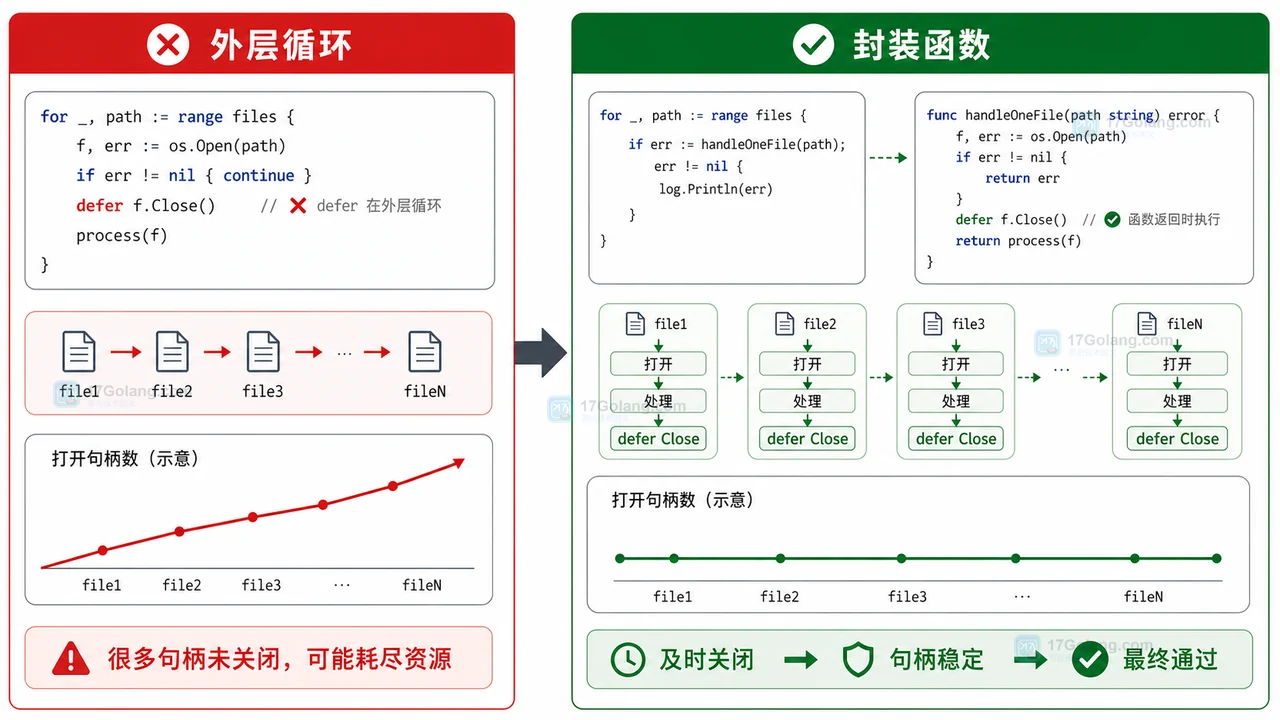
我见过很多 Go 服务的并发扇出代码,一开始都写得很豪爽:循环里起 goroutine,外面套一个 sync.WaitGroup,最后等一等就完事。上线之后才发现,某个下游失败了没人管,调用方取消了 goroutine 还在跑,结果切片并发写还偶尔冒数据竞争。代码看起来并发了,实际上只是把问题并发放大了。
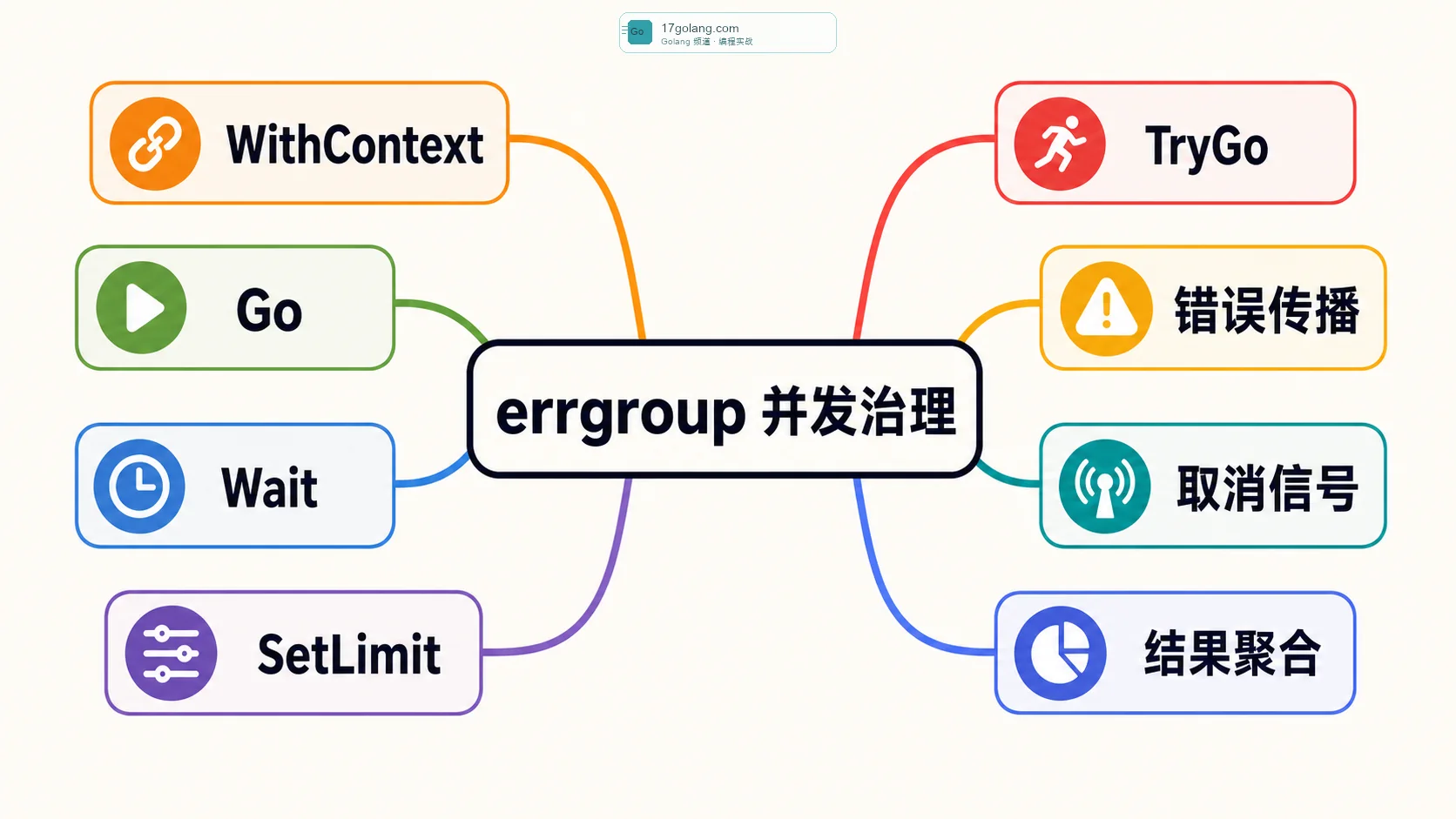
这类场景我现在优先看 golang.org/x/sync/errgroup。它解决的不是“怎么启动 goroutine”这么简单,而是把一组 goroutine 的错误、等待、取消信号和并发上限收在一个可读的边界里。官方文档里也把它定位成一组 goroutine 的同步、错误传播和 Context 取消工具。
事故场景:批量查下游,越并发越不稳
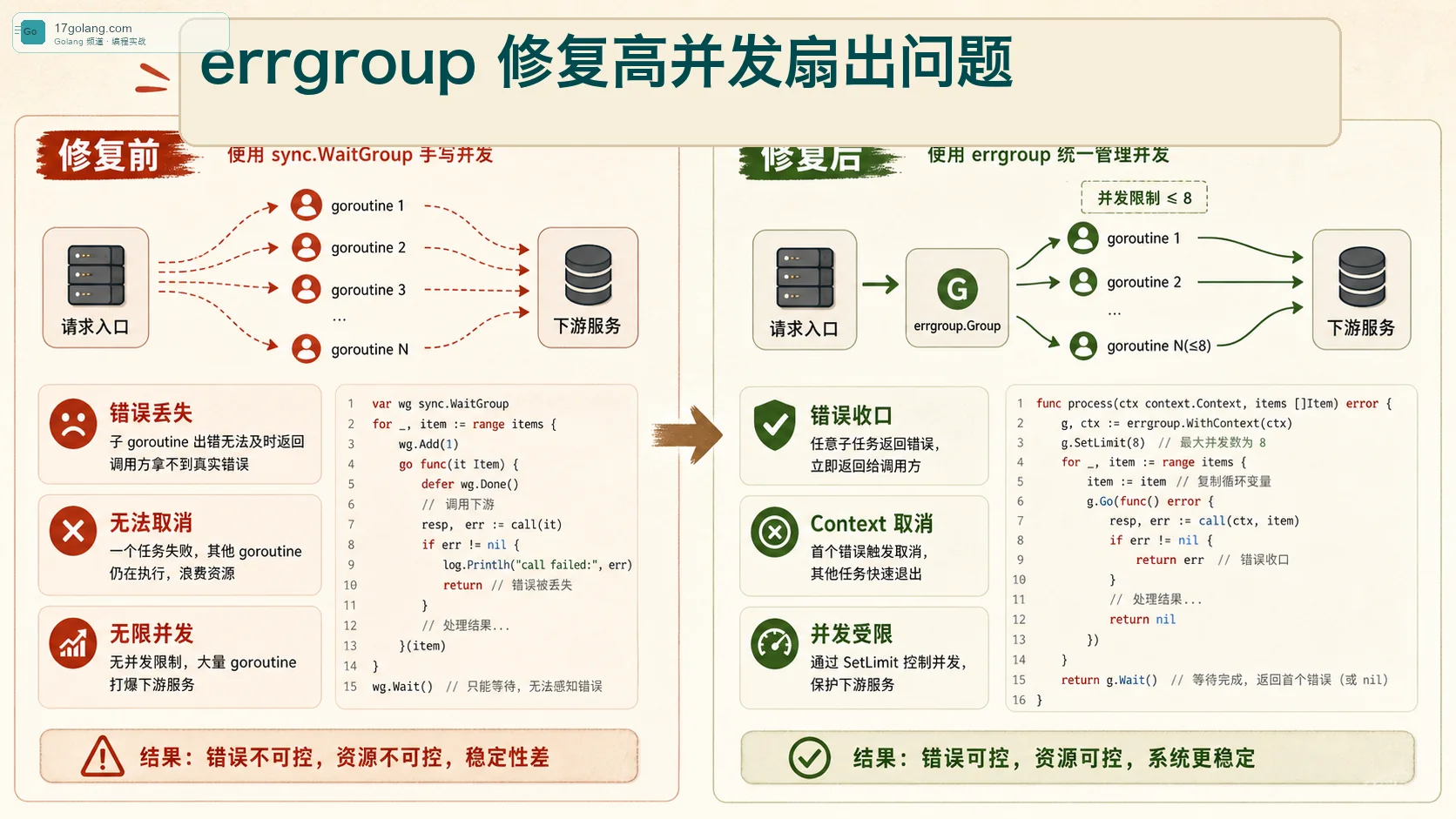
假设一个商品页要并发拉价格、库存、优惠、推荐、风控标签。手写 goroutine 很快,但问题也很快:某个接口失败后,其他 goroutine 还继续跑;上游请求取消后,下游调用照样打;错误只能塞到共享变量里,稍不注意就是 data race。
func LoadPage(ctx context.Context, ids []string) ([]Item, error) {
var wg sync.WaitGroup
var items []Item
var firstErr error
for _, id := range ids {
wg.Add(1)
go func() {
