很多 Go 项目跑久了以后,内存里会堆出一堆“看起来一样、实际重复存了很多份”的值:配置里的环境名、日志标签、租户 ID、IP zone、用户角色、路由名、状态枚举。单个字符串不大,但乘上千万对象,就会变成很扎眼的内存账单。
以前我们常见的办法是手写一个全局 map,把相同字符串复用起来。思路没错,但很快会遇到锁竞争、生命周期不好管、只能处理 string、回收困难这些问题。Go 标准库里的 unique 包,就是为“值规范化”这类事情准备的。今天这篇不吹新特性,只讲它适合放在哪、怎么用、哪里别用。
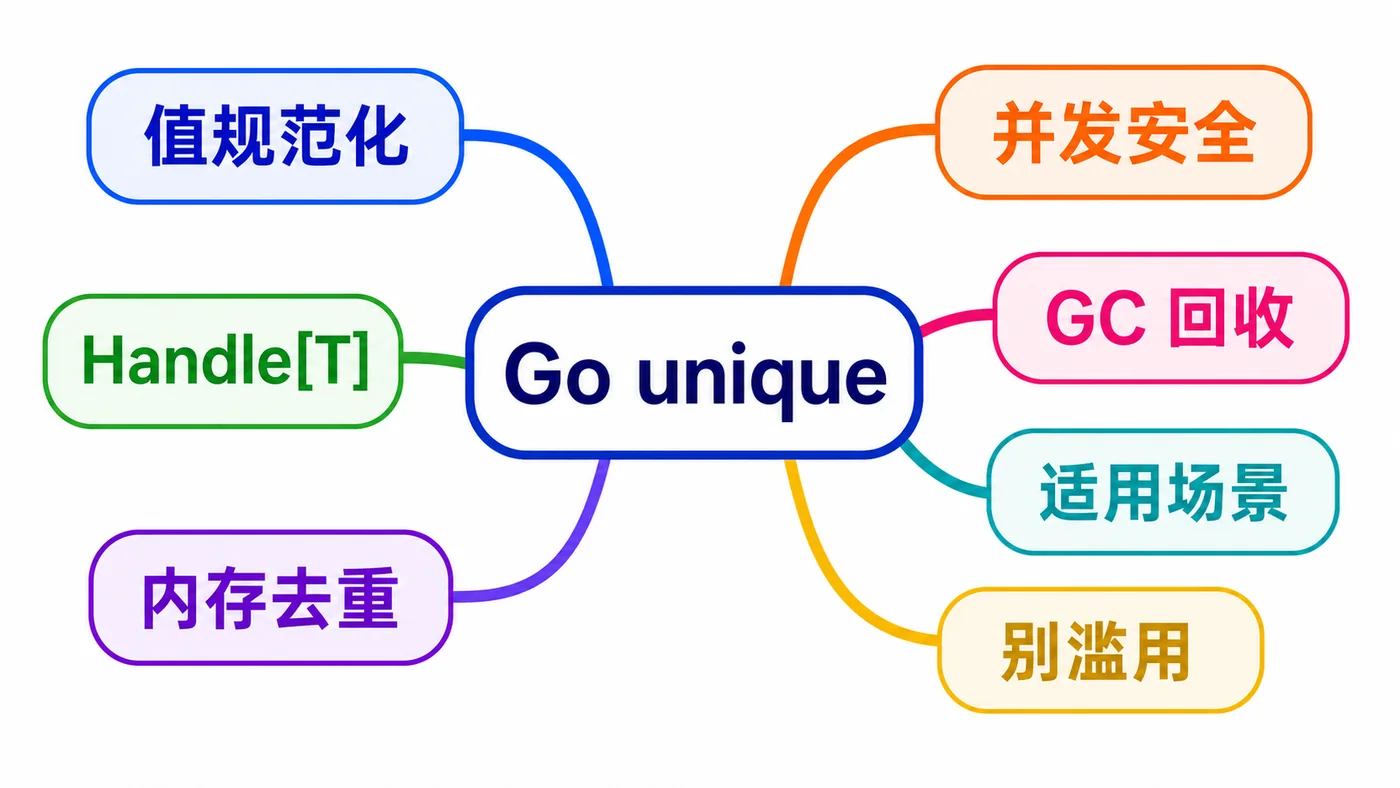
先把 unique 说成人话
unique.Make(v) 会返回一个 unique.Handle[T]。如果两个值相等,后面拿到的 handle 也会指向同一个规范化值。你可以通过 h.Value() 取回原值,也可以直接比较两个 handle。
它最核心的价值有两个:第一,重复值只保留一份规范化存储,能降低某些场景的内存占用;第二,比较 handle 比比较一大段结构体或长字符串更便宜,尤其是同一批重复值反复比较时。
package main
import "unique"
type Label struct {
Key string
Val string
}
func main() {
h1 := unique.Make(Label{Key: "env", Val: "prod"})
h2 := unique.Make(Label{Key: "env", Val: "prod"})
// 相等值会得到可直接比较的 handle
println(h1 == h2)
}
它不是万能缓存
这点一定要先讲清楚:unique 不是用来替代 Redis、本地 LRU、业务对象缓存的。它不会帮你设置过期时间,不会帮你限制容量,也不会帮你承载“查不到就加载数据库”的逻辑。
它处理的是可比较类型的“规范化值”。也就是说,你已经有一个值了,想把大量重复值压成一份,并且后面用 handle 做更便宜的比较。这跟缓存的读穿透、淘汰策略、热点保护不是一个问题。
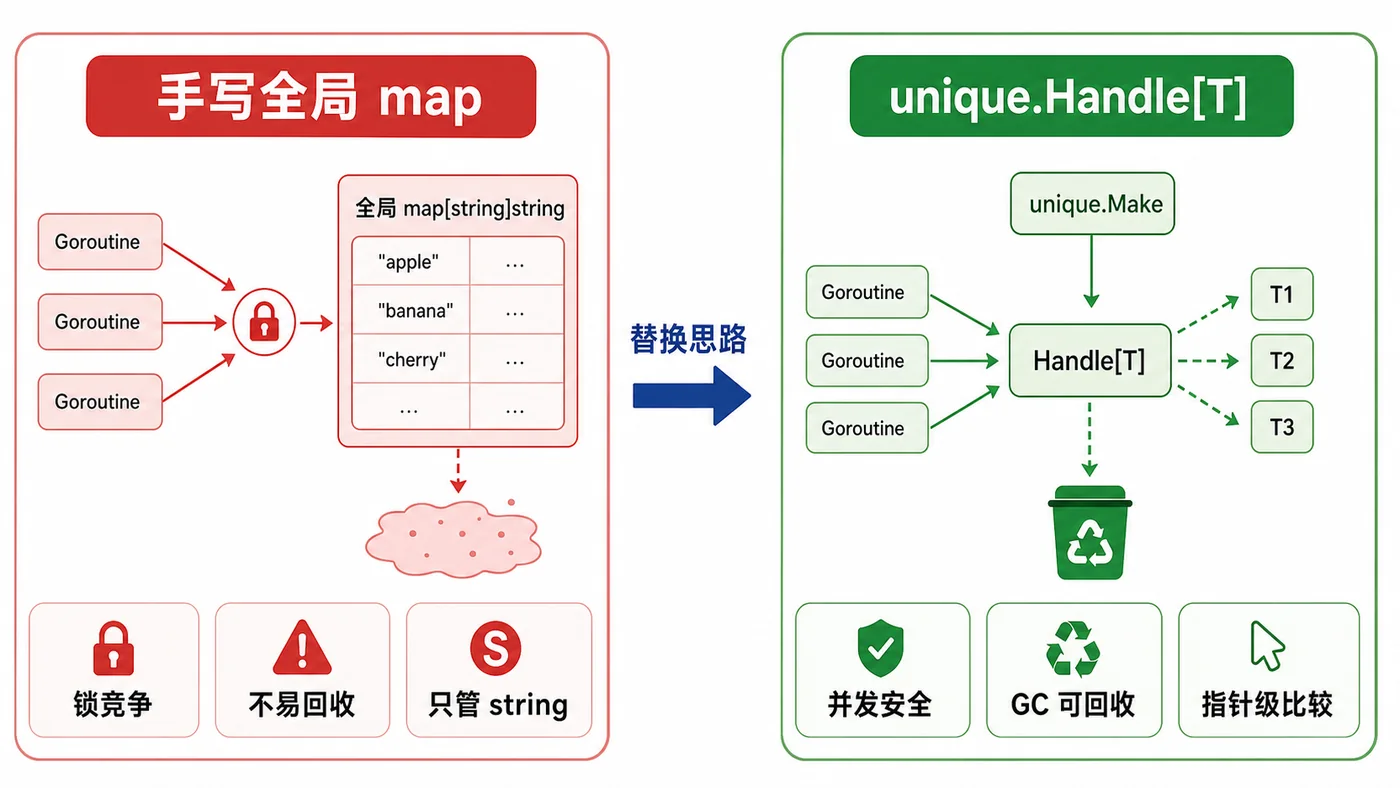
手写全局 map 为什么容易翻车
不少项目会写一个类似 map[string]string 的池子,外面包一把锁,进来一个字符串就查一下,有就返回已有的,没有就塞进去。小数据量当然没毛病,但生产环境里问题会慢慢出来。
