HTMLRobots标签设置方法,控制搜索引擎抓取
想要精准控制搜索引擎抓取,提升网站SEO效果?本文为您详细解读HTML Robots标签的设置方法,包括Meta Robots标签和X-Robots-Tag的运用。Meta Robots标签嵌入HTML头部,适用于HTML页面,通过`index`、`noindex`、`follow`、`nofollow`等指令,控制页面是否被索引及链接是否被追踪。而X-Robots-Tag作为HTTP响应头,优先级更高,可应用于各种文件类型,实现更灵活的抓取控制。本文还将深入探讨Robots标签指令的选择、常见误区与潜在风险,助您优化网站,避免因设置不当导致的SEO问题。
控制搜索引擎抓取可通过Meta Robots标签或X-Robots-Tag实现,前者用于HTML页面,后者适用于所有文件类型且优先级更高。

控制搜索引擎抓取,主要通过在HTML页面头部设置Meta Robots标签,或者在HTTP响应头中添加X-Robots-Tag来实现。这两种方式都能直接告诉搜索引擎的爬虫,当前页面是否应该被索引、是否应该追踪页面上的链接,以及其他一些行为规范。
HTML Robots标签的设置,本质上是给搜索引擎爬虫下达指令,告诉它们如何处理你网站上的特定页面或资源。最常见的做法是在HTML文档的部分加入一个标签,像这样:
这里的content属性可以包含多个指令,用逗号分隔。
index: 允许搜索引擎索引此页面。noindex: 禁止搜索引擎索引此页面,这意味着它不会出现在搜索结果中。follow: 允许搜索引擎跟踪此页面上的所有链接。nofollow: 禁止搜索引擎跟踪此页面上的所有链接,这对于防止“链接权重”流向不信任的外部网站或用户生成内容(UGC)很有用。all: 等同于index, follow,通常是默认行为,可以省略。none: 等同于noindex, nofollow。noarchive: 禁止搜索引擎在搜索结果中显示此页面的缓存链接。nosnippet: 禁止搜索引擎在搜索结果中显示此页面的摘要(description)。notranslate: 禁止搜索引擎提供此页面的翻译。noimageindex: 禁止搜索引擎索引此页面上的图片。unavailable_after: [日期时间]: 告诉搜索引擎在此指定日期和时间之后停止索引此页面。
另一种更强大的方式是使用X-Robots-Tag HTTP响应头。这个标签不是放在HTML里,而是由服务器在发送文件时作为HTTP响应的一部分发送。它的优势在于可以控制非HTML文件的抓取和索引,比如PDF文档、图片、视频文件等。
例如,在Apache服务器的.htaccess文件中,你可以这样设置:
Header set X-Robots-Tag "noindex, nofollow"
这段代码会告诉搜索引擎,所有PDF、DOC和JPG文件都不要索引,也不要追踪它们内部的链接。
选择哪种方式取决于你的具体需求和文件类型。对于普通的HTML页面,Meta Robots标签非常方便。而对于需要精细控制各种文件类型,或者你无法直接修改HTML内容的情况,X-Robots-Tag则显得更为灵活和强大。
如何选择合适的Robots标签指令以优化网站SEO?
说实话,这事儿挺重要的,但也很容易被误解。选择合适的Robots标签指令,核心在于理解你希望搜索引擎如何处理你的内容,以及这会如何影响用户在搜索结果中找到你的网站。
noindex指令,我个人觉得是使用频率最高的,也最需要小心。什么时候用它呢?比如你的网站有一些内部搜索结果页、登录注册页、用户个人中心、或者一些测试页面、开发环境页面。这些页面通常内容重复、价值不高,或者不希望被公开搜索到。把它们noindex,可以避免搜索引擎抓取和索引这些“垃圾”页面,从而集中“权重”到真正有价值的内容上,避免所谓的“内容稀释”。另外,对于那些你暂时不想展示给公众,但又不得不在线的草稿页面,noindex也是个不错的临时方案。
nofollow指令,它的作用是告诉搜索引擎不要把这个链接的“权重”传递出去。早期SEO里,大家会用它来做所谓的“链接雕塑”,试图控制内部链接的权重流向。但现在Google已经明确表示,nofollow更多的是一个“提示”,而不是强制命令,而且对于内部链接的nofollow,Google也可能选择忽略。所以,我现在主要用nofollow来处理用户生成内容(UGC)中的外部链接(比如论坛帖子里的链接),或者指向一些我无法完全信任的外部网站的链接,以防被判定为链接工厂或垃圾链接。
至于noarchive和nosnippet,它们更多是关于搜索结果页面的展示方式。如果你有一些内容更新非常频繁,或者包含敏感信息,不希望搜索引擎展示旧的缓存版本,noarchive就派上用场了。nosnippet则是在你不希望搜索结果显示页面摘要时使用,比如某些特定类型的商品页面,你可能希望用户直接点击进入,而不是在搜索结果页就看到太多信息。
我的建议是,在做任何noindex或nofollow的决定前,先问自己:这个页面对我的目标用户有没有直接价值?它是不是我希望用户通过搜索找到的?如果答案是否定的,那么考虑使用这些指令。但一定要谨慎,一个不小心把重要页面noindex了,那损失可就大了。
X-Robots-Tag HTTP响应头与Meta Robots标签有何区别?
