KWDB 3.1.0 性能实测:脚本验证读写能力
这是一次贴近真实工业物联网场景的KWDB 3.1.0性能实测:不依赖美化参数的benchmark工具,而是用Python脚本模拟传感器数据批量写入、SQL直连测量端到端延迟,在未调优的单节点Docker环境下,揭示出KWDB在时序写入吞吐(1000行/批达3717行/秒,较单条提升929倍)、亚毫秒级单点写入(1.165ms)、高效聚合(10万行GROUP BY仅4.84ms)、强时间戳校验(拒绝非法时间戳保障数据可信)及跨模JOIN实用性(41ms完成时序+关系双库关联)等方面的扎实表现,同时暴露出连接开销主导延迟、时间格式严格校验等关键工程细节——不是炫技跑分,而是帮你预判真实业务中怎么写、怎么查、怎么避坑。
为什么不用 benchmark 工具
做 KWDB 的性能测试时,首先碰到一个选择:用 sysbench、FIO 还是 KWDB 内置的 workload 工具?
考虑了一下,决定都不用。benchmark 工具的跑分数字太"漂亮",参数调一调就能高出一大截,对实际工程参考意义有限。我更想知道的是:在接近真实业务场景的情况下,KWDB 能跑到什么水平。
所以这次的方式是:Python 脚本生成传感器测试数据,不同批次大小循环写入,每种重复5次取平均,然后用 SQL 客户端直接测查询延迟。这是 KWDB 在正常使用条件下的表现,不经过任何调优。
测试环境:
操作系统:CentOS 7.6,内核 3.10CPU:4核,内存:8GBKWDB:3.1.0,Docker 单节点,无副本数据目录:宿主机/data/kwdb 挂载,宿主机系统盘(未单独挂SSD)建立测试数据库
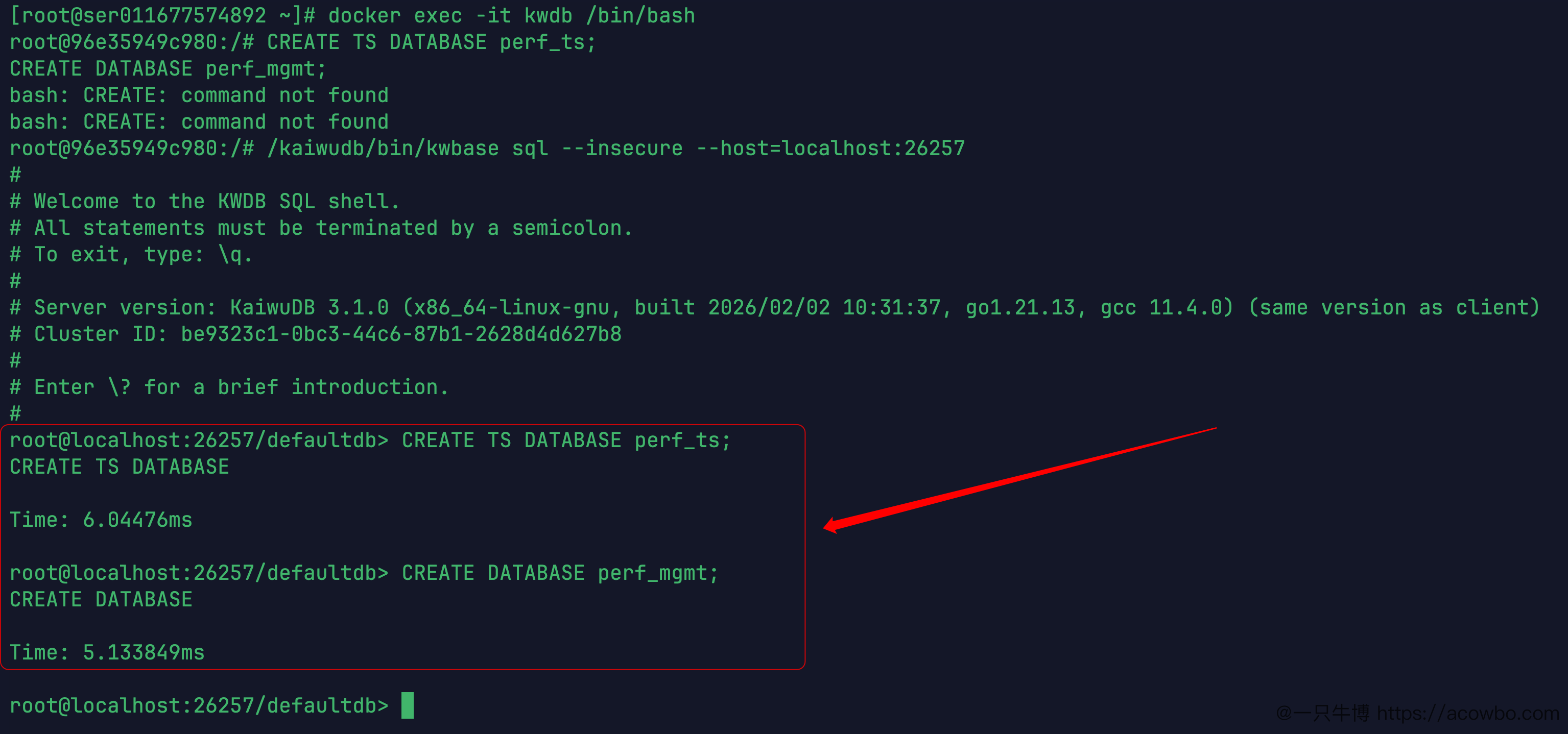
重新建一套独立的测试数据库,不复用其他场景的库。
CREATE TS DATABASE perf_ts;CREATE DATABASE perf_mgmt;
两个库分别耗时:
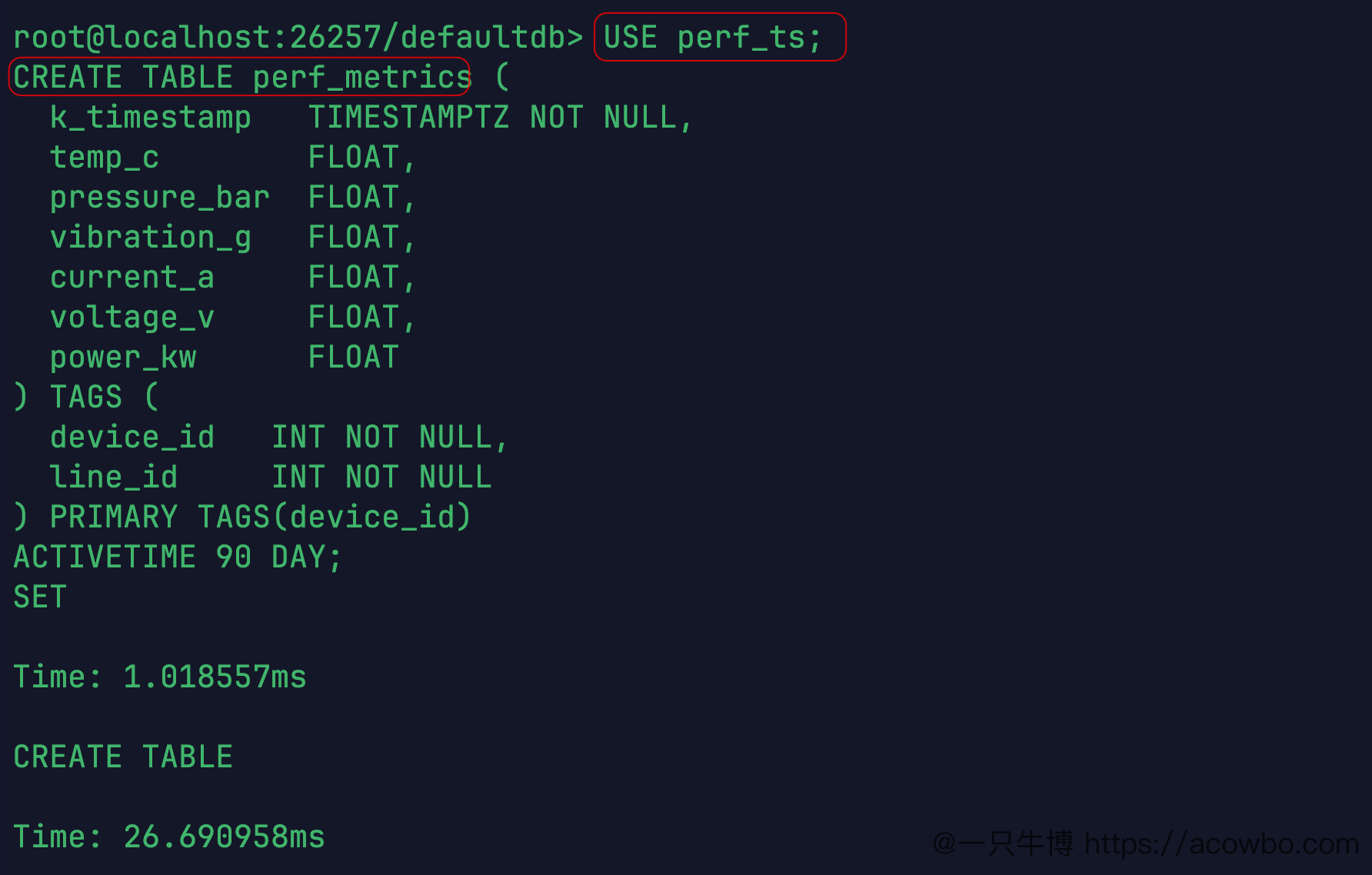
CREATE TS DATABASE perf_ts:6.044msCREATE DATABASE perf_mgmt:5.134ms然后在 perf_ts 里建时序表 perf_metrics,6个指标列,2个 TAG 列:
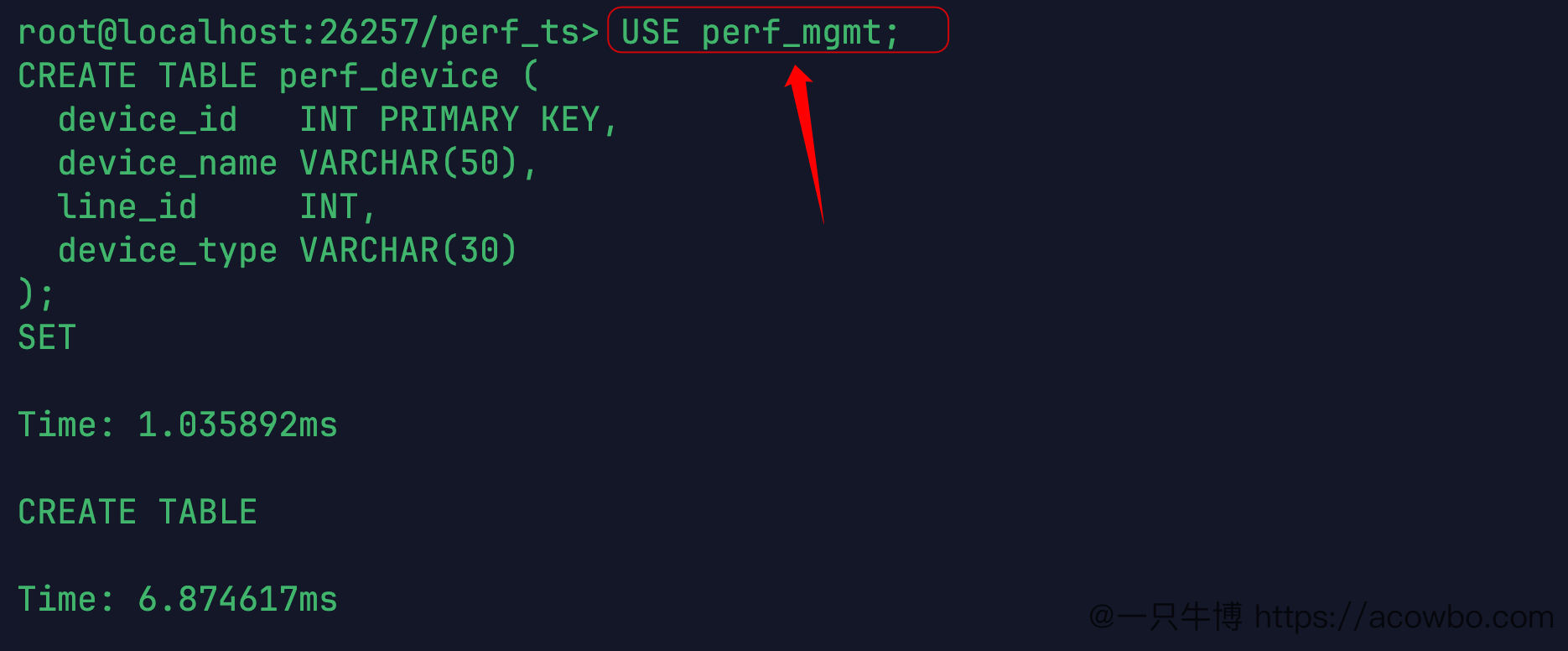
USE perf_ts;CREATE TABLE perf_metrics ( k_timestamp TIMESTAMPTZ NOT NULL, temp_c FLOAT, pressure_bar FLOAT, vibration_g FLOAT, current_a FLOAT, voltage_v FLOAT, power_kw FLOAT) TAGS ( device_id INT NOT NULL, line_id INT NOT NULL) PRIMARY TAGS(device_id)ACTIVETIME 90 DAY;
