慢查询排查里,我最怕看到一句话:“这条 SQL 有 possible_keys,应该走索引了吧?”如果你也这么想,线上迟早会被 MySQL 教做人。possible_keys 只是候选索引,不代表执行器真的少扫了行;EXPLAIN 只是估算,不代表真实执行就按这个成本走。
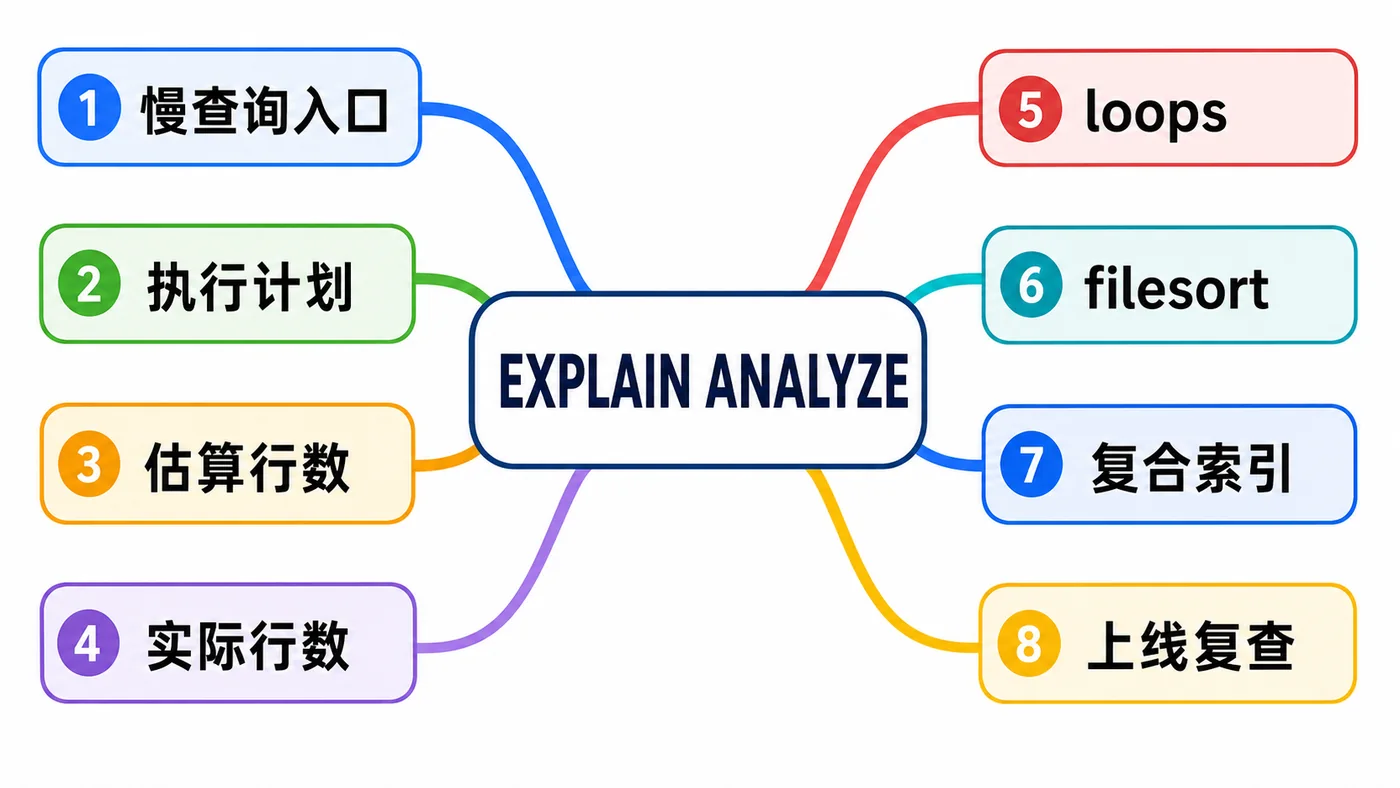
这篇不照搬官方文档。我用一个订单列表慢查询来讲 MySQL 8.x 里怎么用 EXPLAIN ANALYZE 把“估计会扫多少行”和“实际扫了多少行”对上,再决定是改 SQL、补复合索引,还是先更新统计信息。适用版本:MySQL 8.0.18 及以上可使用 EXPLAIN ANALYZE,MySQL 8.4 LTS 也适用。
业务场景:订单列表突然慢了
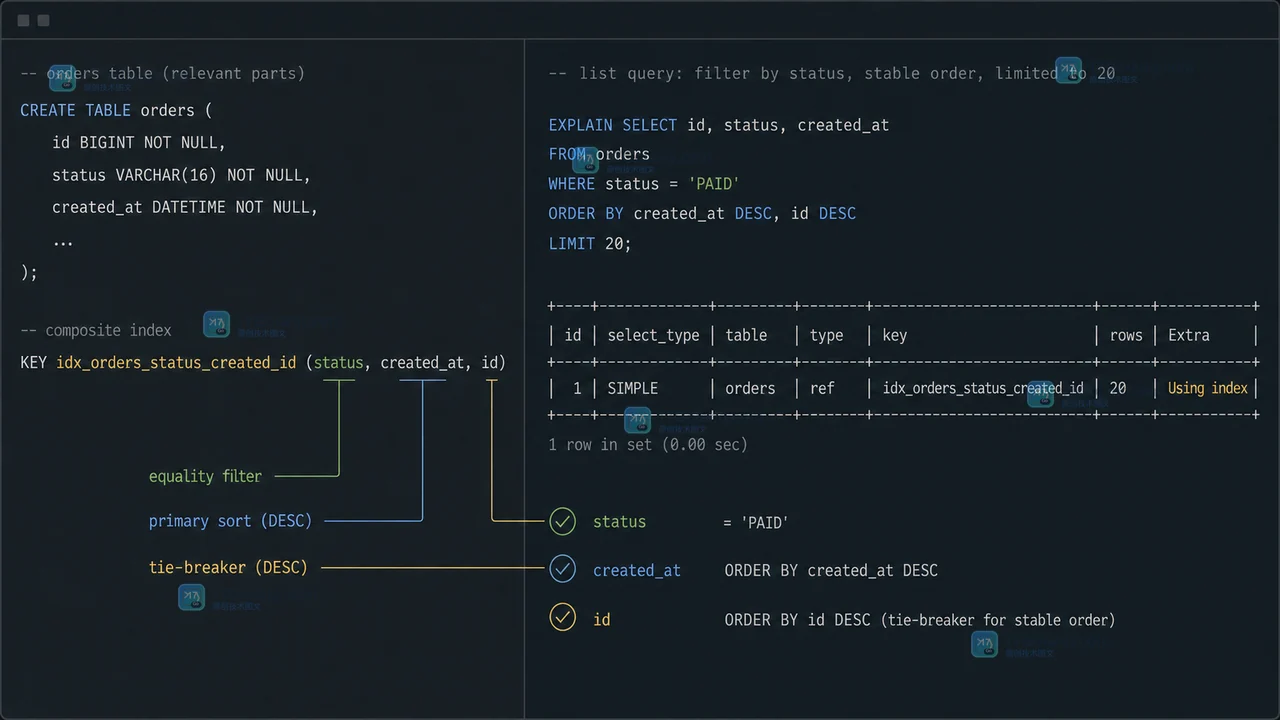
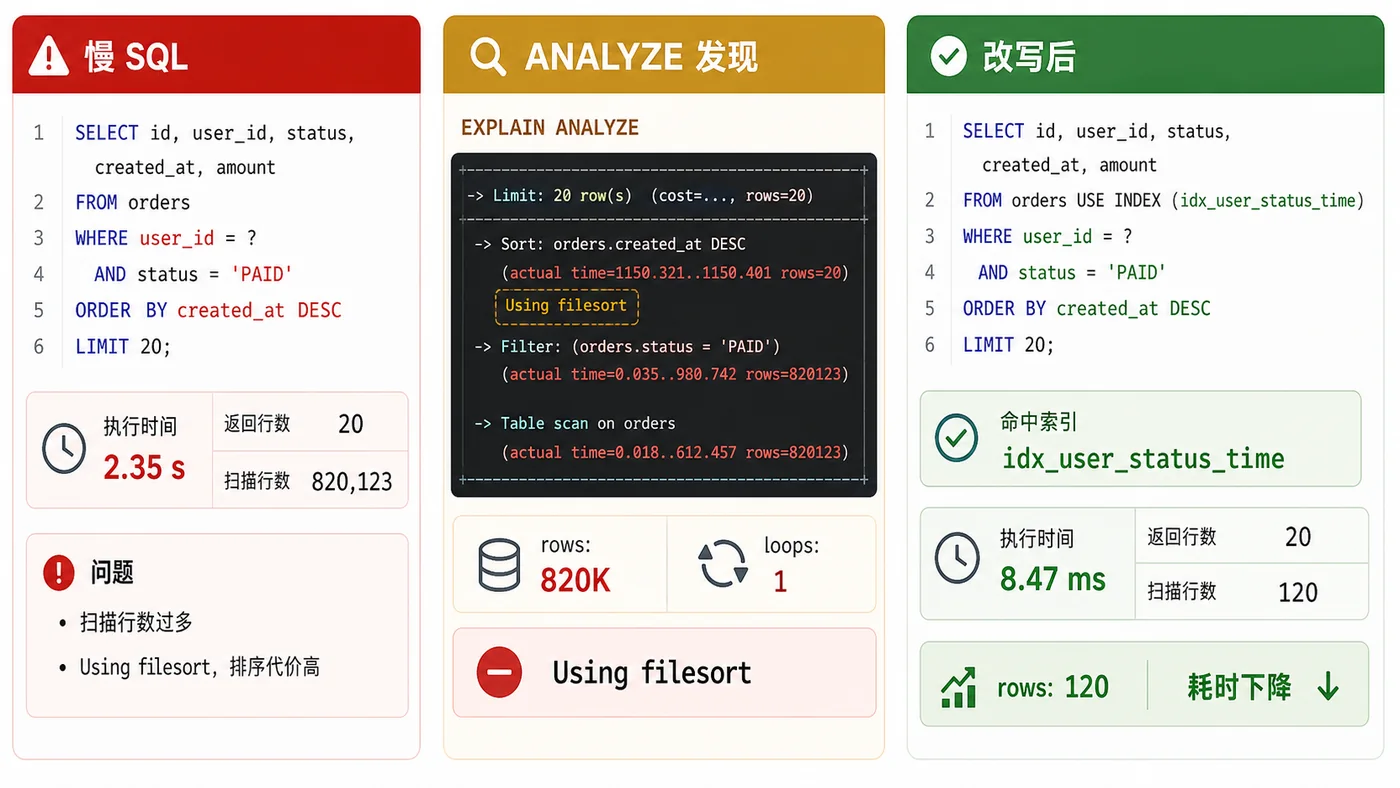
假设有一张订单表 orders,业务后台经常按用户、状态和时间倒序查最近订单。刚上线时数据少,接口 30ms;半年后订单到了千万级,偶尔一查 2 秒,慢日志里最常出现的是下面这条 SQL。
SELECT id, user_id, status, amount, created_at FROM orders WHERE user_id = 10086 AND status = 'PAID' ORDER BY created_at DESC LIMIT 20;
很多同学第一反应是:给 user_id 建索引。问题是,线上表里同一个用户可能有几十万历史订单,只靠 user_id 过滤完还要按 created_at 排序,再从里面找 status='PAID'。这个索引看着有用,实际可能还是扫得很累。
