #自动启动Chrome
browser.get("https://account.cnblogs.com/signin")
input("回车继续:")
cookies=browser.get_cookies() # 拿到cookie并转成dict
cookie_dict={}
for cookie in cookies:
cookie_dict[cookie['name']]=cookie['value']
for url in self.start_urls:
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.81 Safari/537.36'
} # 设置headers进一步防止浏览器识别出爬虫程序
yield scrapy.Request(url, cookies=cookie_dict, headers=headers, dont_filter=True) # 将cookie交给scrapy
# 以上是模拟登录代码
def parse(self, response):
url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract_first("")
post_nodes = response.xpath('//div[@class="news_block"]') # selectorlist
for post_node in post_nodes: # selector
image_url = post_node.xpath('.//div[@class="entry_summary"]/a/img/@src').extract_first("") # 用xpath选取元素并提取出字符串类型的url
if image_url.startswith("//"):
image_url="https:"+image_url
post_url = post_node.xpath('.//h2[@class="news_entry"]/a/@href').extract_first("") # 注意要加点号,表示选取一个区域内部的另一个区域
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},
callback=self.parse_detail)
# 提取下一页的URL并交给scrapy进行下载
next_url = response.xpath('//a[contains(text(),"Next >")]/@href').extract_first("")
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
match_re = re.match(".*?(\d+)", response.url)
if match_re:
post_id = match_re.group(1)
# title = response.xpath('//div[@id="news_title"]/a/text()').extract_first("")
# create_date = response.xpath('//*[@id="news_info"]//*[@class="time"]/text()').extract_first("")
# match_re = re.match(".*?(\d+.