Pandas提取HTML表格超链接方法
本文揭秘了如何仅用 Pandas 就能高效、精准地从网页表格中提取指定列的超链接——无需 BeautifulSoup 等额外库,借助 `read_html` 的 `extract_links="body"` 参数将含链接单元格自动转为(文本,URL)元组,再通过列级解析与智能 URL 补全(支持相对路径自动拼接 base_url),轻松获得可直接访问的完整链接;方法既保证零依赖、高可控性,又兼顾鲁棒性与实用性,特别适合批量采集如体育赛事记分卡等结构化链接数据,是网页表格链接提取的简洁可靠首选方案。

本文详解如何利用 pandas.read_html 的 extract_links 参数配合数据清洗,从网页表格中精准提取超链接并构造完整 URL,避免依赖 BeautifulSoup,实现纯 Pandas 流程化网页结构化数据采集。
本文详解如何利用 pandas.read_html 的 extract_links 参数配合数据清洗,从网页表格中精准提取超链接并构造完整 URL,避免依赖 BeautifulSoup,实现纯 Pandas 流程化网页结构化数据采集。
在使用 pandas.read_html() 抓取网页表格时,若目标列包含 文本 形式的超链接(如 ESPNcricinfo 的“Scorecard”列),默认仅返回可见文本,丢失关键跳转信息。虽然 extract_links 参数支持提取链接,但其输出格式为 (text, href) 元组,且 href 多为相对路径或缺失协议,需进一步处理才能获得可用 URL。
核心解决方案:extract_links="body" + 列级元组解析 + 基础 URL 拼接
pandas.read_html(url, extract_links="body") 会将表格中所有 标签所在单元格替换为 (link_text, href) 元组(无链接则为 (text, None))。随后通过 apply() 对每列进行向量化处理,提取 href 并补全协议与域名:
import pandas as pd
url = 'https://www.espncricinfo.com/records/year/team-match-results/2005-2005/twenty20-internationals-3'
base_url = 'https://www.espncricinfo.com'
# 提取整表,所有含链接的单元格变为 (text, href) 元组
table = pd.read_html(url, extract_links="body")[0]
