Python爬取北京二手房数据,揭秘北漂买房难度,附源码
标题:Python爬取北京二手房数据,分析北漂买房难吗?附源码 内容摘要:本文通过Python爬取赶集网北京二手房数据,并使用R进行线性回归分析,探讨北漂买房的难易程度。文章分为两部分:首先介绍了使用Xpath、Beautiful Soup和正则表达式三种方法爬取数据的过程,详细展示了代码实现。其次,利用R对爬取的数据进行房价分析,适合初学者学习参考。通过本文,读者可以了解到北京二手房市场的基本情况,并掌握Python和R在数据分析中的应用。

作者 徐麟
本文经授权转自公众号数据森麟(ID: shujusenlin)
房价高是北漂们一直关心的话题,本文就对北京的二手房数据进行了分析。
本文主要分为两部分:Python爬取赶集网北京二手房数据,R对爬取的二手房房价做线性回归分析,适合刚刚接触Python&R的同学们学习参考。
01
Python爬取赶集网北京二手房数据
入门爬虫一个月,所以对每一个网站都使用了Xpath、Beautiful Soup、正则三种方法分别爬取,用于练习巩固。数据来源如下:
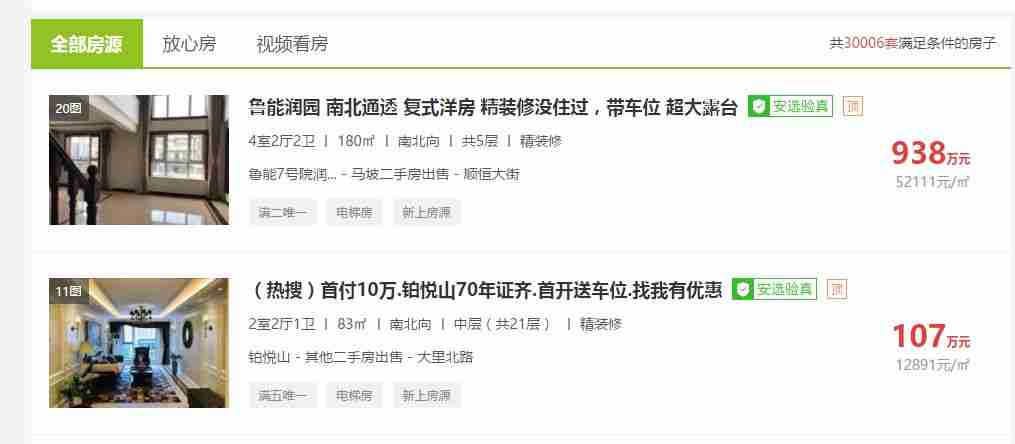
Xpath爬取:
这里主要解决运用Xpath如何判断某些元素是否存在的问题,比如如果房屋没有装修信息,不加上判断,某些元素不存在就会导致爬取中断。
代码语言:javascript代码运行次数:0运行复制import requestsfrom lxml import etreefrom requests.exceptions import RequestExceptionimport multiprocessingimport timeheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}def get_one_page(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return Nonedef parse_one_page(content): try: selector = etree.HTML(content) ALL = selector.xpath('//*[@id="f_mew_list"]/div[6]/div[1]/div[3]/div[1]/div') for div in ALL: yield { 'Name': div.xpath('dl/dd[1]/a/text()')[0], 'Type': div.xpath('dl/dd[2]/span[1]/text()')[0], 'Area': div.xpath('dl/dd[2]/span[3]/text()')[0], 'Towards': div.xpath('dl/dd[2]/span[5]/text()')[0], 'Floor': div.xpath('dl/dd[2]/span[7]/text()')[0].strip().replace('\n', ""), 'Decorate': div.xpath('dl/dd[2]/span[9]/text()')[0], #地址需要特殊处理一下 'Address': div.xpath('dl/dd[3]//text()')[1]+div.xpath('dl/dd[3]//text()')[3].replace('\n','')+div.xpath('dl/dd[3]//text()')[4].strip(), 'TotalPrice': div.xpath('dl/dd[5]/div[1]/span[1]/text()')[0] + div.xpath('dl/dd[5]/div[1]/span[2]/text()')[0], 'Price': div.xpath('dl/dd[5]/div[2]/text()')[0] } if div['Name','Type','Area','Towards','Floor','Decorate','Address','TotalPrice','Price'] == None:##这里加上判断,如果其中一个元素为空,则输出None return None except Exception: return Nonedef main(): for i in range(1, 500):#这里设置爬取500页数据,在数据范围内,大家可以自设置爬取的量 url = 'http://bj.ganji.com/fang5/o{}/'.format(i) content = get_one_page(url) print('第{}页抓取完毕'.format(i)) for div in parse_one_page(content): print(div)if __name__ == '__main__': main()Beautiful Soup爬取:
代码语言:javascript代码运行次数:0运行复制import requestsimport refrom requests.exceptions import RequestExceptionfrom bs4 import BeautifulSoupimport csvimport timeheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}def get_one_page(url): try: response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None except RequestException: return Nonedef parse_one_page(content): try: soup = BeautifulSoup(content,'html.parser') items = soup.find('div',class_=re.compile('js-tips-list')) for div in items.find_all('div',class_=re.compile('ershoufang-list')): yield { 'Name':div.find('a',class_=re.compile('js-title')).text, 'Type': div.find('dd', class_=re.compile('size')).contents[1].text,#tag的 .contents 属性可以将tag的子节点以列表的方式输出 'Area':div.find('dd',class_=re.compile('size')).contents[5].text, 'Towards':div.find('dd',class_=re.compile('size')).contents[9].text, 'Floor':div.find('dd',class_=re.compile('size')).contents[13].text.replace('\n',''), 'Decorate':div.find('dd',class_=re.compile('size')).contents[17].text, 'Address':div.find('span',class_=re.compile('area')).text.strip().replace(' ','').replace('\n',''), 'TotalPrice':div.find('span',class_=re.compile('js-price')).text+div.find('span',class_=re.compile('yue')).text, 'Price':div.find('div',class_=re.compile('time')).text } #有一些二手房信息缺少部分信息,如:缺少装修信息,或者缺少楼层信息,这时候需要加个判断,不然爬取就会中断。 if div['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price'] == None: return None except Exception: return Nonedef main(): for i in range(1,50): url = 'http://bj.ganji.com/fang5/o{}/'.format(i) content = get_one_page(url) print('第{}页抓取完毕'.format(i)) for div in parse_one_page(content): print(div) with open('Data.csv', 'a', newline='') as f: # Data.csv 文件存储的路径,如果默认路径就直接写文件名即可。 fieldnames = ['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() for item in parse_one_page(content): writer.writerow(item) time.sleep(3)#设置爬取频率,一开始我就是爬取的太猛,导致网页需要验证。if __name__=='__main__': main()正则爬取:我研究了好久,还是没有解决。
这一过程中容易遇见的问题有:
有一些房屋缺少部分信息,如缺少装修信息,这个时候需要加一个判断,如果不加判断,爬取就会自动终止(我在这里跌了很大的坑)。Data.csv知识点存储文件路径默认是工作目录,关于Python中如何查看工作目录:代码语言:javascript代码运行次数:0运行复制import os #查看pyhton 的默认工作目录print(os.getcwd())#修改时工作目录os.chdir('e:\\workpython')print(os.getcwd())#输出工作目录e:\workpython爬虫打印的是字典形式,每个房屋信息都是一个字典,由于Python中excel相关库是知识盲点,所以爬虫的时候将字典循环直接写入了CSV。Pycharm中打印如下:

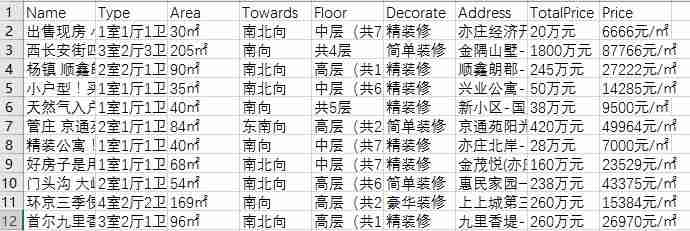
将字典循环直接写入CSV效果如下:

02
R对爬取的二手房房价做一般线性回归分析
下面我们用R对抓取的赶集网北京二手房数据做一些简单的分析。
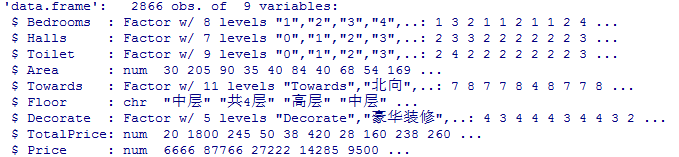
数据的说明
数据清洗
代码语言:javascript代码运行次数:0运行复制data

#在爬取的时候加入了判断,所以不知道爬取的数据中是否存在缺失值,这里检查一下colSums(is.na(DATA))

#这里将Type的卧室客厅和卫生间分为三个不同的列##这里需要注意,有一些房屋没有客厅如:1室1卫这时候需要单独处理,还有一些没有厕所信息。library(tidyr)library(stringr)DATA=separate(data=DATA,col=Type,into = c("Bedrooms","Halls"),sep="室")DATA=separate(data=DATA,col=Halls,into = c("Halls","Toilet"),sep="厅")##将卫生间后面的汉字去掉DATA$Toilet
##这里将Area后的㎡去掉DATA$Area

##将数据转换格式DATA$Bedrooms
今天关于《Python爬取北京二手房数据,揭秘北漂买房难度,附源码》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于Python,线性回归,爬虫,R,北京二手房的内容请关注golang学习网公众号!
 兼职APP开发的好处与收入潜力大揭秘
兼职APP开发的好处与收入潜力大揭秘
- 上一篇
- 兼职APP开发的好处与收入潜力大揭秘

- 下一篇
- PHP中混合类型啥意思?
-

- 文章 · 软件教程 | 5天前 | go · vs code · 软件教程 · 测试任务 · tasks.json · VS Code 测试任务 终端输出 Go插件 Go测试 tasks.json 问题面板
- VS Code 怎么给 Go 项目配置测试任务:tasks.json 运行与结果验收
- 501浏览 收藏
-

- 文章 · 软件教程 | 6天前 | 开发工具 · vs code · profiles · 软件教程 · 配置同步 · 软件教程 Visual Studio Code VS Code Profiles 配置档 导出配置 导入配置
- VS Code Profiles 怎么用:创建、导出和导入开发配置档
- 185浏览 收藏
-

- 文章 · 软件教程 | 6天前 | 开发环境 · windows terminal · 软件教程 · 终端工具 · Ubuntu PowerShell 软件教程 Windows Terminal 默认配置文件 起始路径
- Windows Terminal 默认启动配置怎么改:PowerShell、Ubuntu 和起始路径设置
- 495浏览 收藏
-

- 文章 · 软件教程 | 6天前 | Windows · 软件教程 · PowerToys · PowerRename · 批量重命名 · PowerToys 批量重命名 软件教程 PowerRename Windows重命名 文件改名
- PowerToys PowerRename 批量重命名怎么用:先看预览再应用
- 413浏览 收藏
-

- 文章 · 软件教程 | 6天前 | [] · []
- DBeaver 导入 CSV 到数据库怎么做:字段映射、预览校验和结果核对
- 217浏览 收藏
-

- 文章 · 软件教程 | 1星期前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合
- Postman 导出和导入接口集合:Collection 与 Environment 迁移检查
- 308浏览 收藏
-
- 文章 · 软件教程 | 1星期前 | PNG · diagrams.net · 软件教程 · draw.io · 流程图 · 透明背景 流程图 软件教程 Diagrams.net PNG导出 draw.io 图片归档
- diagrams.net 导出高清 PNG:透明背景、缩放比例和回导核对流程
- 130浏览 收藏
-

- 文章 · 软件教程 | 2星期前 | 版本控制 · source control · 软件教程 · VS Code教程 · Git冲突 · VS Code 软件教程 Git冲突 Source Control Merge Editor 提交核对
- VS Code 解决 Git 合并冲突:从 Source Control 到提交核对
- 395浏览 收藏
-

- 文章 · 软件教程 | 2星期前 | network · Har · 软件教程 · Chrome DevTools · 前端调试 · 软件教程 Chrome DevTools HAR文件 Network面板 前端排查
- Chrome DevTools 导出 HAR 文件:从 Network 捕获到脱敏核对
- 410浏览 收藏
-
- 文章 · 软件教程 | 2星期前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings
- VS Code 搜索排除不生效:search.exclude 和 Use Exclude Settings 设置排查
- 256浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4501次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4178次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4147次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4374次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4316次使用
-
- VS Code 怎么给 Go 项目配置测试任务:tasks.json 运行与结果验收
- 2026-07-09 501浏览
-
- Windows 11 如何开启 HEIF 图片支持
- 2026-05-31 501浏览
-
- TikTok用户画像与付费订阅变现方法
- 2026-05-27 501浏览
-
- 学信网学历翻译件申请方法
- 2026-05-27 501浏览
-
- Windows 11 24H2 更新失败0x80070005解决方法
- 2026-05-26 501浏览