*)", create_date)
# if match_re:
# create_date = match_re.group(1)
# content = response.xpath('//div[@id="news_content"]').extract()[0]
# tag_list = response.xpath('//div[@class="news_tags"]/a/text()').extract()
# tags = ",".join(tag_list)
# article_item = CnblogsArticleItem()
# article_item["title"] = title
# article_item["create_date"] = create_date
# article_item["content"] = content
# article_item["tags"] = tags
# article_item["url"] = response.url
# if response.meta.get("front_image_url", ""):
# article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
# else:
# article_item["front_image_url"] = []
item_loader=ArticleItemLoader(item=CnblogsArticleItem(),response=response)
# item_loader.add_xpath('title','//div[@id="news_title"]/a/text()')
# item_loader.add_xpath('create_date', '//*[@id="news_info"]//*[@class="time"]/text()')
# item_loader.add_xpath('content', '//div[@id="news_content"]')
# item_loader.add_xpath('tags', '//div[@class="news_tags"]/a/text()')
item_loader.add_xpath("title", "//div[@id='news_title']/a/text()")
item_loader.add_xpath("create_date", "//*[@id='news_info']//*[@class='time']/text()")
item_loader.add_xpath("content", "//div[@id='news_content']")
item_loader.add_xpath("tags", "//div[@class='news_tags']/a/text()")
item_loader.add_value("url",response.url)
if response.meta.get("front_image_url", ""):
item_loader.add_value("front_image_url",response.meta.get("front_image_url", ""))
# article_item=item_loader.load_item()
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": item_loader,"url":response.url}, callback=self.parse_nums)
def parse_nums(self, response):
j_data = json.loads(response.text)