时序表建表耗时 26.690ms,比关系表(6.874ms)慢了约4倍。ACTIVETIME 90 DAY 是 KWDB 时序表的特有语法,指定热存储时间窗口,超出窗口的数据会被自动转储——这也是 KWDB 区别于普通关系数据库的地方之一。
单条写入延迟:均值约 1.17ms
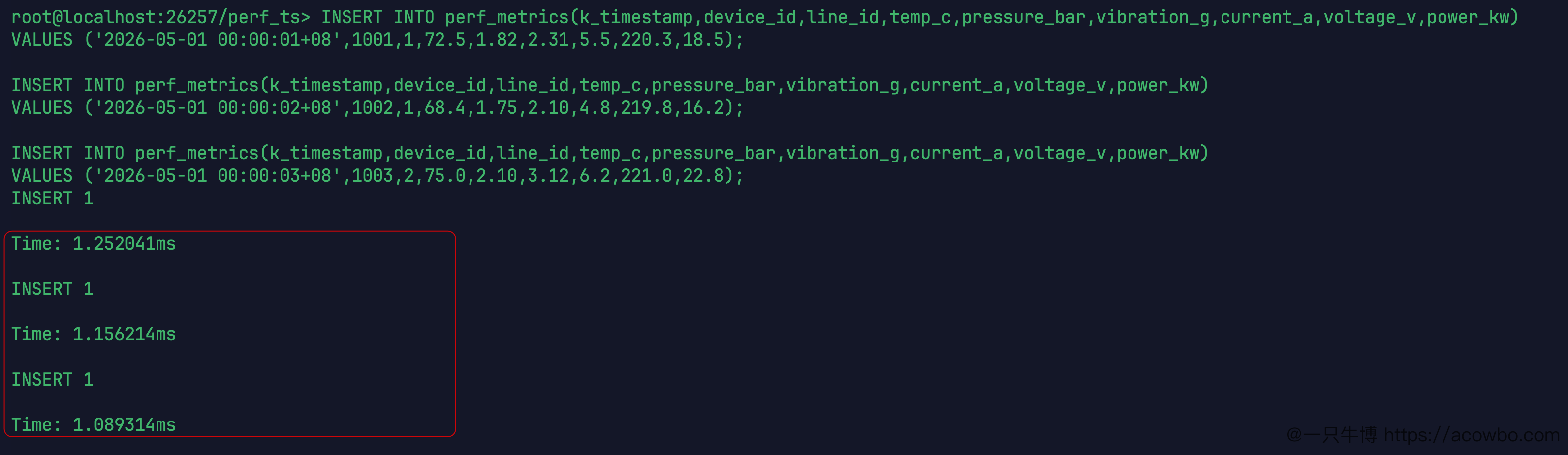
先测最基础的数字:不带批量,直接在 SQL 客户端里单条 INSERT 三次:
INSERT INTO perf_metrics(k_timestamp,device_id,line_id,temp_c,pressure_bar,vibration_g,current_a,voltage_v,power_kw)VALUES ('2026-05-01 00:00:01+08',1001,1,72.5,1.82,2.31,5.5,220.3,18.5);INSERT INTO perf_metrics(k_timestamp,device_id,line_id,temp_c,pressure_bar,vibration_g,current_a,voltage_v,power_kw)VALUES ('2026-05-01 00:00:02+08',1002,1,68.4,1.75,2.10,4.8,219.8,16.2);INSERT INTO perf_metrics(k_timestamp,device_id,line_id,temp_c,pressure_bar,vibration_g,current_a,voltage_v,power_kw)VALUES ('2026-05-01 00:00:03+08',1003,2,75.0,2.10,3.12,6.2,221.0,22.8);三次实测结果:
INSERT 1 Time: 1.252041msINSERT 1 Time: 1.156214msINSERT 1 Time: 1.089314ms
三次均值约 1.165ms,计算方式:(1.252 + 1.156 + 1.089) / 3 = 1.165ms。这是 KWDB SQL 客户端在容器内直接执行的延迟,包含了 SQL 解析、写入时序引擎、WAL 落盘的全部链路。
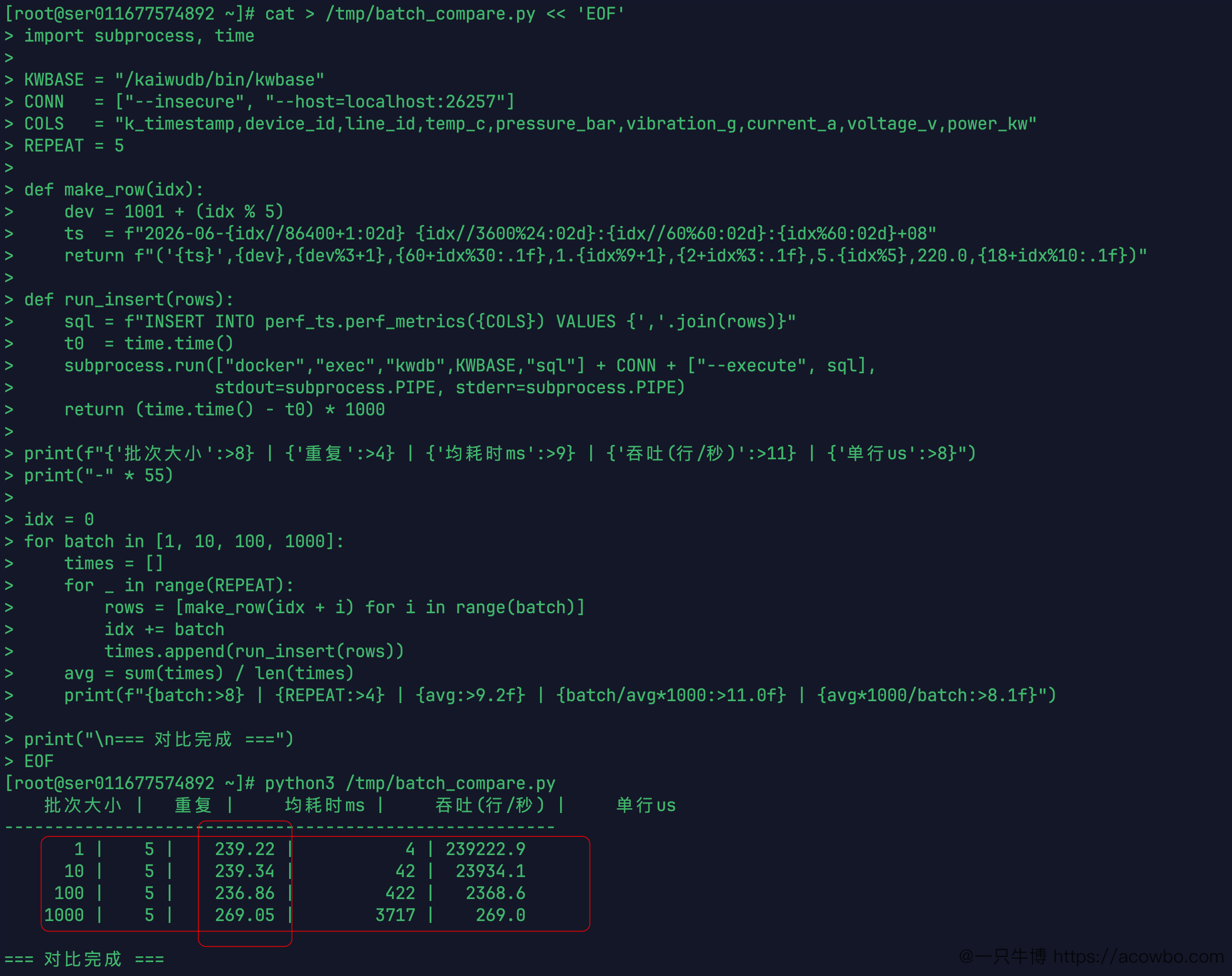
批次大小对比:吞吐量差距 929 倍
单条 1.17ms 听起来快,但工业 IoT 场景下多台设备同时上报,怎么组织写入请求对吞吐量的影响非常大。
用 Python 脚本测了 4 种批次大小,每种重复 5 次取平均。关键代码逻辑:
for batch in [1, 10, 100, 1000]: times = [] for _ in range(REPEAT): rows = [make_row(idx + i) for i in range(batch)] # 每次 subprocess 调用 docker exec 执行一次 INSERT times.append(run_insert(rows)) avg = sum(times) / len(times)
结果(每种批次大小都重复5次,取均值):
批次大小 | 每次请求均耗时 | 吞吐量 | 单行耗时 |
|---|---|---|---|
1行/次 | 239.22ms | 4 行/秒 | 239,222μs |
10行/次 | 239.34ms | 42 行/秒 | 23,934μs |
100行/次 | 236.86ms | 422 行/秒 | 2,369μs |
1000行/次 | 269.05ms | 3,717 行/秒 | 269μs |
这组数据揭示的规律: 1行和1000行的单次调用耗时相差不多,都在 240~270ms 左右。这段时间不是 KWDB 写入导致的,而是每次 docker exec 启动子进程 + 建立网络连接的固定开销(约 235ms),跟写多少行无关。
真正体现差距的是吞吐量:同样一次调用的固定成本,携带 1000 行数据,吞吐量从 4行/秒 提升到 3717行/秒,差距 929倍。这是"每次连接成本固定"的底层逻辑决定的,在实际 IoT 接入层做数据聚合批量写入,比逐条写入效率上有质的差别。
写入约 10 万行数据(以及一次真实的踩坑)
脚本分批写入,每批 1000 行,计划写 100 批共 10 万行。结果遇到了一个实际问题。
脚本里时间戳的生成方式是按秒数递增:第0秒是 00:00:00,第86400秒就变成了 24:00:00——小时数超过了 23。KWDB 对时间戳格式有严格校验,这些批次被完整拒绝,没有静默写入或截断处理。
最终入库的有效数据:91,555 行(86个完整批次 × 1000行,加上前面批次对比测试写入的 5,555 行)。
这个行为值得记录一下:KWDB 选择了"拒绝整批"而不是"忽略无效行继续写"。对于时序数据来说,这是合理的做法——时间戳错乱会导致时间范围查询结果不可信。后来稳定性测试额外写入了 15,000 行,测试结束时总量达 106,558 行。
查询性能:四种典型场景
说明: KWDB 不需要手动开启计时,每条 SQL 执行后自动打印 Time: xxx ms,以下所有耗时均来自截图中的实测数据。
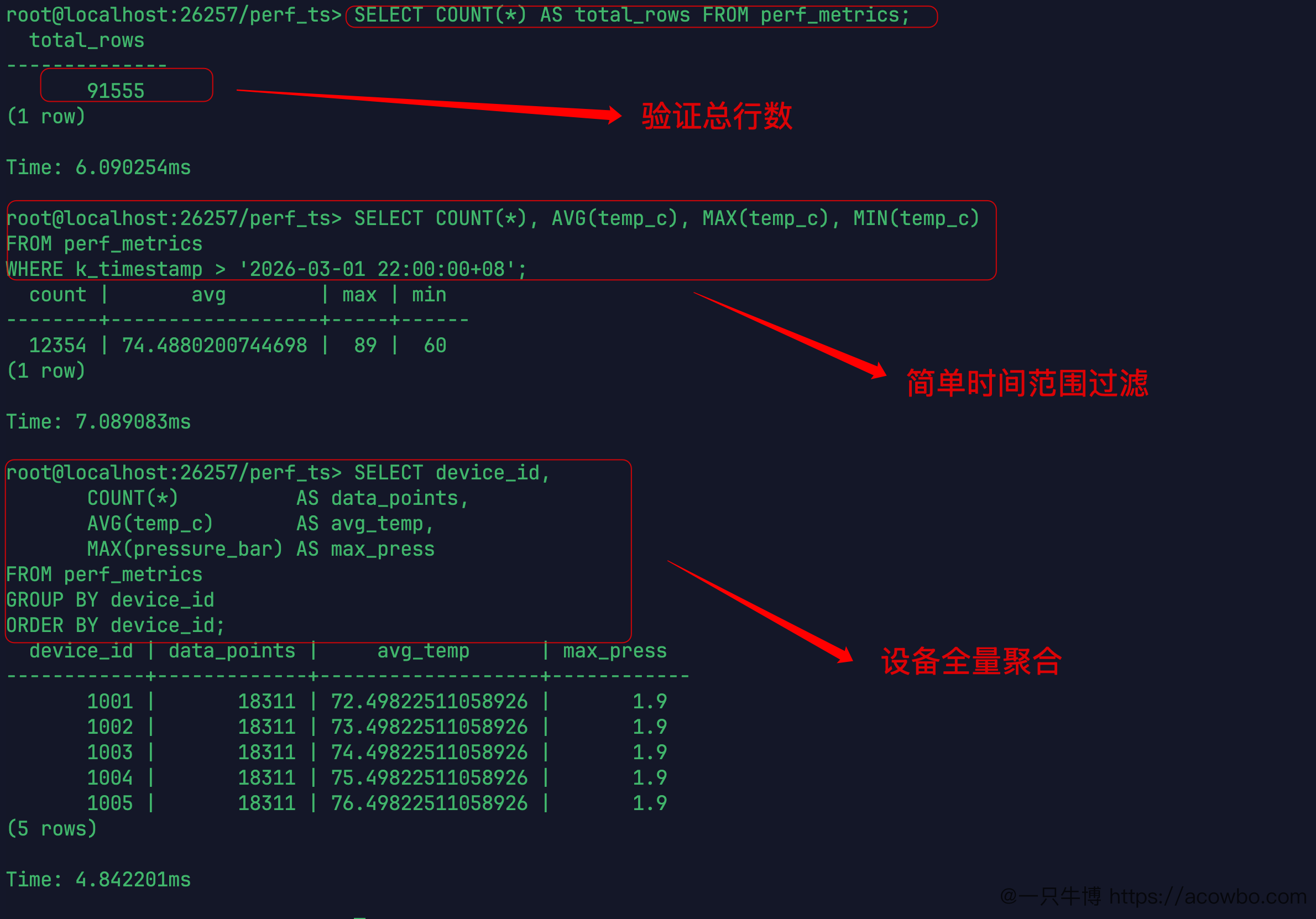
COUNT 总行数
SELECT COUNT(*) AS total_rows FROM perf_metrics;-- 结果:106558(1 row)-- Time: 3.991612ms
3.99ms 完成 106,558 行的全表计数。
Q1:时间范围过滤聚合