defer wg.Done()
item, err := loadItem(ctx, id)
if err != nil {
firstErr = err // 并发写,错误也不可靠
return
}
items = append(items, item) // 并发写 slice
}()
}
wg.Wait()
return items, firstErr
}
这段代码有三个经典坑:循环变量可能用错,结果和错误共享写没有保护,失败后没有取消其他任务。Go 新版本已经修过一类循环变量问题,但生产代码不能只靠语言修补;并发边界还是要自己写清楚。
用 errgroup.WithContext 把失败收回来
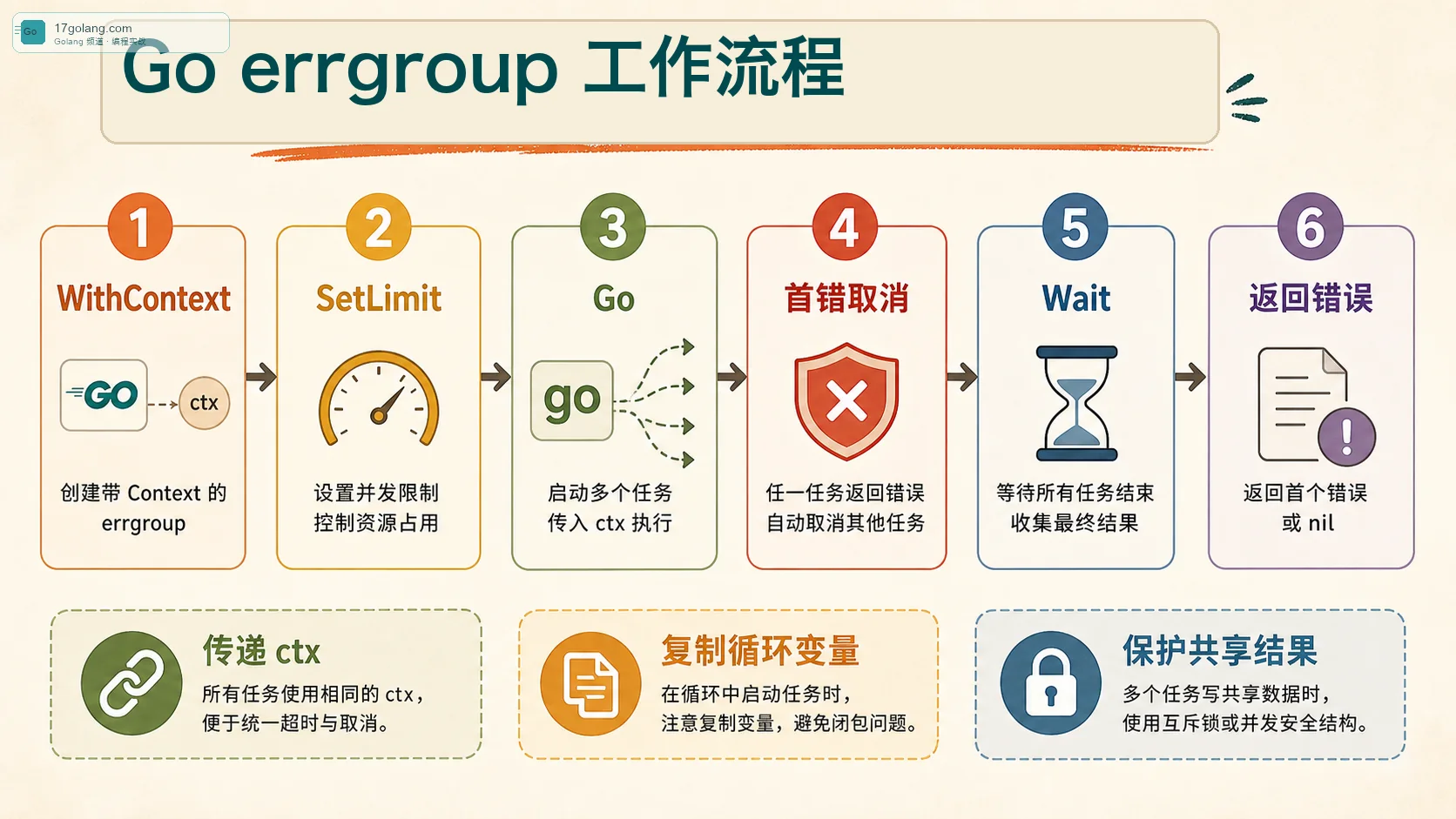
errgroup.WithContext 会返回一个 Group 和派生 Context。组内任意一个任务返回非 nil 错误时,这个 Context 会被取消。其他任务如果正确传递 ctx,就能尽快退出,不会继续把下游打满。
func LoadPage(ctx context.Context, ids []string) ([]Item, error) {
g, ctx := errgroup.WithContext(ctx)
g.SetLimit(8)
results := make([]Item, len(ids))
for i, id := range ids {
i, id := i, id
g.Go(func() error {
item, err := loadItem(ctx, id)
if err != nil {