这两者虽然目的相同,都是控制搜索引擎行为,但实现方式和适用场景上存在一些关键差异,理解这些差异对我们进行精细化SEO控制非常有帮助。
首先,最直观的区别是位置。Meta Robots标签是嵌入在HTML文档的部分的一个元素。这意味着它只能应用于HTML页面,而且需要你能够编辑页面的HTML代码。而X-Robots-Tag则是一个HTTP响应头,由服务器在发送文件给浏览器或爬虫时一并发送。它不是页面内容的一部分,而是HTTP协议层面的信息。
其次是适用范围。Meta Robots标签只能作用于HTML页面。如果你有一个PDF文件、图片(JPG、PNG)、视频文件(MP4)或者其他非HTML格式的文档,Meta Robots标签就无能为力了。这时候,X-Robots-Tag的优势就体现出来了。服务器可以在发送这些非HTML文件时,通过HTTP响应头来添加X-Robots-Tag,从而控制搜索引擎对这些文件的抓取和索引行为。比如,你不希望你的网站上的所有PDF文档都被索引,那么通过X-Robots-Tag来设置就非常高效。
再来是实现方式。Meta Robots标签通常是直接修改HTML模板或通过CMS(内容管理系统)的设置来完成。而X-Robots-Tag的设置则需要服务器层面的配置,比如在Apache的.htaccess文件、Nginx的配置文件,或者通过编程语言(如PHP、Python、Node.js)在服务器端动态设置HTTP响应头。这对于一些没有HTML页面的动态生成内容或二进制文件尤其有用。
最后,优先级问题。如果一个页面同时存在Meta Robots标签和X-Robots-Tag,并且指令相互冲突,通常情况下,X-Robots-Tag的指令会优先执行。这是因为HTTP响应头是在页面内容被解析之前就传达给爬虫的。
我个人在实际工作中,通常会先考虑Meta Robots标签,因为它更直观,对HTML页面管理方便。但一旦涉及到非HTML资源、大规模控制或者需要更底层、更统一的配置时,我就会转向X-Robots-Tag。它能提供更强大的控制力,尤其是在处理大量不同类型文件时,能大大简化管理。
设置Robots标签时常见的误区和潜在风险是什么?
在实际操作中,设置Robots标签虽然看似简单,但稍有不慎就可能踩坑,甚至对网站的SEO造成灾难性的影响。我见过不少案例,都是因为对这些标签理解不深或者配置失误导致的。
最大的一个风险,也是最常见的误区,就是不小心把重要页面noindex了。这就像是给自己网站的大门上锁,然后把钥匙丢了。一个不经意的content="noindex"指令,可能导致你的核心产品页、博客文章甚至整个网站在搜索结果中消失。我曾经遇到过一个客户,因为开发人员在测试环境中设置了noindex,结果上线时忘记移除,导致网站流量骤降,好几周才发现问题所在。所以,部署前务必仔细检查,并利用Google Search Console的URL检查工具进行验证。
另一个常见的混淆是将noindex与robots.txt中的Disallow指令混为一谈。这两者虽然都与搜索引擎抓取有关,但作用机制完全不同。robots.txt是告诉搜索引擎“这里不允许你爬”,它阻止的是爬虫访问页面内容。但如果一个页面被其他网站大量链接,即使robots.txt阻止了爬取,Google仍然可能索引这个URL,只是不显示内容摘要。而noindex指令,无论是通过Meta标签还是X-Robots-Tag,是告诉搜索引擎“你可以爬,但请不要把这个页面放到搜索结果中”。如果一个页面在robots.txt中被Disallow了,那么搜索引擎可能根本无法访问到页面中的noindex指令,也就无法执行noindex。所以,如果你确定不想让某个页面被索引,最稳妥的方式是允许爬取,但明确设置noindex。
过度使用nofollow也是一个值得注意的问题。虽然Google现在将nofollow视为“提示”而非“指令”,但如果你对内部链接过度使用nofollow,可能会在一定程度上影响内部链接权重的传递,从而影响某些页面的排名。当然,对于用户生成内容中的外部链接,或者广告链接,使用nofollow(或者更现代的sponsored和ugc属性)依然是推荐的做法。
此外,忘记检查部署后的效果也是一个大问题。很多时候,我们设置了指令,就以为万事大吉了。但实际上,配置错误、服务器缓存、CDN设置等都可能导致指令没有生效。所以,利用Google Search Console(或者Bing Webmaster Tools)的“URL检查”功能,查看特定URL的抓取和索引状态,是验证Robots标签是否正确生效的关键一步。
最后,还有一个比较隐蔽的风险,就是在robots.txt中错误地阻止了对CSS、JavaScript等资源的抓取。虽然这不是Robots标签本身的问题,但它会影响搜索引擎对页面内容的理解和渲染。如果搜索引擎无法访问到页面的关键样式和脚本,它可能无法正确渲染页面,从而影响对页面内容和用户体验的评估,进而影响索引和排名。所以,在配置robots.txt时,一定要确保允许搜索引擎抓取所有对页面渲染至关重要的资源。
本篇关于《HTMLRobots标签设置方法,控制搜索引擎抓取》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于文章的相关知识,请关注golang学习网公众号!