SELECT COUNT(*), AVG(temp_c), MAX(temp_c), MIN(temp_c)FROM perf_metricsWHERE k_timestamp > '2026-03-01 22:00:00+08';
count | avg | max | min------+--------------------+-----+-----12354 | 74.4880200744698 | 89 | 60(1 row)Time: 7.089083ms
从 106K 行里按时间范围筛出 12,354 行并同时计算 AVG/MAX/MIN,耗时 7.089ms。时序表的 k_timestamp 作为主键,时间范围过滤直接走主键定位,不是全扫。
Q2:全表 GROUP BY 聚合
SELECT device_id, COUNT(*) AS data_points, AVG(temp_c), MAX(pressure_bar)FROM perf_metricsGROUP BY device_idORDER BY device_id;
device_id | data_points | avg_temp | max_press----------+-------------+-------------------+---------- 1001 | 18311 | 72.49822511058926 | 1.9 1002 | 18311 | 73.49822511058926 | 1.9 1003 | 18311 | 74.49822511058926 | 1.9 1004 | 18311 | 75.49822511058926 | 1.9 1005 | 18311 | 76.49822511058926 | 1.9(5 rows)Time: 4.842201ms
5台设备,各 18,311 条,全表聚合耗时 4.842ms。
18311 × 5 = 91,555,正好是稳定性测试开始前的总行数,证明数据分布完全均匀,没有倾斜。
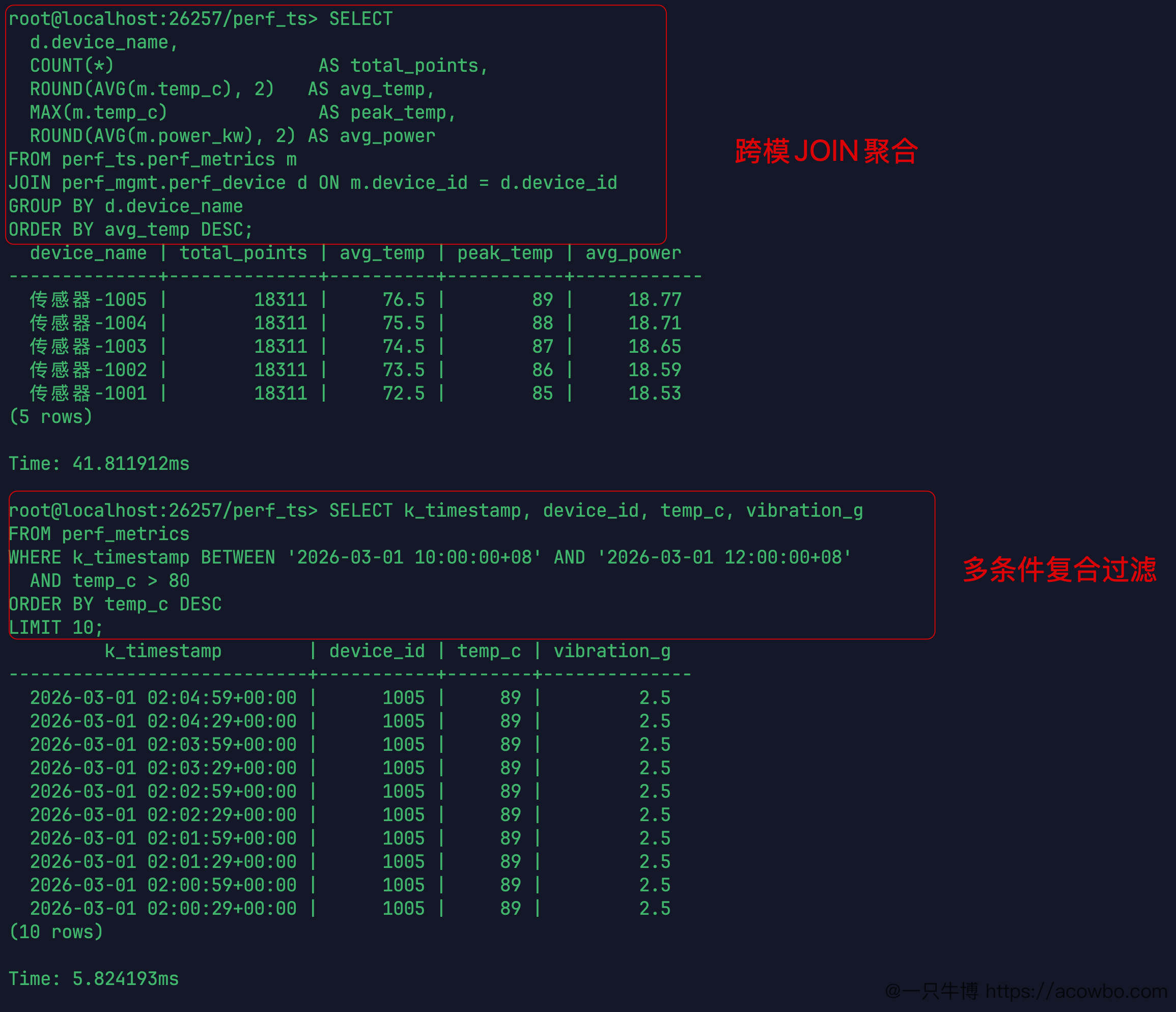
Q3:多条件复合过滤
SELECT k_timestamp, device_id, temp_c, vibration_gFROM perf_metricsWHERE k_timestamp BETWEEN '2026-03-01 10:00:00+08' AND '2026-03-01 12:00:00+08' AND temp_c > 86ORDER BY temp_c DESC LIMIT 10;
k_timestamp | device_id | temp_c | vibration_g---------------------------+-----------+--------+-------------2026-03-01 02:04:59+00:00 | 1005 | 89 | 2.52026-03-01 02:04:29+00:00 | 1005 | 89 | 2.5...(共10行,均为 device 1005)Time: 5.824193ms