先用普通 EXPLAIN 看方向
普通 EXPLAIN 的价值是快速判断访问方式、候选索引、实际使用索引、估算行数、是否需要额外排序。它不是最终答案,但能告诉你从哪开始怀疑。
EXPLAIN SELECT id, user_id, status, amount, created_at FROM orders WHERE user_id = 10086 AND status = 'PAID' ORDER BY created_at DESC LIMIT 20;
如果你看到 key=idx_user_id,不要立刻高兴。继续看 rows、filtered 和 Extra。如果 rows 很大,Extra 里还有 Using filesort,说明 MySQL 虽然用了索引定位用户,但排序和过滤仍然可能拖慢整体。
EXPLAIN ANALYZE 看真实执行
EXPLAIN ANALYZE 会实际执行查询,并输出执行计划里每一步的真实耗时、实际行数和循环次数。它适合在测试环境、灰度库或可控场景里验证假设。生产上直接跑要谨慎,尤其是会扫大表、会触发复杂 join 的 SQL。
EXPLAIN ANALYZE SELECT id, user_id, status, amount, created_at FROM orders WHERE user_id = 10086 AND status = 'PAID' ORDER BY created_at DESC LIMIT 20;
我看 ANALYZE 输出时,重点盯三件事:第一,估算行数和实际行数差多少;第二,哪个节点耗时最高;第三,loops 是不是让一个看起来很小的步骤重复了很多次。慢查询很多时候不是单步很慢,而是“小慢步”循环太多。
估算行数和实际行数差很多,先别急着加索引
如果 EXPLAIN 估算只扫几百行,ANALYZE 实际扫了几十万行,可能是统计信息不准、数据分布倾斜,或者条件组合的选择性被优化器估错了。这个时候盲目加索引,可能只是在错误判断上继续堆东西。
我一般会先做两件事:确认表统计信息是否长期没更新;再按业务维度查一下数据分布,比如某些大客户、热门状态、历史订单是否极端集中。优化器面对“平均值”时很冷静,业务面对“超级用户”时会很狼狈。
ANALYZE TABLE orders; SELECT status, COUNT(*) FROM orders WHERE user_id = 10086 GROUP BY status;
这个场景更适合复合索引
对这条订单查询来说,真正稳定的思路通常不是单列 user_id,而是按过滤和排序关系设计复合索引。比如:
CREATE INDEX idx_user_status_time ON orders(user_id, status, created_at DESC);
这个索引的目标很明确:先定位某个用户,再过滤状态,最后按创建时间倒序拿前 20 条。这样 MySQL 不需要从大量用户订单里再额外排序,也更容易用索引顺序满足 ORDER BY created_at DESC LIMIT 20。
别看到 Using filesort 就条件反射
Using filesort 很容易吓人,但它不是“用了磁盘排序”的同义词,也不是一定要立刻修。你要结合实际行数和耗时看。如果排序只有几十行,影响很小;如果排序前扫了几十万行,那才值得认真处理。