 Golang云原生适配,Fabric案例详解
Golang云原生适配,Fabric案例详解
- 上一篇
- Golang云原生适配,Fabric案例详解

- 下一篇
- Everything快速查U盘文件技巧
-

- 文章 · 前端 | 7小时前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
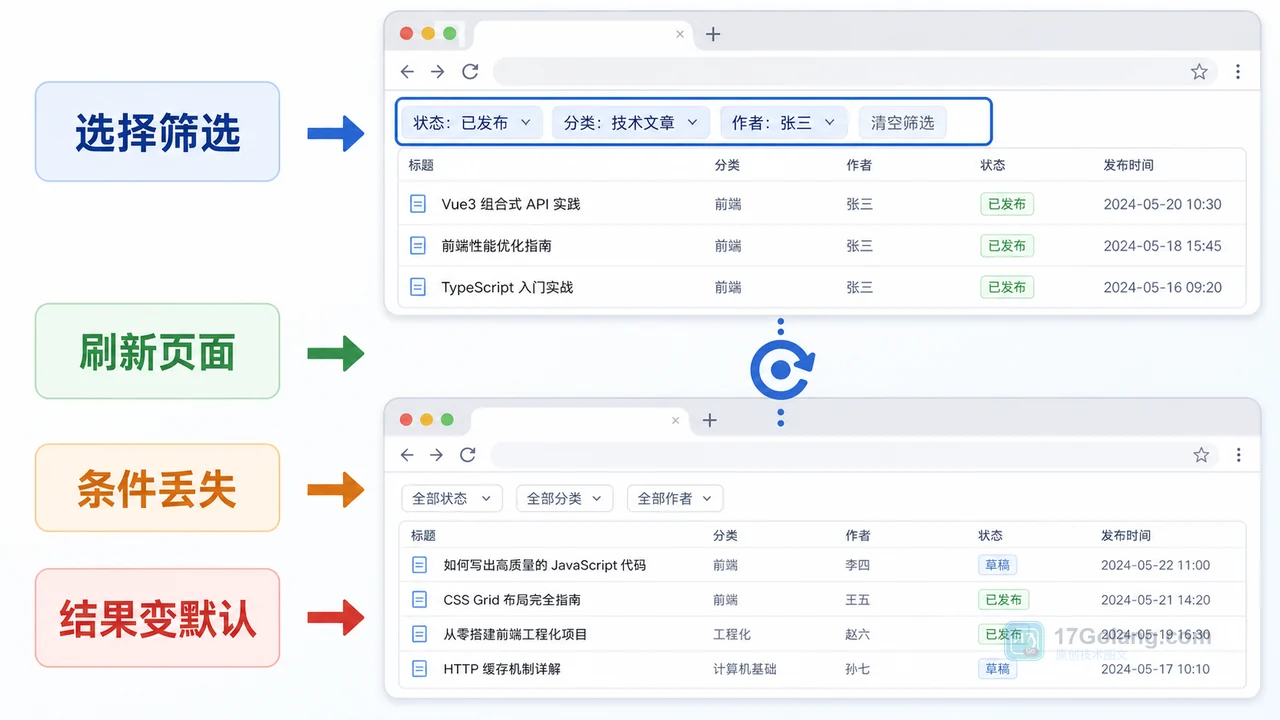
- 文章 · 前端 | 8小时前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏
-