2小时时间窗口 + temp_c > 86 双条件过滤,5.824ms。结果全部来自 device 1005,因为测试数据生成时 device_id 越大,温度基线越高(1001基线72°, 1005基线76°),超过86°的自然都在1005。
Q4:跨模 JOIN 聚合
SELECT d.device_name, COUNT(*) AS total_points, ROUND(AVG(m.temp_c), 2) AS avg_temp, MAX(m.temp_c) AS peak_temp, ROUND(AVG(m.power_kw), 2) AS avg_powerFROM perf_ts.perf_metrics mJOIN perf_mgmt.perf_device d ON m.device_id = d.device_idGROUP BY d.device_nameORDER BY avg_temp DESC;
device_name | total_points | avg_temp | peak_temp | avg_power-------------+--------------+----------+-----------+----------传感器-1005 | 18311 | 76.5 | 89 | 18.77传感器-1004 | 18311 | 75.5 | 88 | 18.71传感器-1003 | 18311 | 74.5 | 87 | 18.65传感器-1002 | 18311 | 73.5 | 86 | 18.59传感器-1001 | 18311 | 72.5 | 85 | 18.53(5 rows)Time: 41.811912ms
跨两个数据库(时序引擎的 perf_ts.perf_metrics + 关系引擎的 perf_mgmt.perf_device),JOIN 后全量聚合,41.812ms。
与 Q2 的纯时序聚合(4.84ms)相比,跨模 JOIN 慢了约 8.6 倍。这个额外开销来自跨引擎的数据交换,对于这次查询(10万行时序 JOIN 5行关系表)来说 41ms 仍在实用范围内。
稳定性测试:30轮连续写入
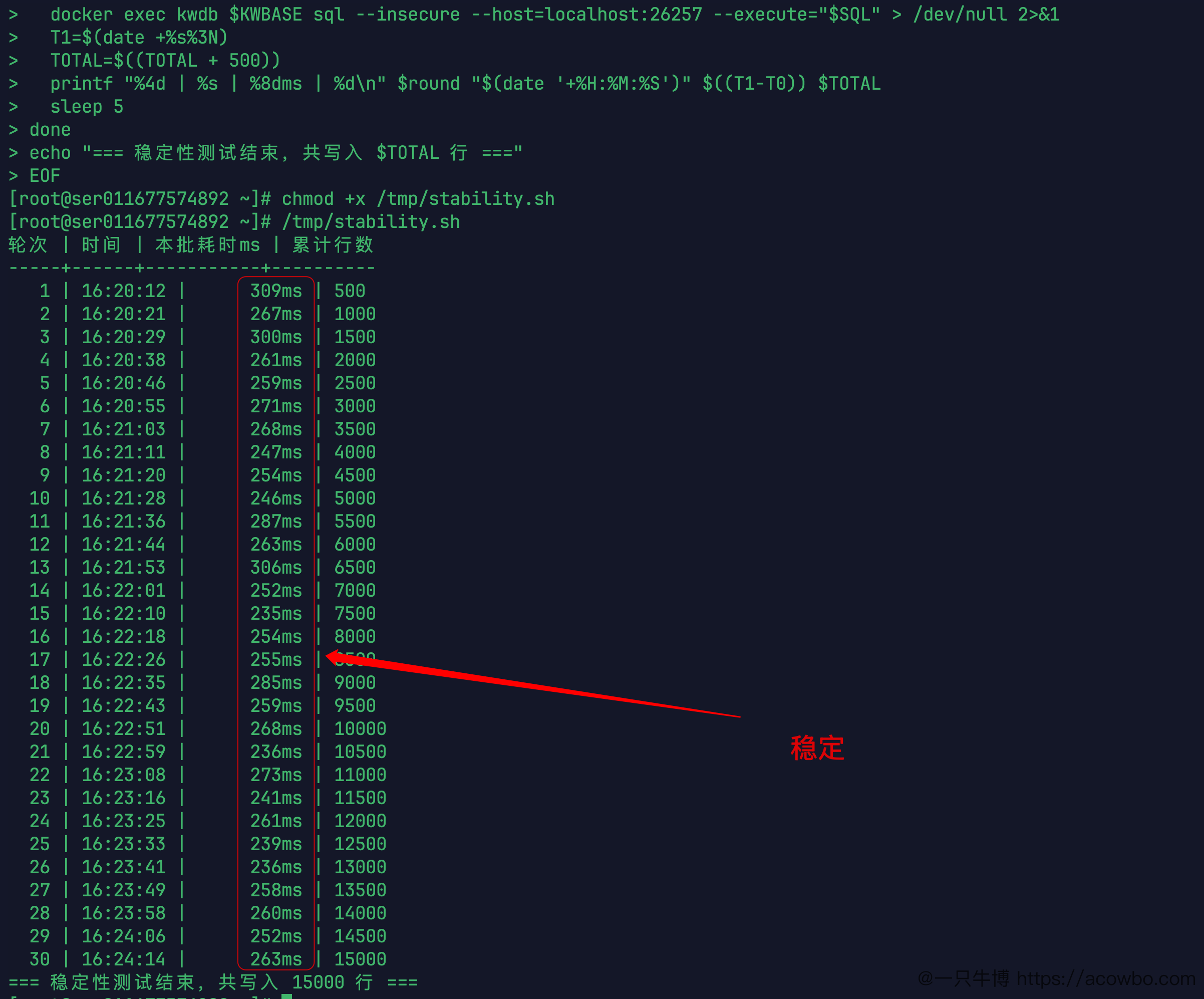
稳定性测试的关注点不是某一次的峰值,而是连续运行期间延迟是否会逐渐漂移。30轮,每轮写 500 行,每轮间隔 5 秒,总时间约4分钟:
轮次 | 时间 | 本批耗时 | 累计行数-----+----------+---------+--------- 1 | 16:20:12 | 309ms | 500 2 | 16:20:21 | 267ms | 1000 3 | 16:20:29 | 300ms | 1500 4 | 16:20:38 | 261ms | 2000 5 | 16:20:46 | 259ms | 2500 6 | 16:20:55 | 271ms | 3000 7 | 16:21:03 | 268ms | 3500 8 | 16:21:11 | 247ms | 4000 9 | 16:21:20 | 254ms | 4500 10 | 16:21:28 | 246ms | 5000 11 | 16:21:36 | 287ms | 5500 12 | 16:21:44 | 263ms | 6000 13 | 16:21:53 | 306ms | 6500 14 | 16:22:01 | 252ms | 7000 15 | 16:22:10 | 235ms | 7500 16 | 16:22:18 | 254ms | 8000 17 | 16:22:26 | 255ms | 8500 18 | 16:22:35 | 285ms | 9000 19 | 16:22:43 | 259ms | 9500 20 | 16:22:51 | 268ms | 10000 21 | 16:22:59 | 236ms | 10500 22 | 16:23:08 | 273ms | 11000 23 | 16:23:16 | 241ms | 11500 24 | 16:23:25 | 261ms | 12000 25 | 16:23:33 | 239ms | 12500 26 | 16:23:41 | 236ms | 13000 27 | 16:23:49 | 258ms | 13500 28 | 16:23:58 | 260ms | 14000 29 | 16:24:06 | 252ms | 14500 30 | 16:24:14 | 263ms | 15000=== 稳定性测试结束,共写入 15000 行 ===
30轮耗时范围:235ms ~ 309ms,第1轮 309ms 是最大值,从第二轮起维持在 235~306ms 区间,没有随时间增长的趋势。
从时间戳也能看出来:16:20:12 开始,16:24:14 结束,每轮约 9 秒(5秒等待 + 4分钟写入),节奏均匀。对于通过 shell 脚本 + docker exec 方式调用的测试,这个抖动是正常水平。
资源消耗
测试后查了一下容器资源占用(测试完毕、无额外负载状态下):
NAME CPU% MEM USAGE / LIMIT MEM%kwdb 1.65% 634.6MiB / 7.64GiB 8.11%
CPU 1.65%,内存 634.6MiB(约8.11%)。
这是静止状态的数字(测试已结束,没有并发查询),不代表峰值。但单节点跑完约10万行写入测试之后,内存只用了 634MB,对于一台 8GB 内存的机器来说,还有大量余量,基本不影响同台宿主机上的其他服务。

数据连续性验证
最后跑了一次按小时分桶的连续性检查,看数据有没有缺行或重复:
SELECT DATE_TRUNC('hour', k_timestamp) AS hour_bucket, COUNT(*) AS rows_in_hourFROM perf_metricsGROUP BY hour_bucket ORDER BY hour_bucket LIMIT 10;hour_bucket | rows_in_hour-------------------------+-------------2026-02-28 16:00:00+00:00 | 36002026-02-28 17:00:00+00:00 | 36002026-02-28 18:00:00+00:00 | 3600...(后续各小时均为3600)(10 rows)Time: 51.552382ms
每个小时桶正好 3600 行(5台设备轮流写入,每秒1行,一小时写3600秒 = 3600行),分布完全均匀,没有缺失。这条查询耗时 51.55ms,因为 DATE_TRUNC 要对每一行时间戳做函数运算,比直接聚合慢,这是预期内的行为。
测试结果汇总
测试项目 | 实测结果 |
|---|---|
单条写入延迟(SQL直连) | 均值约 1.165ms(三次实测均值) |
批次写入吞吐(1行/次) | 4 行/秒 |
批次写入吞吐(1000行/次) | 3,717 行/秒(提升 929×) |
COUNT 全表 106,558 行 | 3.991ms |
时间范围过滤+聚合 | 7.089ms(过滤出12,354行) |
全量 GROUP BY 聚合(10万行) | 4.842ms |
多条件复合过滤 | 5.824ms |
跨模 JOIN 全量聚合 | 41.812ms |
稳定性(30轮每轮500行) | 235~309ms,无漂移趋势 |
资源占用(测试后空闲) | 634.6MiB 内存,1.65% CPU |
几点实际感受
关于批次写入: 批次大小从1增到1000,吞吐量差距接近1000倍,但单次调用耗时几乎不变。原因是外部调用链路(进程启动 + 网络连接)是固定开销,KWDB 的实际写入时间只是其中一部分。实际应用中客户端必须做连接复用和批量攒发,单条写入的模式在高频场景下会把大部分时间耗在连接上而不是 DB 操作上。
关于聚合性能: 4.842ms 完成 10 万行 GROUP BY 是这次测试最直观的数字。这背后是时序列式存储的基本特性——同一列的数据在存储上相邻,聚合时不需要读取整行,只扫目标列。这种存储结构特别适合传感器类数据:写入频繁、每次查询只关心少数几个指标字段的聚合。
关于时间戳校验: KWDB 拒绝了小时数超出 0~23 范围的时间戳,不做降级处理。导致原定10万行最终只入库 91,555 行。这对我们来说是一次踩坑,但从数据库的角度来说,强校验比静默写入更安全——时序数据的时间线一旦错乱,后续所有基于时间的查询结果都会受影响。
关于跨模查询: Q4 的 41ms 比纯时序聚合慢8.6倍,但考虑到这是跨两套存储引擎的 JOIN,41ms 在单节点无调优的条件下是可以接受的查询延迟。如果业务上需要频繁做这类关联查询,做好查询计划分析和必要的缓存策略会更有帮助。
到这里,我们也就讲完了《KWDB 3.1.0 性能实测:脚本验证读写能力》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于KWDB的知识点!
 Minimax是否支持离线运行?部署现状解析
Minimax是否支持离线运行?部署现状解析
- 上一篇
- Minimax是否支持离线运行?部署现状解析

- 下一篇
- 36漫画免费入口在线看
-

- 科技周边 · 人工智能 | 1星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI音乐可视化效果评测
- 280浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | 豆包AI 豆包AI助手
- 豆包AI写诗技巧与教程分享
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClawAI摘要生成技巧全解析
- 102浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 百度发布DuMate智能体,李彦宏解读DAA新定义
- 247浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 智谱清影制作鸟瞰街景镜头教程
- 306浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClaw框架解析与技术亮点揭秘
- 357浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI美妆详情页提示词技巧
- 334浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-
- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7829次使用
-
- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8252次使用
-
- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8068次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9994次使用
-
- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8833次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