我会把 filesort 放回上下文里看:排序前有多少行?LIMIT 能不能提前生效?索引顺序能不能覆盖过滤和排序?如果这些问题没回答清楚,单纯把 Using filesort 消掉,可能只是把问题挪到别的地方。
覆盖索引不是越宽越好
有人看到查询里返回 amount,就想把它也塞进索引:(user_id, status, created_at, amount)。这确实可能减少回表,但也会让索引更大、写入更重、缓存命中更差。
我的习惯是先让复合索引解决过滤和排序,再看回表是否真的是瓶颈。慢查询优化不要一步到位堆一个超宽索引,尤其是订单表这类写入压力大的表。索引不是免费的,写入、更新、buffer pool、备份体积都会跟着付账。
SQL 改写:只取你真的需要的列
后台列表页经常一开始就 SELECT *,后来字段越加越多,回表成本也越来越高。排查慢查询时,先把页面真的需要的列列出来,能少取就少取。
SELECT id, amount, created_at FROM orders WHERE user_id = 10086 AND status = 'PAID' ORDER BY created_at DESC LIMIT 20;
如果列表页只展示金额和时间,就别把收货地址、备注、扩展 JSON 一起拉回来。SQL 改写不是炫技,很多时候就是把需求边界收干净。
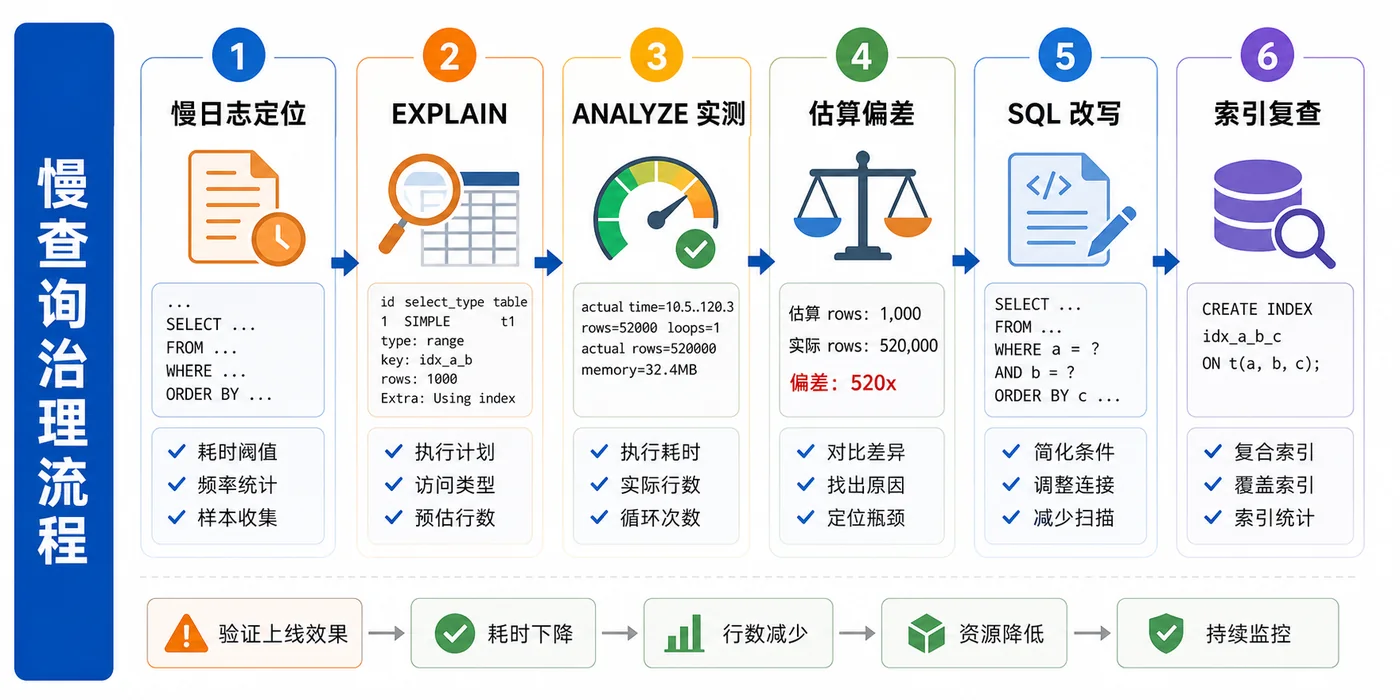
上线前后怎么复查
上线前,我会在预发或影子库里对比三组数据:旧 SQL 普通 EXPLAIN,旧 SQL EXPLAIN ANALYZE,新 SQL 加新索引后的 EXPLAIN ANALYZE。重点记录扫描行数、实际耗时、是否仍有大规模 filesort、返回行数是否一致。