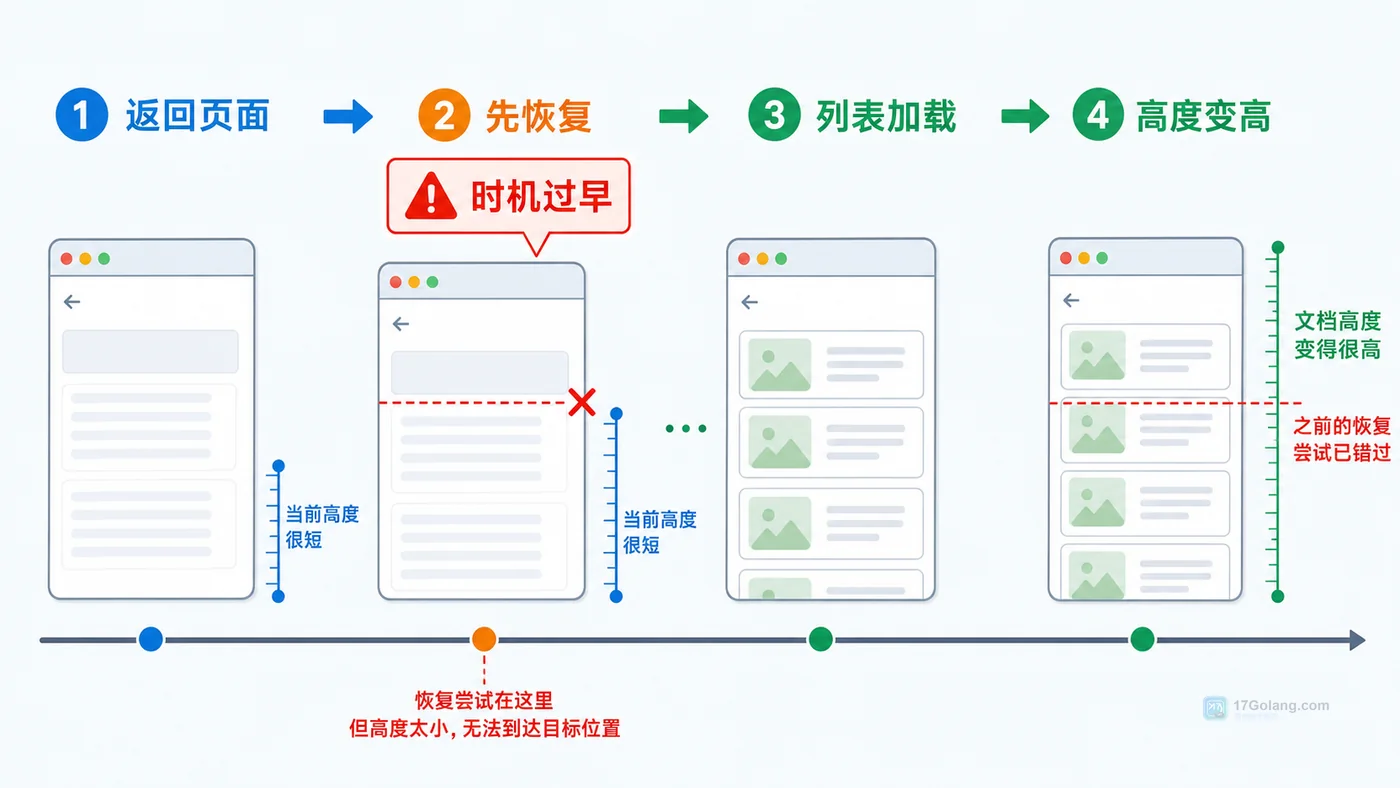
- 文章 · 前端 | 10小时前 | 前端 · 性能优化 · 路由 · javascript · 前端 用户体验 滚动位置 路由缓存 scrollRestoration
- 前端详情页返回列表丢失滚动位置怎么办:从复现到恢复一步步排查
- 458浏览 收藏
-
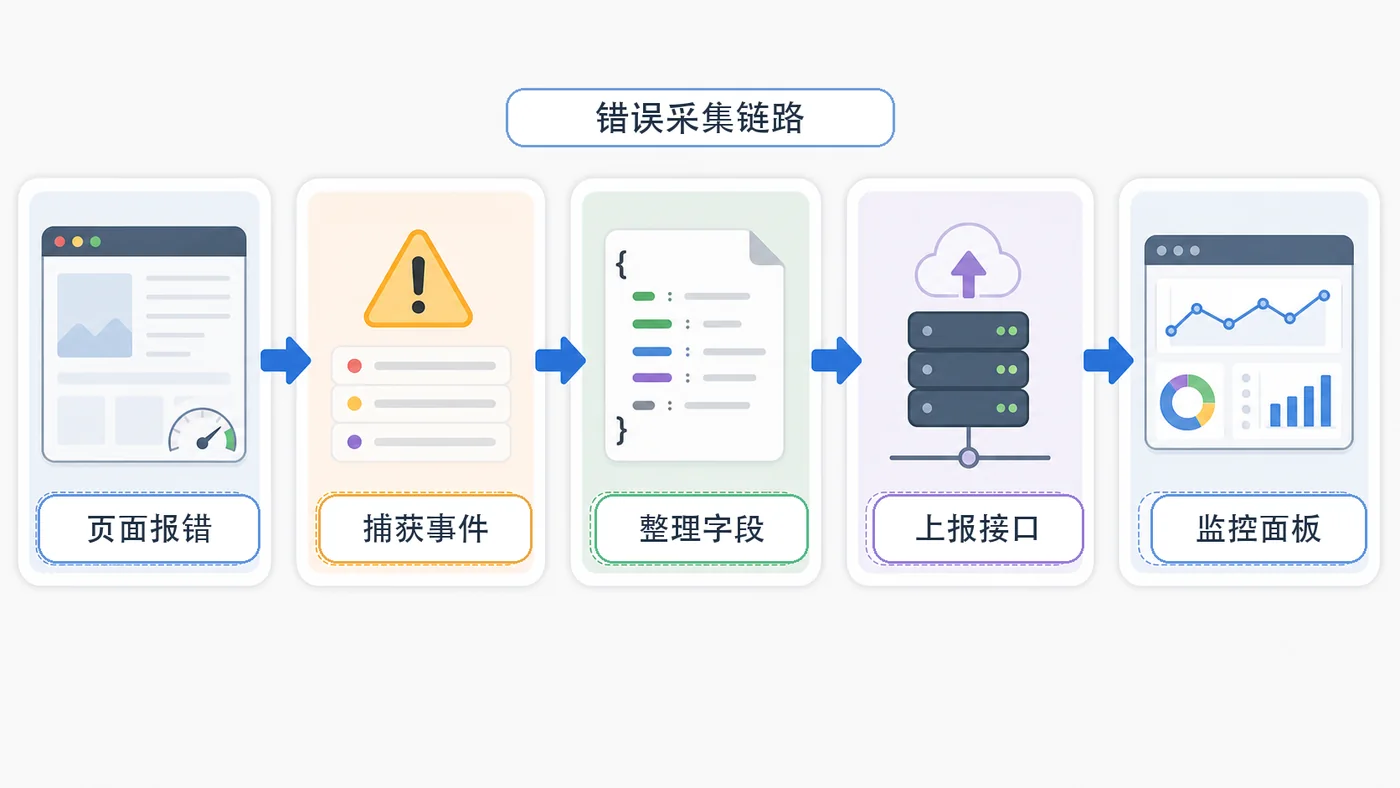
- 文章 · 前端 | 2天前 | 前端 · javascript · sourcemap · 错误监控 · 线上排查 · 前端 错误监控 告警 onerror sourcemap unhandledrejection