第一,锁竞争。高并发写入或大量规范化时,所有请求都抢同一把锁。第二,生命周期。你塞进 map 的值通常不会自动回收,除非自己实现引用计数或清理策略。第三,类型受限。今天池 string,明天又想池结构体,很容易复制出一堆差不多的工具。
一个更贴近业务的例子:标签规范化
假设你有一个指标采集服务,每条样本都有一组标签。标签本身重复度极高,比如 env=prod、region=ap、service=api。如果每条样本都复制一份完整标签,内存会很快膨胀。
这时可以把标签规范化成 handle,业务对象里只存 handle。真正需要输出或序列化时,再通过 Value() 取回原值。
type Label struct {
Key string
Val string
}
type Sample struct {
Name string
Labels []unique.Handle[Label]
}
func internLabels(labels []Label) []unique.Handle[Label] {
out := make([]unique.Handle[Label], 0, len(labels))
for _, label := range labels {
out = append(out, unique.Make(label))
}
return out
}
Handle 比较很适合做快速路径
如果两个业务对象里保存的是 unique.Handle[Label],比较时就不需要反复比较 Key 和 Val。handle 本身是可比较的,等价判断可以直接走 h1 == h2。
这在“重复值多、比较频繁”的场景比较香。比如权限标签、配置项、路由元数据、指标维度、解析后的枚举状态。重点是两个条件都要满足:重复值多,比较频繁。只有一个条件满足,收益可能没你想象的大。

GC 回收这点很重要
手写全局 map 最大的隐患,是池子通常只涨不降。unique 的设计里,规范化值在没有 handle 引用后可以被回收,这让它更适合“值会重复,但集合不是永远固定”的系统。
当然,这不代表你可以随便把百万级高基数值都丢进去。比如用户输入的随机 token、请求 ID、一次性 UUID,这类值本来就不重复,放进 unique 反而会增加管理成本。低重复、高基数,是它不太适合的典型场景。