item_loader = response.meta.get("article_item", "")
# praise_nums = j_data["DiggCount"]
# fav_nums = j_data["TotalView"]
# comment_nums = j_data["CommentCount"]
item_loader.add_value("praise_nums",j_data["DiggCount"])
item_loader.add_value("fav_nums", j_data["TotalView"])
item_loader.add_value("comment_nums", j_data["CommentCount"])
item_loader.add_value("url_object_id", common.get_md5(response.meta.get("url","")))
# article_item["praise_nums"] = praise_nums
# article_item["fav_nums"] = fav_nums
# article_item["comment_nums"] = comment_nums
# article_item["url_object_id"] = common.get_md5(article_item["url"])
article_item = item_loader.load_item()
yield article_item这里所说的动态网页技术的处理过程如下:
按F12调出开发者模式,刷新后找network,找有Ajax字样的name,点击后查看对应的网址并转入对应的网址就可看出,里面有json格式的数据。核心关键代码如下:
def parse_detail(self, response):
match_re = re.match(".*?(\d+)", response.url)
if match_re:
post_id = match_re.group(1)
item_loader.add_value("url",response.url)
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": item_loader,"url":response.url}, callback=self.parse_nums)
def parse_nums(self, response):
j_data = json.loads(response.text)
item_loader = response.meta.get("article_item", "")
item_loader.add_value("praise_nums",j_data["DiggCount"])
item_loader.add_value("fav_nums", j_data["TotalView"])
item_loader.add_value("comment_nums", j_data["CommentCount"])
item_loader.add_value("url_object_id", common.get_md5(response.meta.get("url","")))
article_item = item_loader.load_item()
yield article_item
items.py处理数据:
import re
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import Join, MapCompose, TakeFirst, Identity
class CnblogsspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
def date_convert(value):
match_re = re.match(".*?(\d+.*)", value)
if match_re:
return match_re.group(1)
else:
return "1970-07-01"
# def remove_tags(value):
# #去掉tag中提取的评论,如遇到评论删除评论这个数据,再用MapCompose()传递过来
# if "评论" in value:
# return ""
# else:
# return value
class ArticleItemLoader(ItemLoader):
default_output_processor = TakeFirst() # 将list的第一个值以字符串格式输出且仅输出第一个
class CnblogsArticleItem(scrapy.Item):
title=scrapy.Field()
create_date=scrapy.Field(
input_processor=MapCompose(date_convert) # 对数字进行正则处理
)
url=scrapy.Field()
url_object_id=scrapy.Field()
front_image_url=scrapy.Field(
output_processor=Identity() # 采用原来的格式
)
front_image_path=scrapy.Field()
praise_nums=scrapy.Field()
comment_nums=scrapy.Field()
fav_nums=scrapy.Field()
tags=scrapy.Field(
output_processor=Join(separator=",") # 将list们join起来
)
content=scrapy.Field()pipelines.py里处理进入数据库的方式:
import scrapy
import requests
import MySQLdb
from MySQLdb.cursors import DictCursor
from twisted.enterprise import adbapi
from scrapy.exporters import JsonItemExporter
from scrapy.pipelines.images import ImagesPipeline
class CnblogsSpiderPipeline(object):
def process_item(self, item, spider):
return item
class ArticleImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['front_image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info): # 图片下载过程中的拦截
if "front_image_url" in item:
image_file_path=""
for ok,value in results:
image_file_path=value["path"]
item["front_image_path"]=image_file_path
return item