- 前端错误监控实战:onerror、unhandledrejection 和 sourcemap 定位问题
- 331浏览 收藏
-
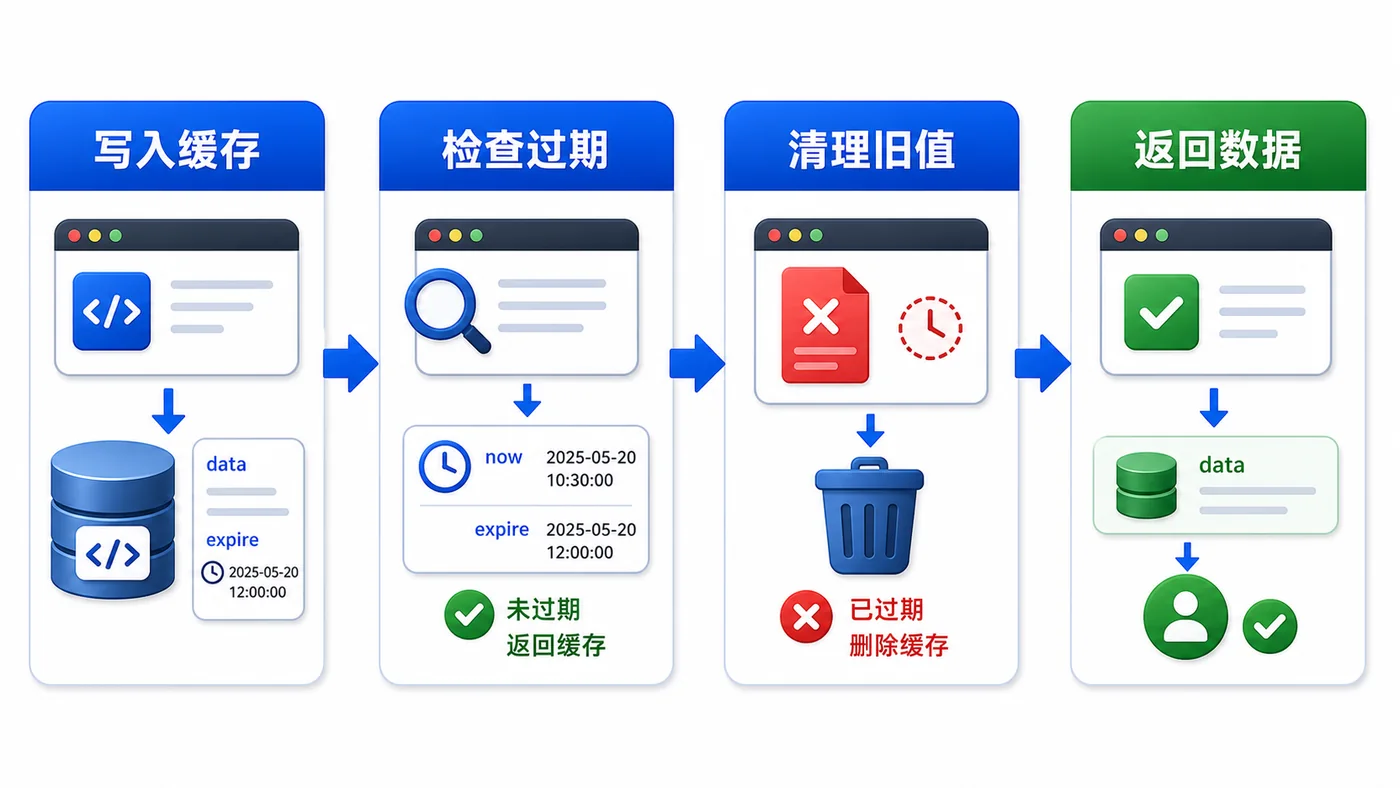
- 文章 · 前端 | 2天前 | 前端 · javascript · 缓存治理 · localStorage · Web性能 · 前端 本地缓存 localStorage 过期时间 版本迁移 异常兜底
- 前端 localStorage 缓存治理实战:过期时间、版本号和异常兜底
- 480浏览 收藏
-
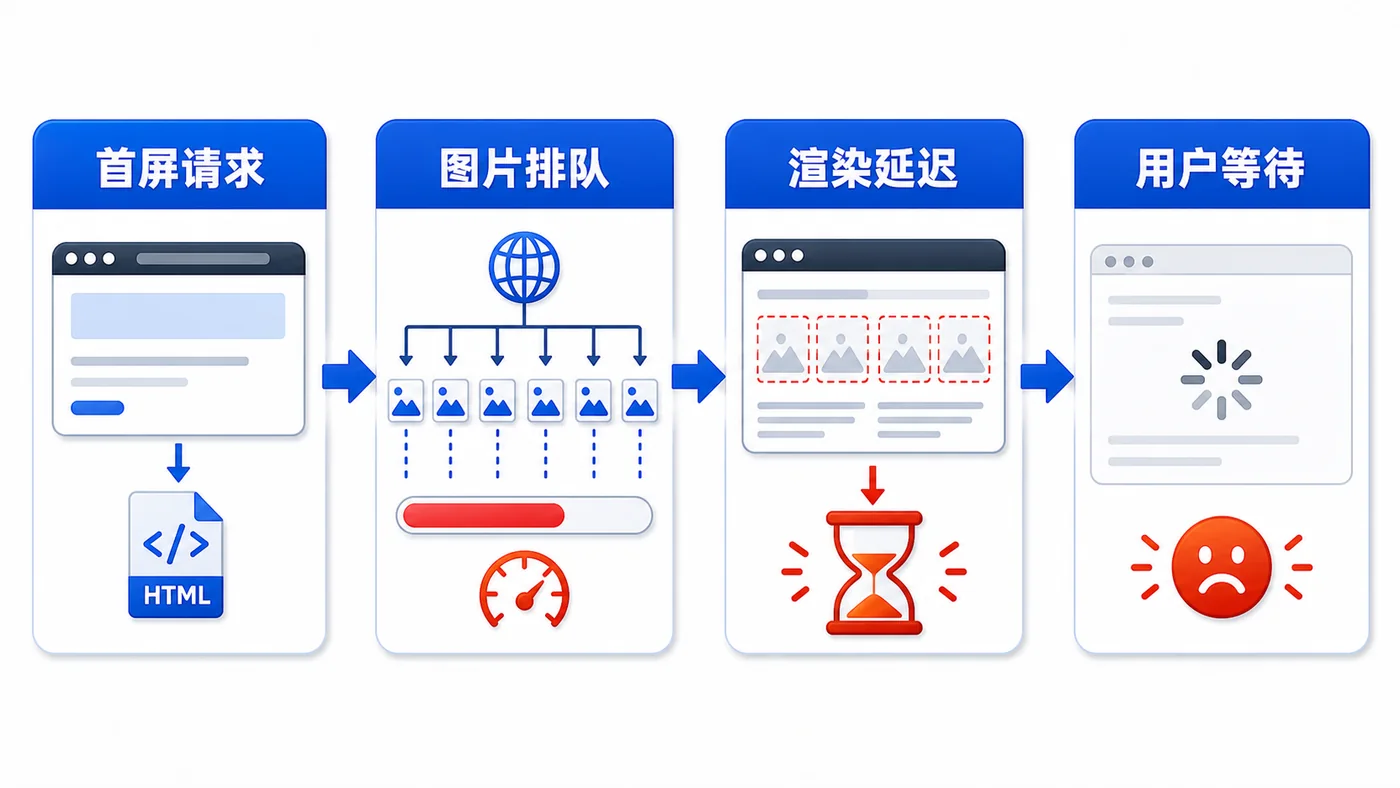
