Go 的错误处理经常被吐槽啰嗦,但我反而觉得它很适合做清楚的工程边界。真正糟糕的不是 if err != nil,而是每一层都 return errors.New("failed"),排障时只剩一地 failed。
这篇还是按我平时写博客的方式来:不堆概念,先讲为什么会踩坑,再讲怎么判断场景,最后给一份能落地的代码和 review 清单。你可以把它当成一篇上线前的自查笔记。
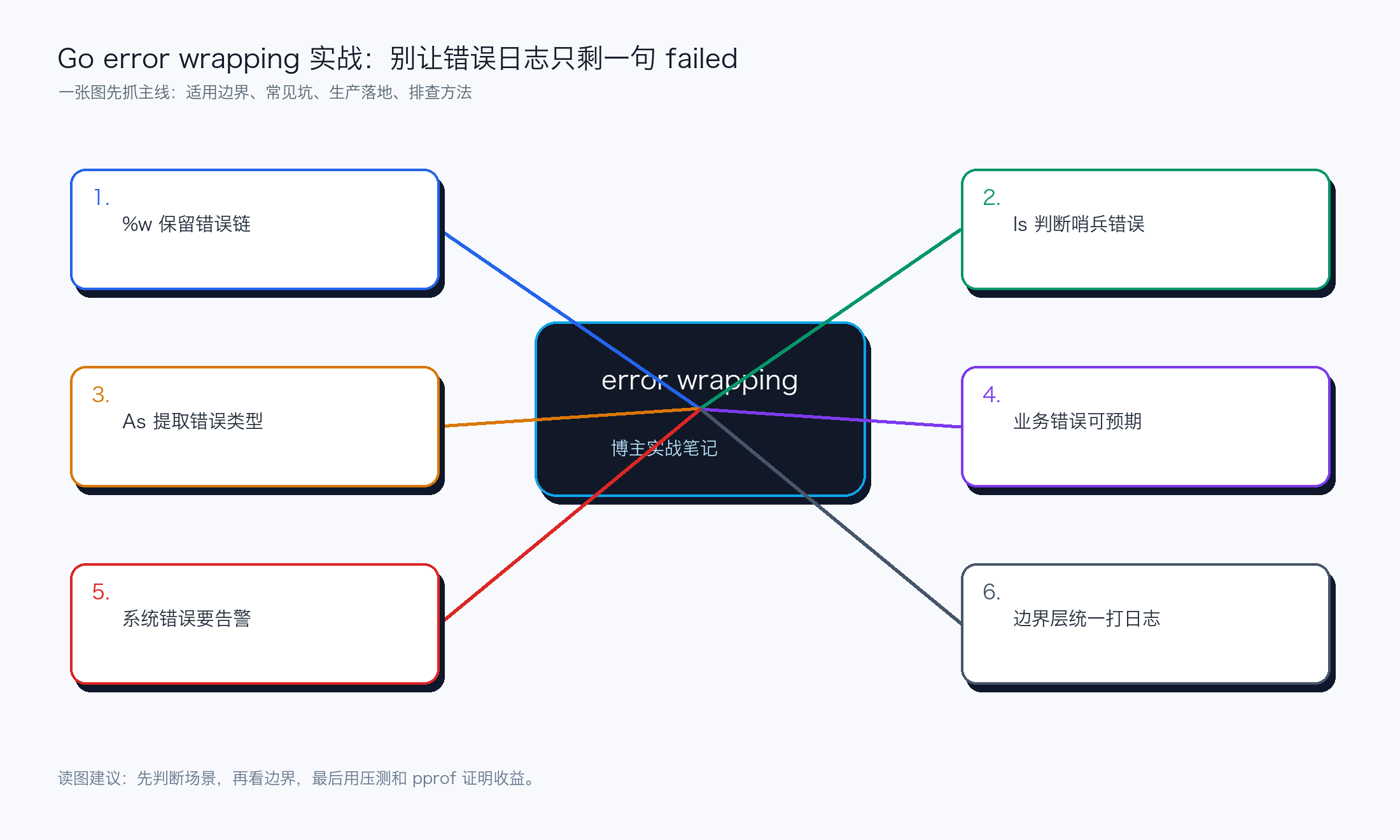
错误要带上下文,但别乱包
底层错误告诉你发生了什么,上层错误告诉你在做什么。两者合起来,日志才有排查价值。
该用 %w 的地方用 %w,这样上层还能 errors.Is/As。只用 %v 会把错误链打断。
业务错误和系统错误分开
用户不存在、余额不足,这类是业务可预期错误;数据库超时、JSON 解析失败、下游 500,是系统或依赖问题。
分清类型后,HTTP 状态码、告警级别和日志字段都会更好处理。
我的日志习惯
错误只在边界层打一次完整日志,中间层负责 wrap 上下文。否则同一个错误会在日志里刷屏。
日志里要有 request_id、关键业务 id 和错误链,不要只有一句 operation failed。