# 遍历每列,解包元组:取 href;若为 None 则保留原文本(极少发生);否则拼接 base_url
table = table.apply(
lambda col: [
v[1] if v[1] is not None else v[0] # 优先取 href,无链接时回退到文本
for v in col
]
)
# 若 href 为相对路径(如 "/series/xxx"),需手动补全
# 此处示例中 href 已含完整路径,但通用做法如下:
table = table.apply(
lambda col: [
f"{base_url}{v[1]}" if v[1] and v[1].startswith('/') else
v[1] if v[1] else v[0]
for v in col
]
)✅ 关键优势
- 零外部依赖:全程仅用 pandas,无需 BeautifulSoup 或 lxml;
- 列粒度可控:extract_links="body" 作用于全部数据单元格,后续可对特定列(如 "Scorecard")单独处理,避免污染其他列;
- URL 可靠性高:显式拼接 base_url 确保链接可直接访问,规避相对路径失效风险。
⚠️ 注意事项
- extract_links 不支持按列指定(如仅提取第5列链接),需全表提取后筛选列处理;
- 部分网站 href 为绝对 URL(含 https://),部分为根相对路径(/path)或页面相对路径(./path),建议统一用 urllib.parse.urljoin(base_url, href) 安全拼接;
- 若表格含多层嵌套 或 JavaScript 渲染链接,read_html 无法解析,此时必须切换至 Selenium 或 Playwright。
进阶技巧:仅处理目标列,提升效率与安全性
若只需 "Scorecard" 列的链接,可先提取该列再处理,避免遍历无关列:
scorecard_col = table.iloc[:, -1] # 假设 Scorecard 是最后一列
scorecard_links = [
f"{base_url}{v[1]}" if v[1] else None
for v in scorecard_col
]
table["Scorecard_URL"] = scorecard_links
table = table.drop(columns=[table.columns[-1]]) # 删除原始文本列至此,你已获得一个结构清晰、链接可用的 Pandas DataFrame,可直接用于后续分析、存储或批量请求详情页。这一方法平衡了简洁性与鲁棒性,是动态网页静态表格链接提取的推荐实践。