- 文章 · 前端 | 2天前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
- 前端图片懒加载实战:用 IntersectionObserver 降低首屏压力
- 184浏览 收藏
-
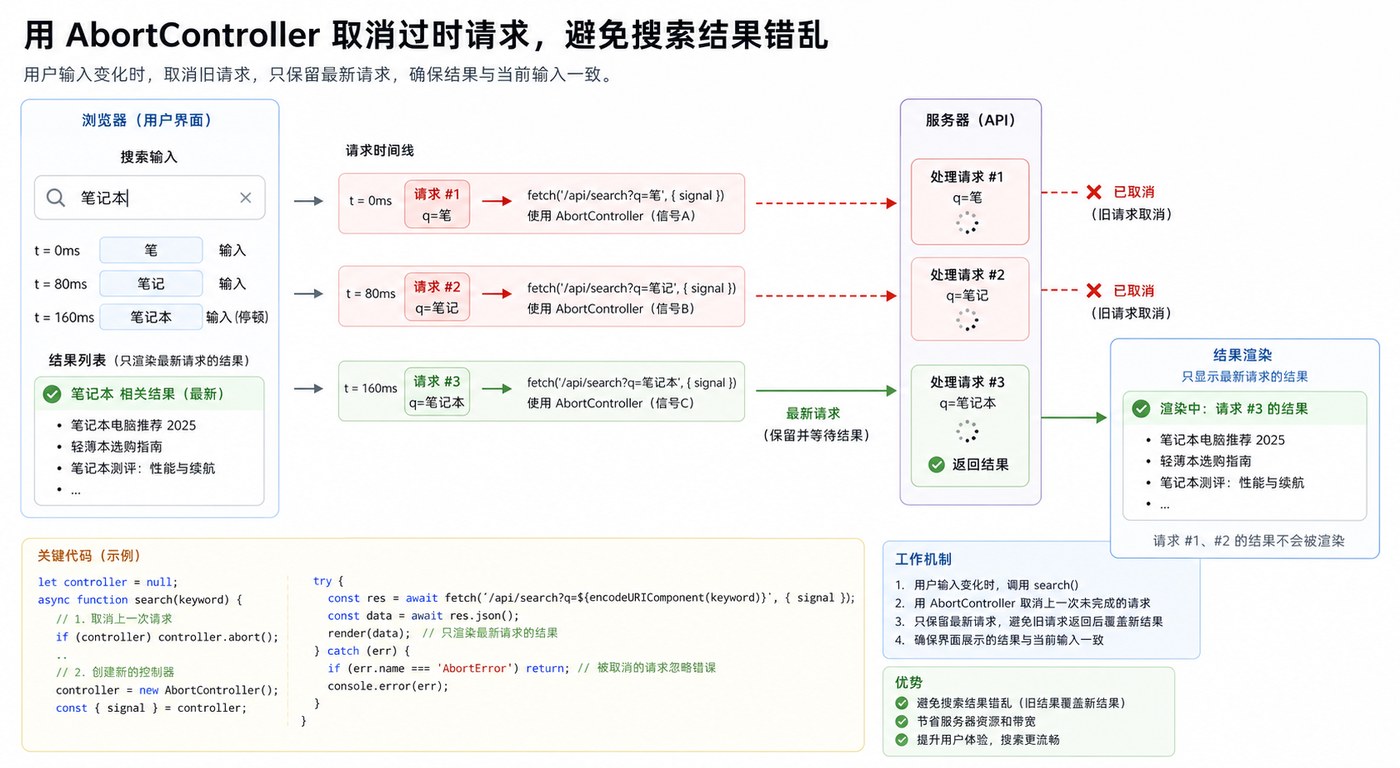
- 文章 · 前端 | 3天前 | 前端 · 性能优化 · javascript · fetch · 前端 搜索优化 Fetch AbortController 请求竞态
- 前端搜索竞态治理实战:用 AbortController 取消过期请求
- 178浏览 收藏
-