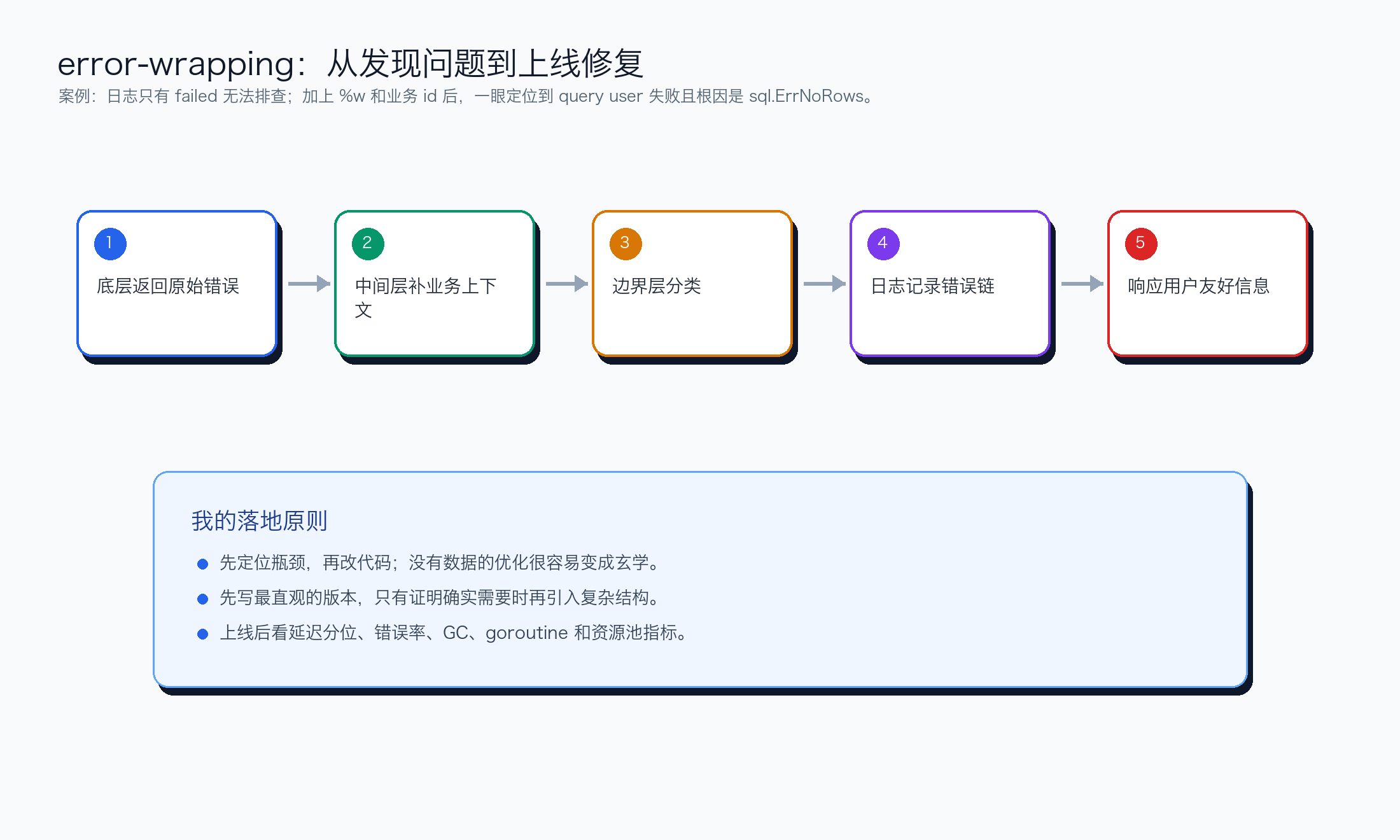
代码案例:别只看能跑,要看能不能扛线上场景
下面这个对比是我在项目里经常会提醒团队注意的点。坏写法通常不是语法错,而是边界错:低并发没问题,高峰、失败、重试、超时一来就露馅。

我的 review 清单
- 这个改动解决的是指标里的真实问题,还是只是看起来更高级?
- 失败、超时、并发、重试这些场景下,代码有没有明确的退出路径?
- 有没有用 benchmark、pprof 或压测数据证明收益?
- 日志里能不能看出关键业务 id、错误原因和调用链位置?
- 这段代码半年后新人接手,能不能一眼看懂为什么这么写?
最后聊两句
案例:日志只有 failed 无法排查;加上 %w 和业务 id 后,一眼定位到 query user 失败且根因是 sql.ErrNoRows。 这类问题最怕的不是不会修,而是上线前没人意识到它会发生。Go 的很多工具都很锋利,真正难的是知道什么时候该用,什么时候该忍住。
我的建议很简单:先写清楚,再用数据证明哪里慢,最后只在必要的位置优化。这样写出来的 Go 服务,通常比一开始就堆技巧更稳。
 2026春运火车票开售时间表出炉
2026春运火车票开售时间表出炉