今天关于《Pandas提取HTML表格超链接方法》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
 Java异常统一返回格式规范
Java异常统一返回格式规范
- 上一篇
- Java异常统一返回格式规范

- 下一篇
- Linux图形界面安装教程:GNOME/KDE入门指南
-

- 文章 · 前端 | 14小时前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
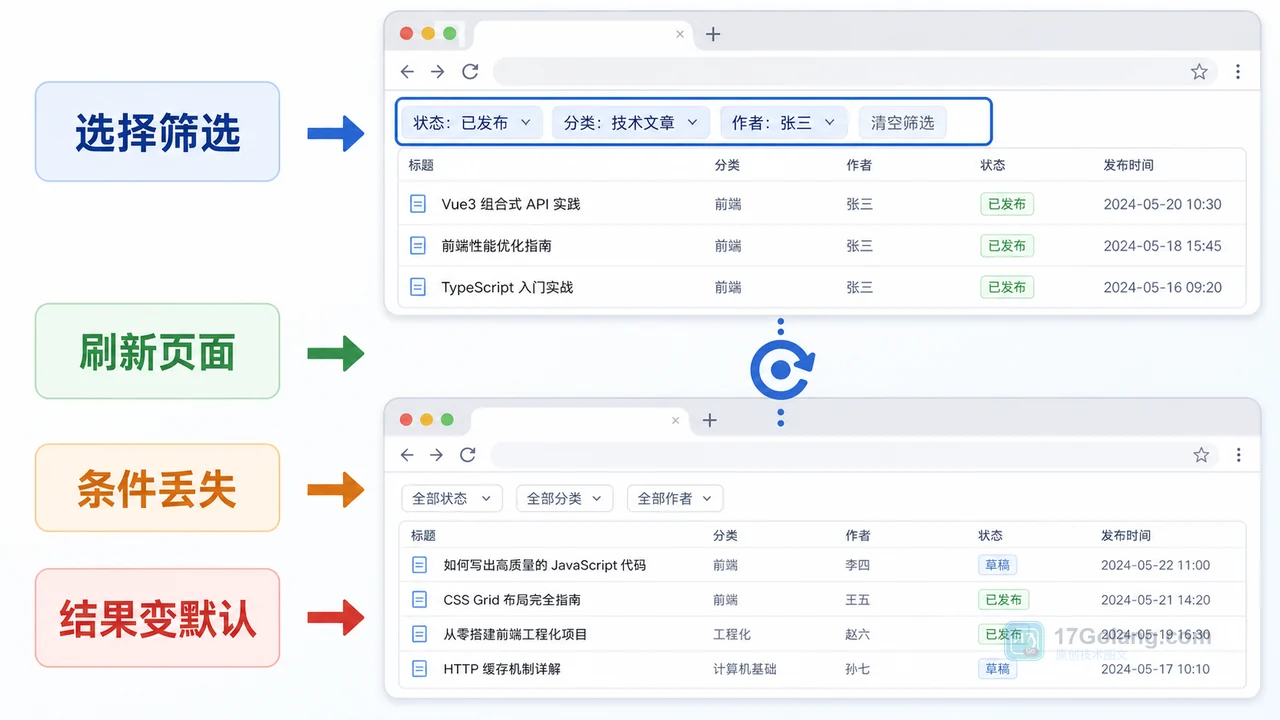
- 文章 · 前端 | 14小时前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏
-
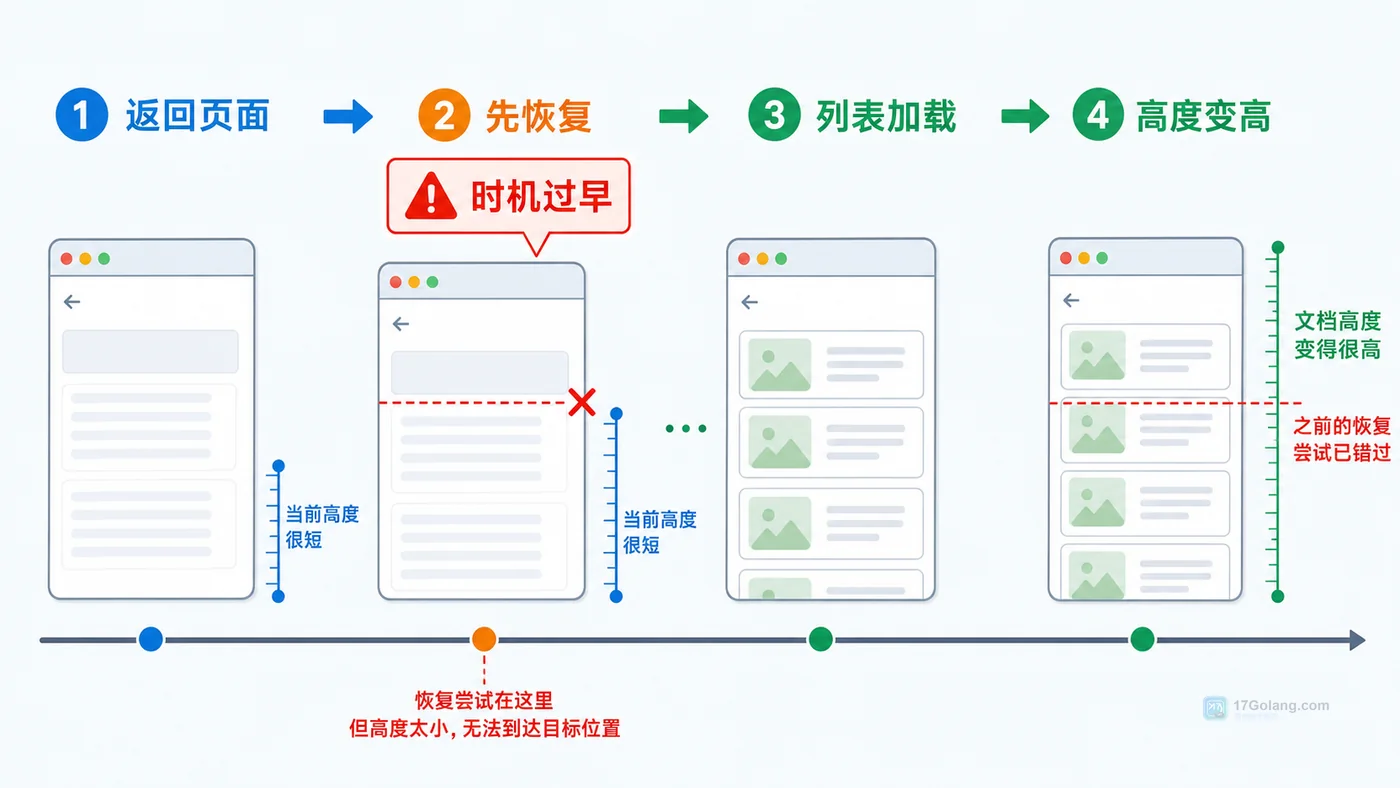
- 文章 · 前端 | 16小时前 | 前端 · 性能优化 · 路由 · javascript · 前端 用户体验 滚动位置 路由缓存 scrollRestoration
- 前端详情页返回列表丢失滚动位置怎么办:从复现到恢复一步步排查
- 458浏览 收藏
-
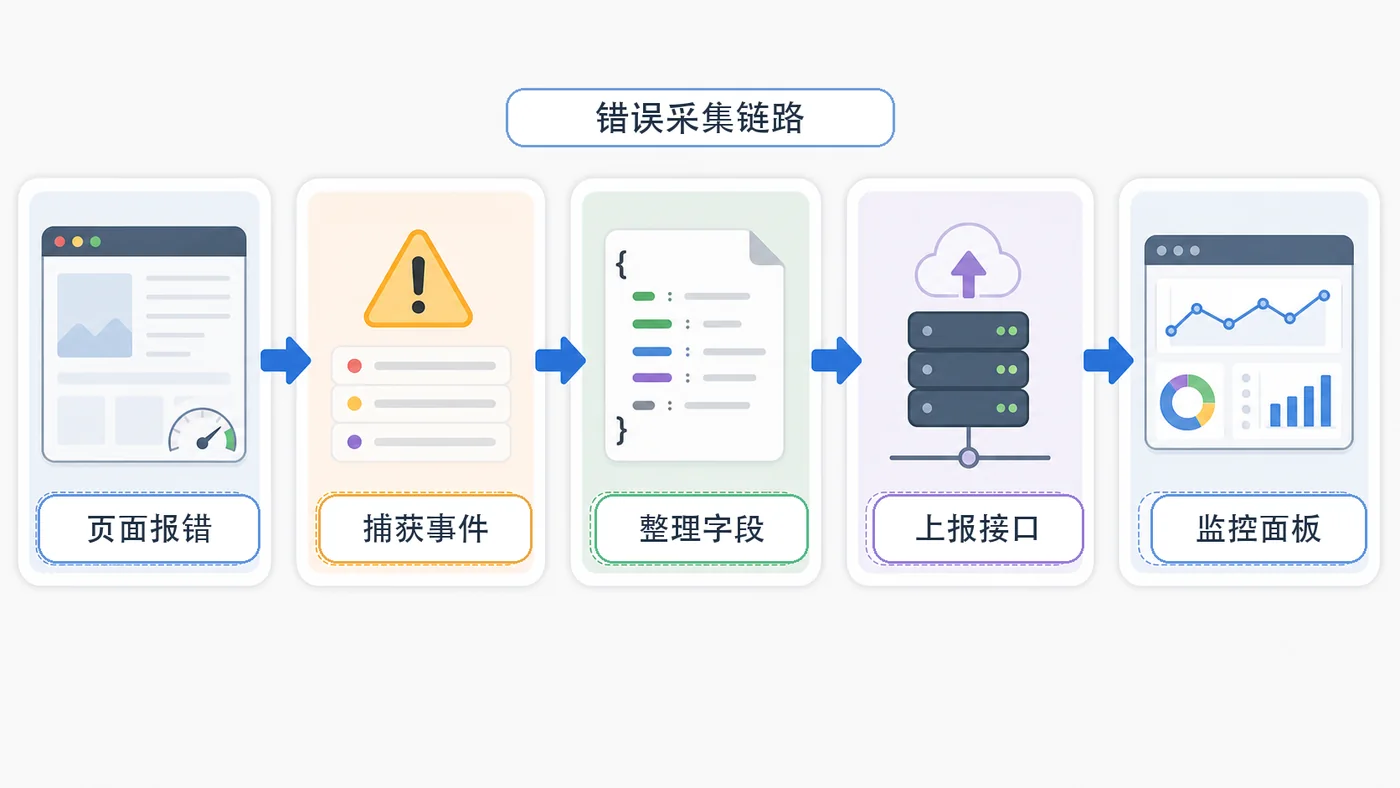