return fmt.Errorf("load item %s: %w", id, err)
}
results[i] = item
return nil
})
}
if err := g.Wait(); err != nil {
return nil, err
}
return results, nil
}
这里我用固定下标写结果,而不是多个 goroutine 一起 append。只要每个 goroutine 写不同的位置,这比加锁 append 更简单,也更容易 review。真正需要共享 map 或聚合结构时,再用 mutex 或 channel 收口。
SetLimit:别把并发扇出写成下游压测器
errgroup 的 SetLimit 很适合控制活跃 goroutine 数。比如一次请求里有 200 个 ID,要不要同时打 200 个下游请求?我的答案通常是不。你要看下游容量、连接池、接口 SLA 和调用方预算,而不是看机器还能不能起 goroutine。
并发上限不是越大越好。上限过小会拖慢总耗时,上限过大会把下游、连接池、CPU 和内存一起推高。我一般会先按下游接口延迟和容量估一个保守值,比如 8 或 16,再用压测看 P95、错误率和下游 QPS。
TryGo:达到上限时不要硬塞任务
TryGo 适合那些“能跑就跑,不能跑就降级”的场景。它在当前活跃 goroutine 达到上限时不会启动新任务,而是返回 false。比如非关键推荐、补充标签、可选预热任务,就可以在繁忙时跳过。
if ok := g.TryGo(func() error {
return warmupOptionalCache(ctx, key)
}); !ok {
metrics.Count("warmup.skipped")