# def get_media_requests(self, item, info):
# for image_url in item['front_image_url']:
# yield self.Request(image_url)
# class ArticleImagePipeline(ImagesPipeline):
# def item_completed(self, results, item, info):
# if "front_image_url" in item:
# for ok, value in results:
# image_file_path = value["path"]
# item["front_image_path"] = image_file_path
#
# return item
class JsonExporterPipeline(object):
# 第一步,打开文件
def __init__(self):
self.file = open("articleexport.json", "wb") # w写入a追加
self.exporter=JsonItemExporter(self.file,encoding="utf-8",ensure_ascii=False)
self.exporter.start_exporting()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def spider_closed(self, spider):
self.exporter.finish_exporting()
self.file.close()
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
# 使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) # 处理异常
return item
def handle_error(self, failure, item, spider):
# 处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
# 执行具体的插入
# 根据不同的item 构建不同的sql语句并插入到mysql中
# insert_sql, params = item.get_insert_sql()
insert_sql = """
insert into cnblogs_article(title, url, url_object_id, front_image_url, front_image_path, praise_nums, comment_nums, fav_nums, tags, content, create_date)
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE praise_nums=VALUES(praise_nums)
""" # 发生主键冲突时用praise_nums更新praise_nums
# 便于排查
params = list()
# params.append(item["title"]) # 为防止抛异常,设置下面的做法,允许为空
params.append(item.get("title", ""))
params.append(item.get("url", ""))
params.append(item.get("url_object_id", ""))