上线后不要只看平均耗时,至少看 P95、P99、慢日志数量、Handler_read_next 这类读放大指标,以及写入延迟有没有被新索引拖慢。优化读查询时把写入打爆,是我见过很多团队踩过的坑。
我的慢查询 review 清单
- 这条 SQL 的业务入口是什么?是否真的是当前最慢路径?
- 普通
EXPLAIN的key、rows、Extra是否和预期一致? EXPLAIN ANALYZE里的实际行数和估算行数差多少?- 慢点在过滤、排序、回表、join,还是 loops 过多?
- 复合索引是否同时服务过滤条件和排序?索引列顺序有没有按业务选择性设计?
- 新索引是否会明显增加写入成本和存储成本?
- 上线后是否有慢日志、P99、读放大和写入延迟复查计划?
最后说句实话
MySQL 慢查询治理最容易走偏的地方,是把 EXPLAIN 当成答案。它更像问诊单,不是手术方案。真正能救命的是你把估算和真实执行对上,把业务数据分布看明白,再决定改 SQL 还是改索引。
我的经验是:别迷信某一个字段,也别迷信某一个索引。每次优化都留下前后对比、SQL 样本、执行计划和上线复查结果。这样下一次慢查询来的时候,你不是从玄学开始,而是从证据开始。
参考资料:MySQL 8.4 Reference Manual:EXPLAIN Statement、MySQL 8.4 Reference Manual:Using EXPLAIN。
 Go rand/v2 实战:抽奖、灰度和测试随机数别再混着用
Go rand/v2 实战:抽奖、灰度和测试随机数别再混着用