}
但核心链路别滥用 TryGo。订单、支付、权限这种任务不能因为 goroutine 满了就默默跳过。TryGo 的价值是明确降级,而不是悄悄丢任务。
Context 取消必须传到底
很多 errgroup 代码表面上用了 WithContext,但任务内部又调用了不接收 ctx 的函数,或者重新用了 context.Background()。这会把取消链路直接切断。第一个任务失败后,Group 的 ctx 已经取消了,可其他任务依然在等 I/O。
我的 review 习惯是从 g.Go 里的函数一路追下去,看数据库、HTTP、RPC、缓存、文件操作有没有吃到同一个 ctx。只要有一段不吃 ctx,就要问清楚为什么。
错误怎么返回才好排查
errgroup 的 Wait 会返回第一个非 nil 错误。这个错误一定要带上下文,否则你只会得到一句 deadline exceeded 或 connection reset,不知道哪个 ID、哪个下游、哪个阶段出了问题。
g.Go(func() error {
profile, err := userClient.LoadProfile(ctx, uid)
if err != nil {
return fmt.Errorf("load profile uid=%d: %w", uid, err)
}
profiles[i] = profile
return nil
})
如果业务需要收集所有错误,errgroup 就不是完整答案。你可以在任务里把错误写入受保护的切片,再返回一个主错误触发取消;也可以不用首错取消,改成 channel 聚合。工具要服务业务语义,不要为了用 errgroup 把需求写歪。