# params.append(item.get("front_image_url", "")) # 不改的话,传过来的是个list,故当为空列表时要转化成字符串,用,join转为字符串
front_image = ",".join(item.get("front_image_url", []))
params.append(front_image)
params.append(item.get("front_image_path", ""))
params.append(item.get("praise_nums", 0))
params.append(item.get("comment_nums", 0))
params.append(item.get("fav_nums", 0))
params.append(item.get("tags", ""))
params.append(item.get("content", ""))
params.append(item.get("create_date", "1970-07-01"))
cursor.execute(insert_sql, tuple(params)) # list强转成tuplesettings.py配置全局设置:
import os
# Scrapy settings for CnblogsSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'CnblogsSpider'
SPIDER_MODULES = ['CnblogsSpider.spiders']
NEWSPIDER_MODULE = 'CnblogsSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'CnblogsSpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'CnblogsSpider.middlewares.CnblogsspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'CnblogsSpider.middlewares.CnblogsspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'CnblogsSpider.pipelines.CnblogsspiderPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
ITEM_PIPELINES = {
'CnblogsSpider.pipelines.ArticleImagePipeline':1,
'CnblogsSpider.pipelines.MysqlTwistedPipline':2,
'CnblogsSpider.pipelines.JsonExporterPipeline':3,
'CnblogsSpider.pipelines.CnblogsSpiderPipeline': 300
}
IMAGES_URLS_FILED="front_image_url"
project_dir=os.path.dirname(os.path.abspath(__file__))
IMAGES_STORE=os.path.join(project_dir,'images')
MYSQL_HOST = "127.0.0.1"
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
SQL_DATETIME_FORMAT = "%Y-%m-%d %H:%M:%S"
SQL_DATE_FORMAT = "%Y-%m-%d"common.py处理url自动生成md5格式:
import hashlib
def get_md5(url):
if isinstance(url,str):
url=url.encode("utf-8")
m=hashlib.md5()
m.update(url)
return m.hexdigest()最后运打开Navicat for MySQL,连接好数据库后,运行main文件,爬虫就开始运行并入库啦~
理论要掌握,实操不能落!以上关于《我的第一个爬虫项目:博客园爬虫(CnblogsSpider)》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
 Windows10安装MySQL8
Windows10安装MySQL8
- 上一篇
- Windows10安装MySQL8

- 下一篇
- Navicat 16 for MySQL 修改注册表 永久试用
-

- 奋斗的小刺猬
- 这篇文章真及时,太细致了,太给力了,mark,关注作者了!希望作者能多写数据库相关的文章。
- 2023-03-01 14:07:09
-
- 俊逸的日记本
- 太全面了,已加入收藏夹了,感谢大佬的这篇文章内容,我会继续支持!
- 2023-02-25 12:29:16
-
- 有魅力的手链
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享技术文章!
- 2023-02-21 12:17:10
-
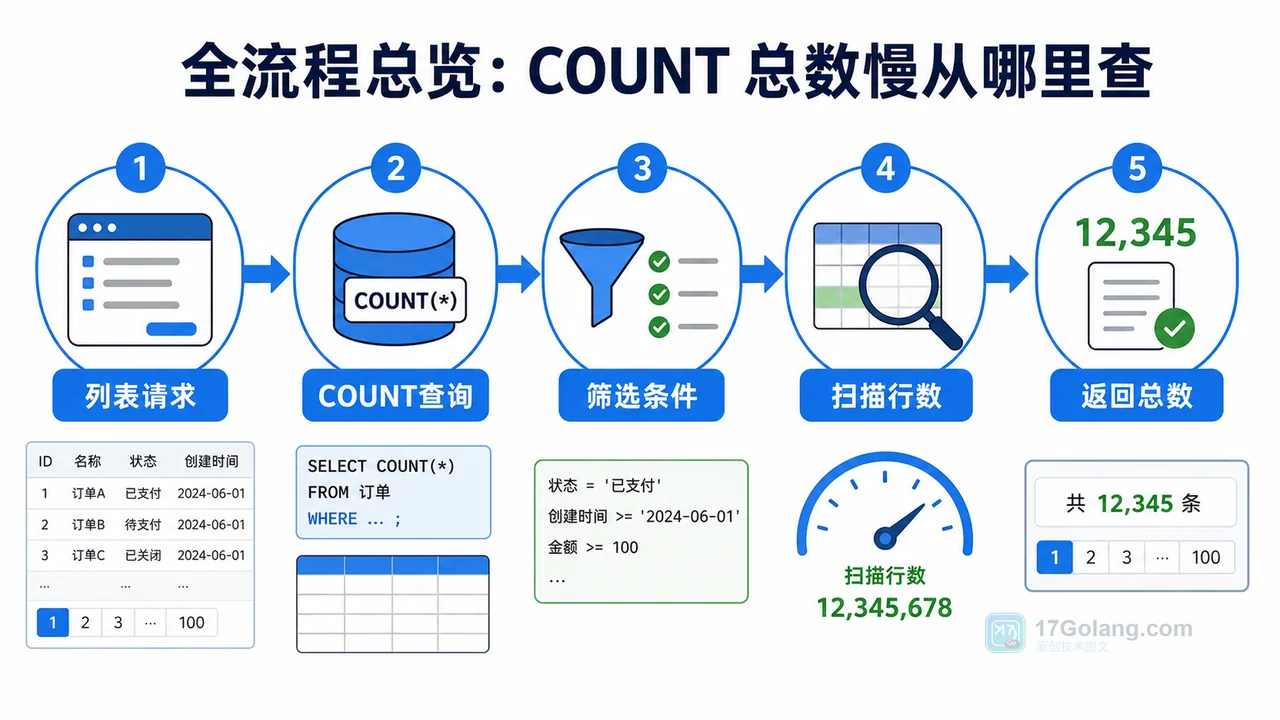
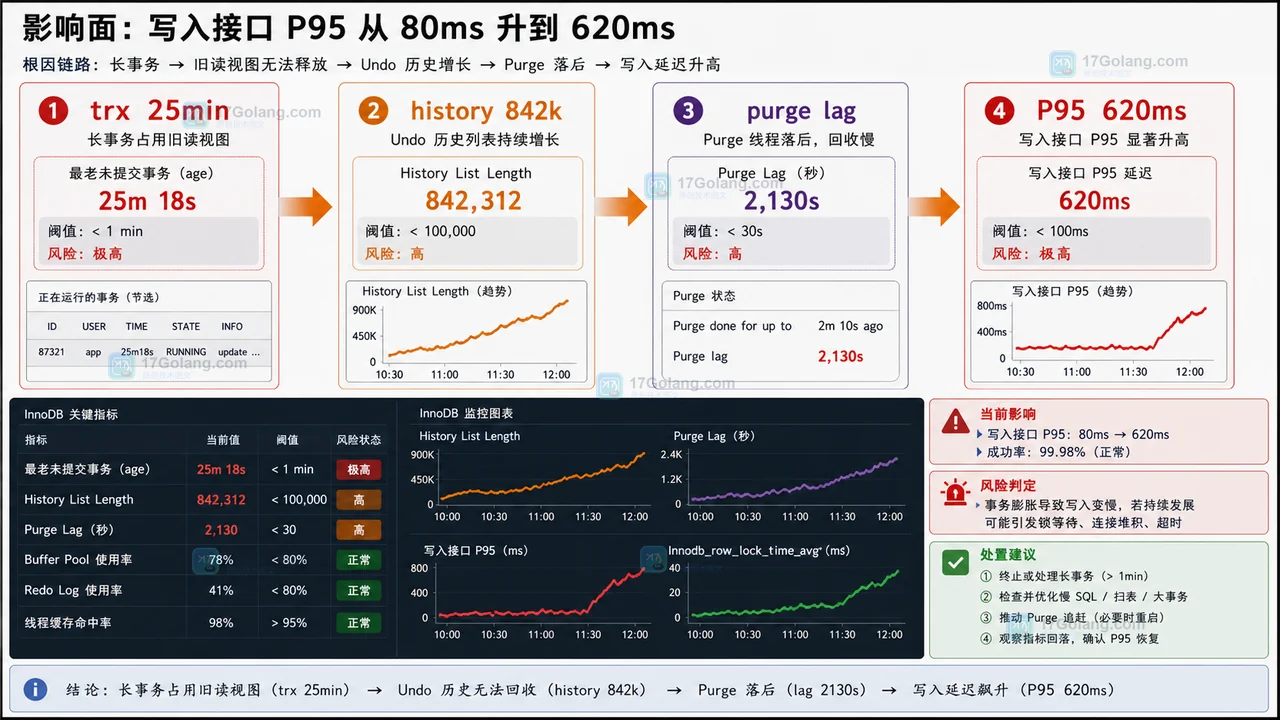
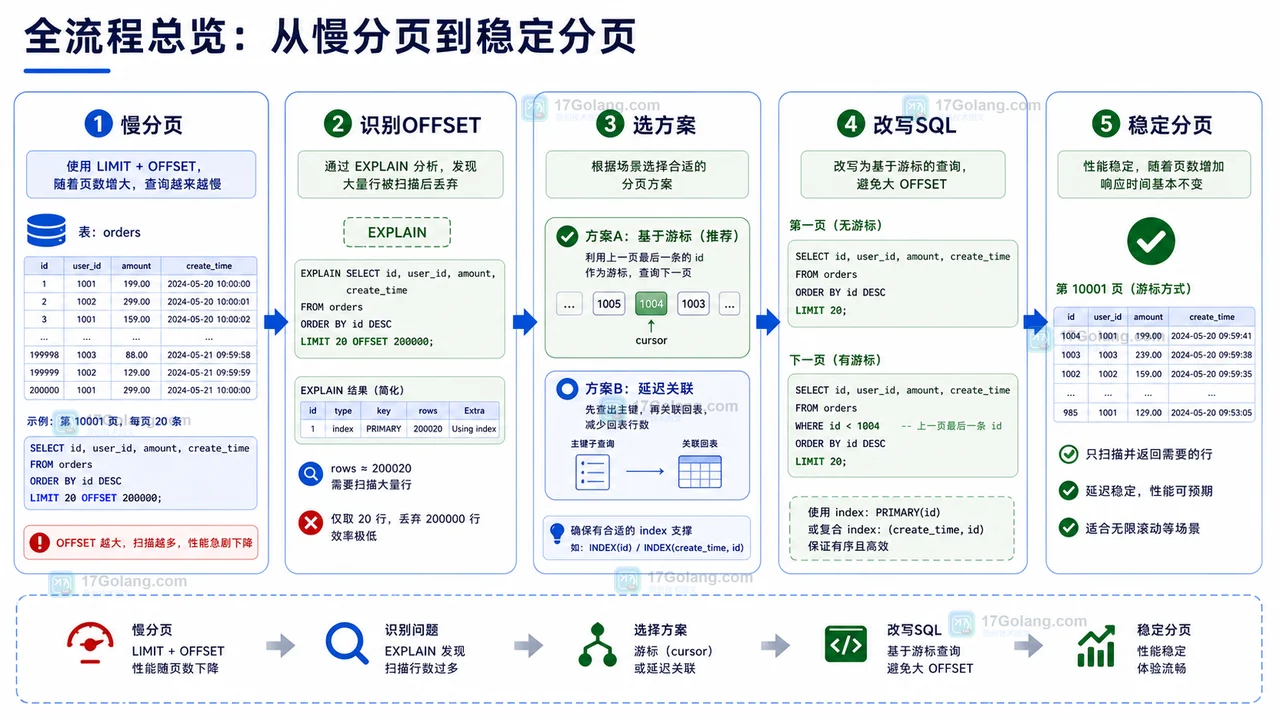
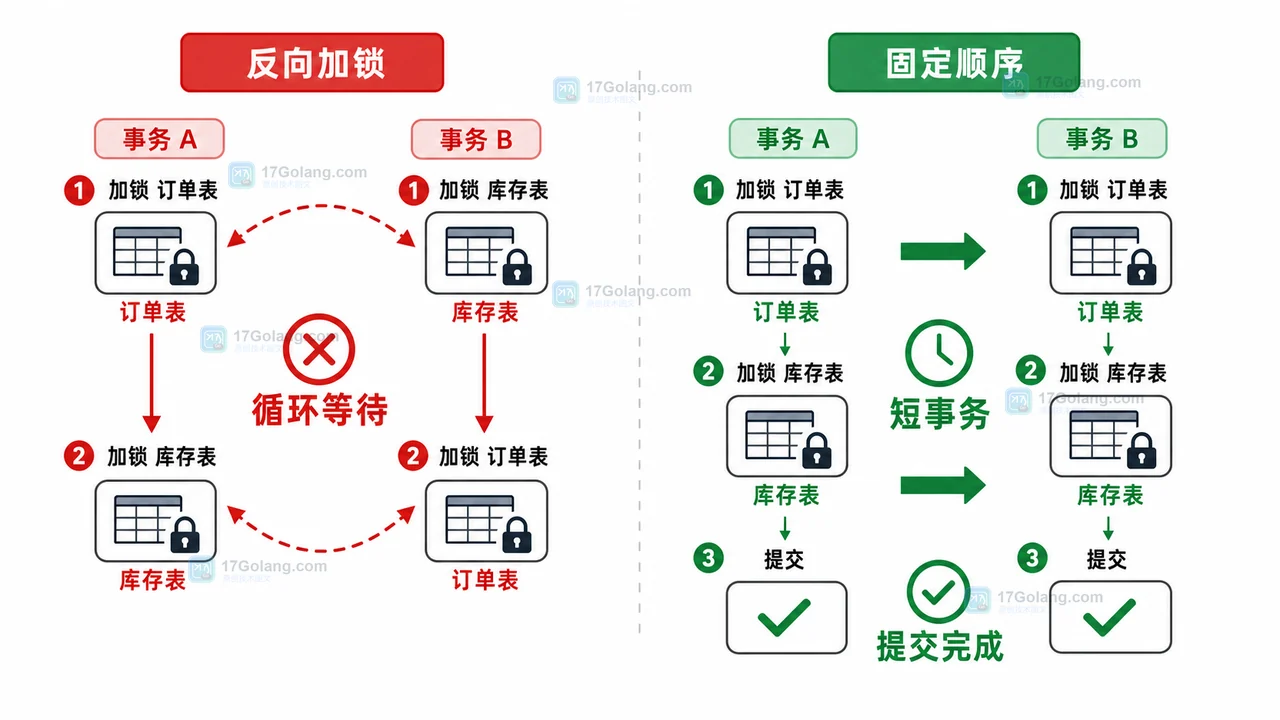
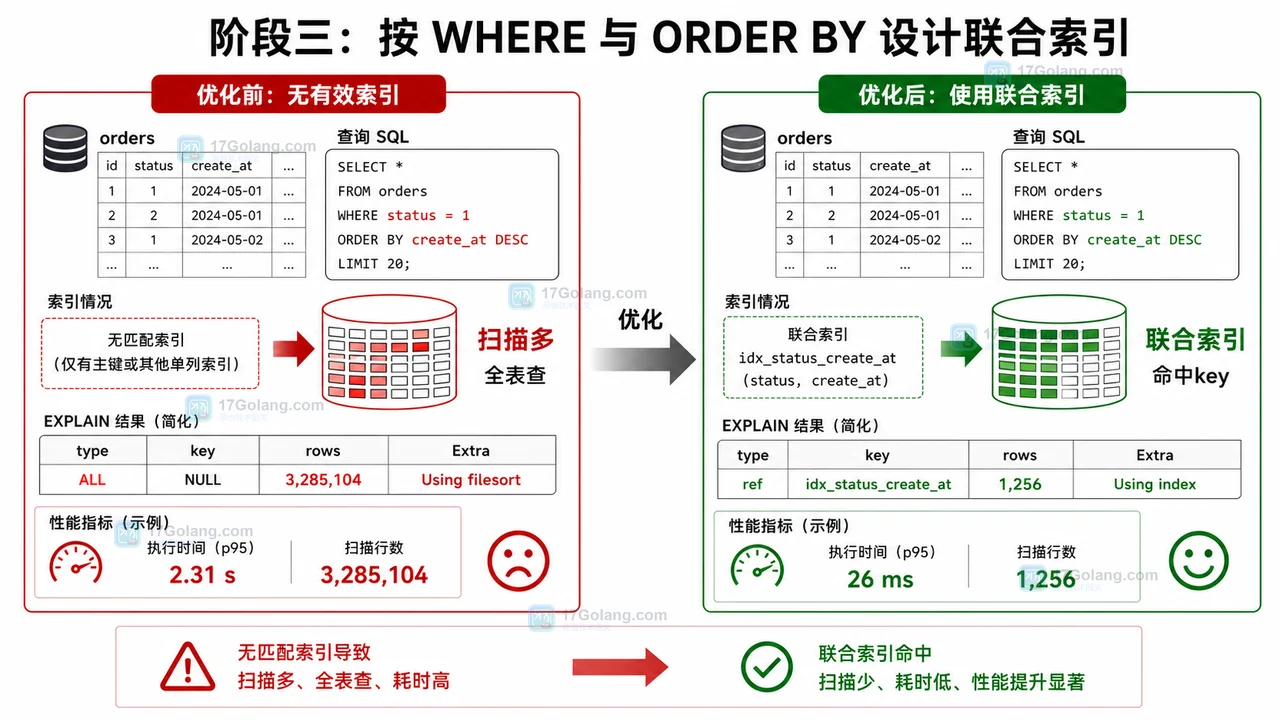
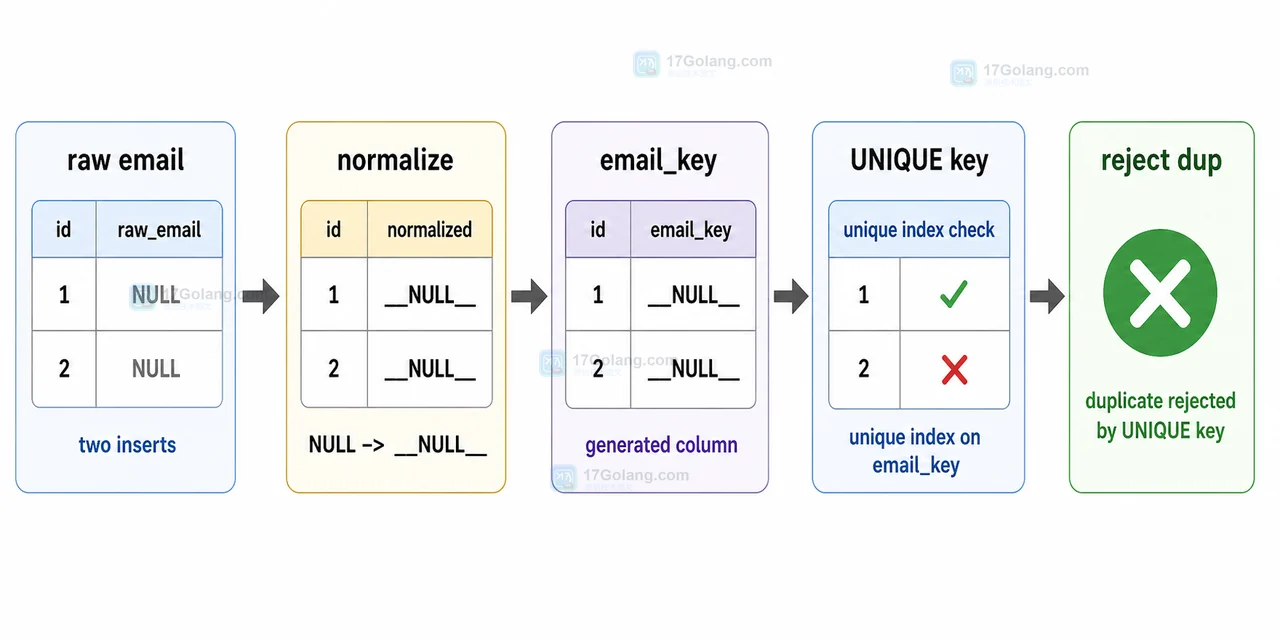
- 数据库 · MySQL | 2星期前 | MySQL · 慢查询 · 索引优化 · COUNT查询 · 汇总表 · 联合索引 覆盖索引 汇总表 MySQL COUNT慢 COUNT(*)优化
- MySQL COUNT(*) 总数查询变慢怎么办:从扫描行数到汇总表的完整治理流程
- 329浏览 收藏






-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3157次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2919次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2872次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3078次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3033次使用
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- go colly 爬虫实现示例
- 2022-12-22 331浏览
-
- Go语言并发爬虫的具体实现
- 2022-12-23 459浏览
-
- golang 通过ssh代理连接mysql的操作
- 2022-12-23 206浏览
-
- IDEA配置连接MYSQL数据库遇到Failed这个问题解决
- 2022-12-28 500浏览