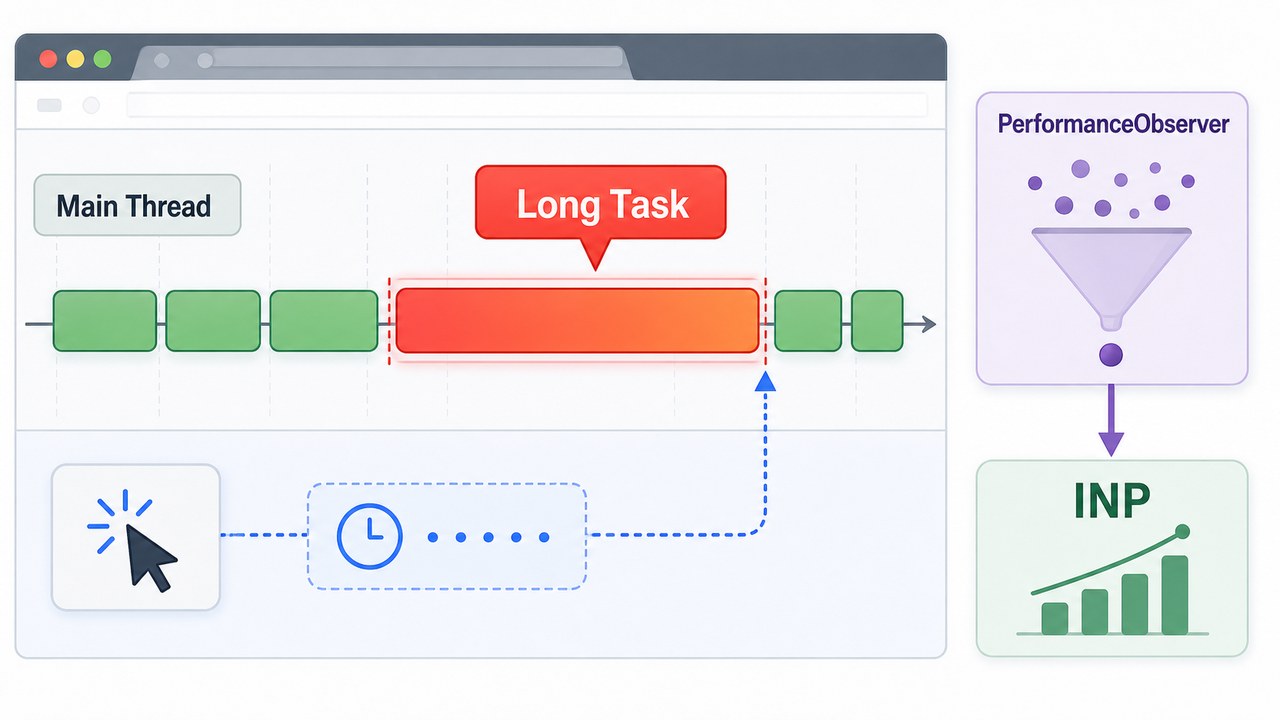
- 文章 · 前端 | 3天前 |
- 前端长任务治理实战:用 PerformanceObserver 找出页面卡顿源头
- 423浏览 收藏
-

- 文章 · 前端 | 2星期前 |
- CSS数字显示统一技巧,OpenType特性应用方法
- 209浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- Red Skill
- 小红书创作服务平台为小红书创作者和机构提供视频上传、数据分析、粉丝管理、创作指导等多项运营服务,助力用户解锁更多创作者专属功能,体验高效创作!
- 14次使用
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 104次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 130次使用
-

- MeloLab
- MeloLab 是一款 AI 音乐生成工具,可根据文本创意生成歌曲、人声、混音、分轨和背景音乐,适合创作者快速制作音乐素材。
- 113次使用
-
- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8769次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