- 文章 · 前端 | 2天前 | 前端 · javascript · sourcemap · 错误监控 · 线上排查 · 前端 错误监控 告警 onerror sourcemap unhandledrejection
- 前端错误监控实战:onerror、unhandledrejection 和 sourcemap 定位问题
- 331浏览 收藏
-
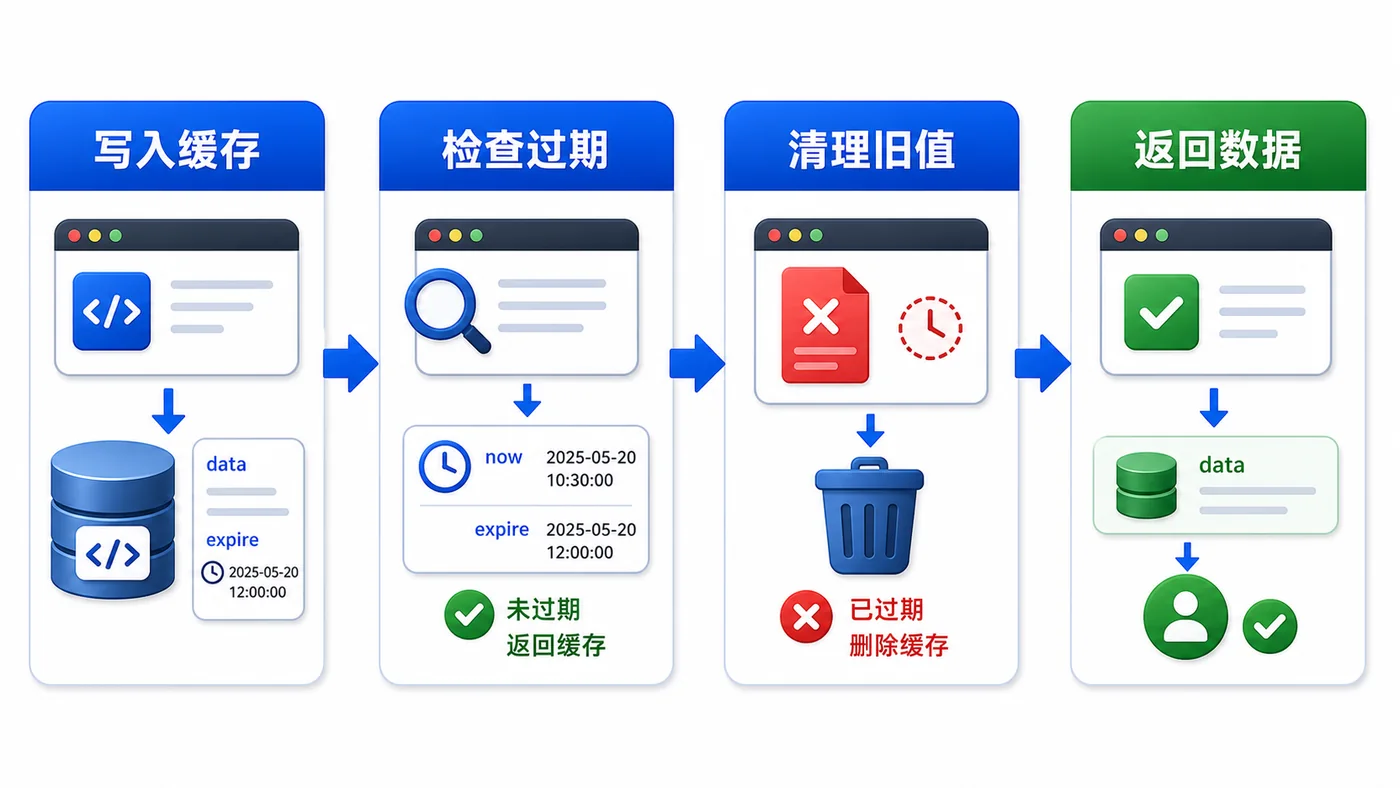
- 文章 · 前端 | 2天前 | 前端 · javascript · 缓存治理 · localStorage · Web性能 · 前端 本地缓存 localStorage 过期时间 版本迁移 异常兜底
- 前端 localStorage 缓存治理实战:过期时间、版本号和异常兜底
- 480浏览 收藏
-
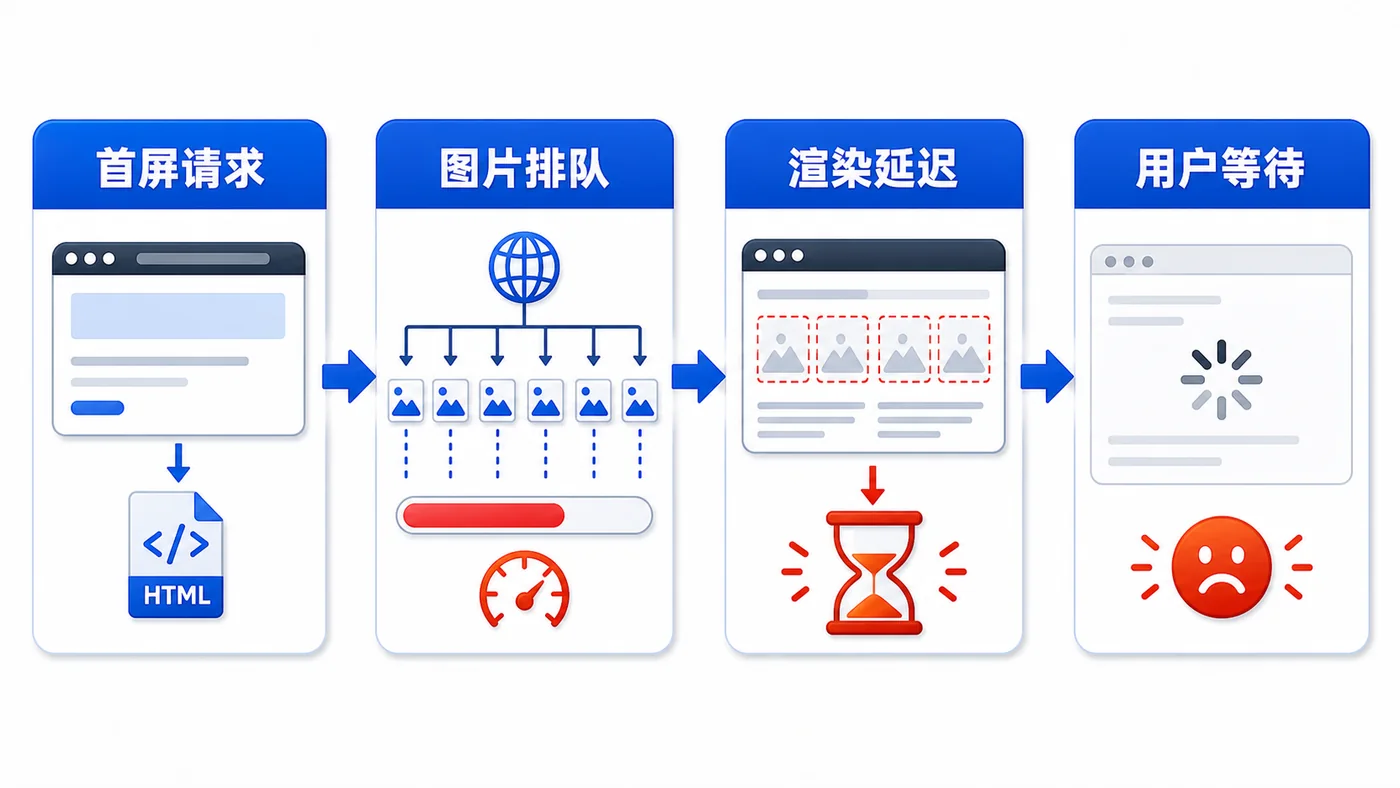
- 文章 · 前端 | 2天前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
- 前端图片懒加载实战:用 IntersectionObserver 降低首屏压力
- 184浏览 收藏
-
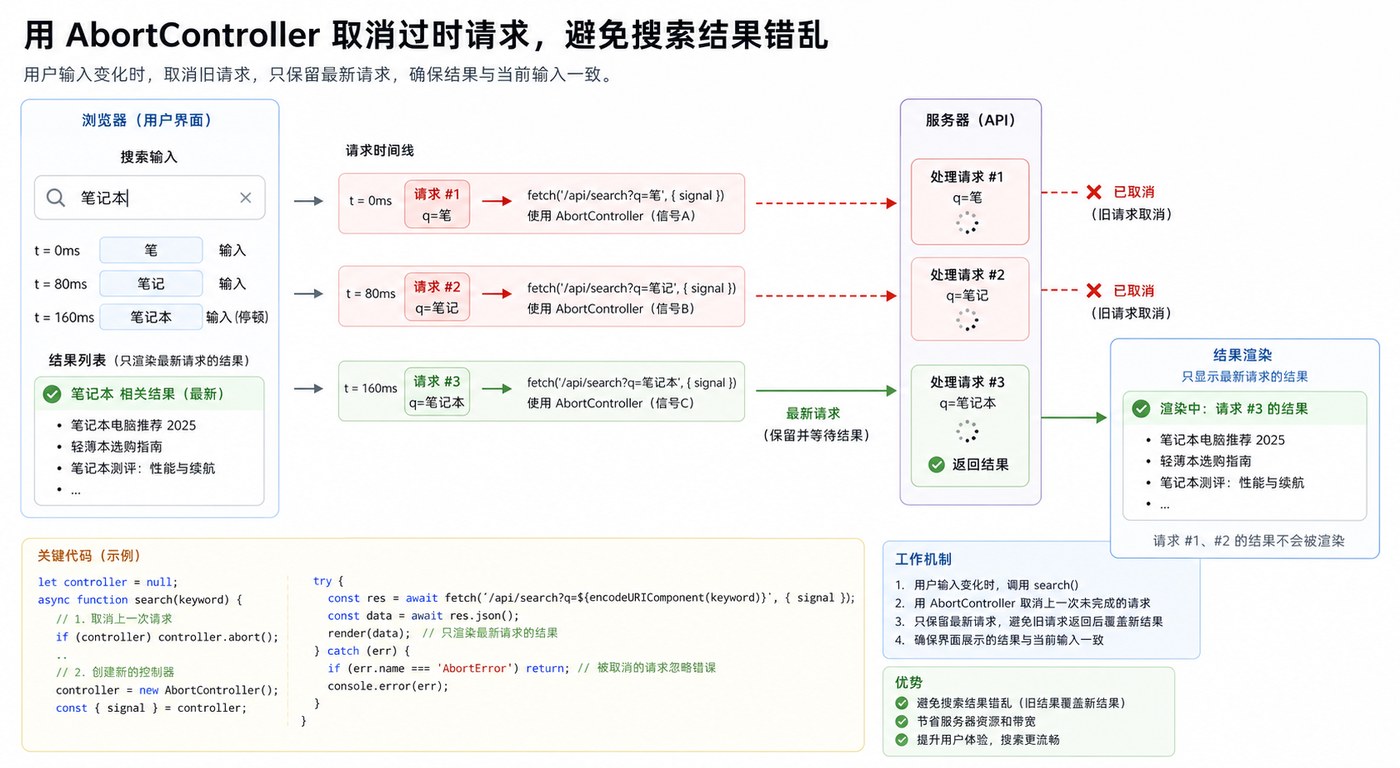
- 文章 · 前端 | 3天前 | 前端 · 性能优化 · javascript · fetch · 前端 搜索优化 Fetch AbortController 请求竞态