哪些类型可以用
unique 支持的是可比较类型,也就是泛型参数 T 要满足 comparable。字符串、数字、枚举、小结构体通常没问题;包含 slice、map、function 的结构体就不行。
这也是一个很好的提醒:如果你的对象很大、字段里还有很多不可比较内容,先别急着塞进 unique。更合理的做法是抽出真正重复、稳定、可比较的那一小块。
什么时候我会用 unique
第一类是配置和元数据。比如环境名、区域、机房、服务名、路由名,这些值重复度高,而且生命周期跟服务对象绑定。第二类是解析后的结构体。比如把文本配置解析成小结构体后,很多对象会共享同一组结果。
第三类是比较热点。比如你经常判断两个对象是否属于同一类标签、同一份策略、同一个小配置,handle 比较会让代码更干净。第四类是内存 profile 已经证明重复值占比较高的场景。注意这个顺序:先 profile,再优化。
什么时候别用
不要拿它处理一次性值,不要拿它替代业务缓存,不要为了“看起来高级”把所有字符串都包一层。尤其是请求 ID、trace ID、随机 token、用户输入搜索词,这些值重复率低,规范化意义不大。
也不要在还没看到内存问题时就把代码写复杂。unique.Handle[T] 是一种抽象,抽象就有理解成本。只有当它能明确减少重复值、简化比较或降低内存压力时,才值得引入。
我自己的 review 清单
- 这个值的重复率够高吗?有没有用 profile 或统计证明?
- 这个类型是否真的稳定、可比较、适合规范化?
- 业务需要的是值规范化,还是带过期策略的缓存?
- handle 保存在哪里?生命周期是否跟业务对象一致?
- 是否避免把请求 ID、随机 token 这类高基数值放进去?
- 替换后代码是否比手写全局 map 更清楚,而不是更绕?
最后聊两句
unique 这个包我挺喜欢,因为它解决的是一个很具体的工程问题:重复值太多、手写池太粗糙、比较又想更便宜。但它不是那种“所有项目都应该立刻用”的工具。
我的建议还是老规矩:先用内存 profile 找到重复值,再选一块小而稳定的类型试用。看得见收益,再推广。Go 的好工具很多,真正厉害的是知道把它放在刚好合适的位置。
 Go FIPS 140-3 实战:别把合规开关当成一行环境变量
Go FIPS 140-3 实战:别把合规开关当成一行环境变量