- 前端搜索竞态治理实战:用 AbortController 取消过期请求
- 178浏览 收藏
-
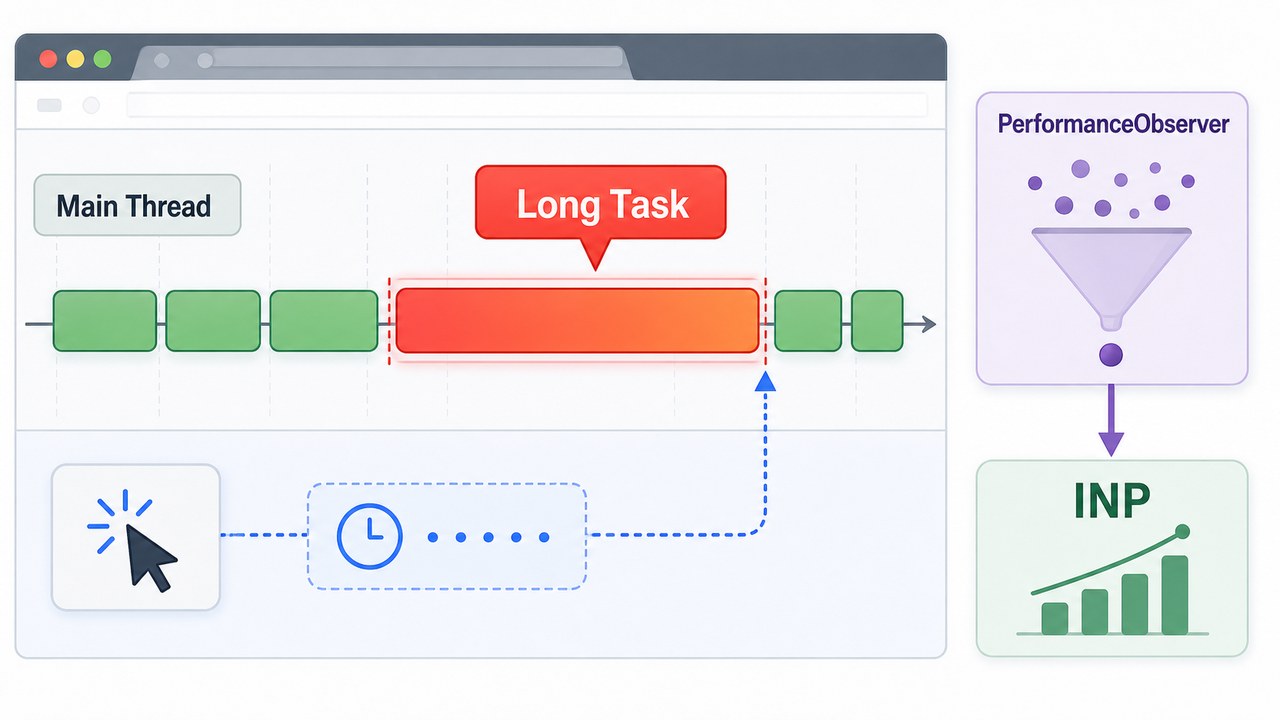
- 文章 · 前端 | 3天前 |
- 前端长任务治理实战:用 PerformanceObserver 找出页面卡顿源头
- 423浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 89次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 93次使用
-

- Red Skill
- 小红书创作服务平台为小红书创作者和机构提供视频上传、数据分析、粉丝管理、创作指导等多项运营服务,助力用户解锁更多创作者专属功能,体验高效创作!
- 94次使用
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 195次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 221次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