上线前检查清单
- 是否需要首错取消:一个任务失败后,其他任务继续跑还有没有意义?
- ctx 是否传到底:HTTP、数据库、RPC、缓存调用有没有接收同一个 ctx?
- 并发上限是否合理:SetLimit 不能拍脑袋,要结合下游容量和压测。
- 结果写入是否安全:固定下标写切片、加锁、channel 聚合,三选一写清楚。
- 错误是否带上下文:错误链里要能看到业务 ID、下游名和动作。
- 指标是否覆盖:任务数量、并发上限、Wait 耗时、取消次数、首错类型都要能看到。
我自己的经验
errgroup 最适合“同一个请求里有一组相关任务,失败后可以统一取消”的场景。比如聚合页、批量查询、并发校验、并发预加载。它不适合无穷无尽的后台 worker,也不适合需要长期运行的任务编排。
还有一点很现实:errgroup 能让代码更短,但短不是目的。真正的收益是新人读代码时能一眼看懂:这些 goroutine 属于同一组,错误从 Wait 出来,取消从 ctx 传下去,并发由 SetLimit 控住。并发代码能被读懂,才谈得上稳定。
最后聊两句
Go 让启动 goroutine 变得太容易了,所以我们更要克制。并发扇出不是把任务全部丢出去,而是给它们一个边界:谁负责等,谁负责取消,错误从哪里回来,最多同时跑多少,结果怎么安全落地。
如果你的项目里还有手写 WaitGroup 聚合下游请求的代码,建议拿这篇的清单扫一遍。能用 errgroup 收口的地方,尽量收;不能用的地方,也要把错误、取消和并发上限写清楚。线上服务怕的不是 goroutine 少,而是 goroutine 没人管。
 Python 打包发布实战:别把运行依赖和开发依赖混在一起
Python 打包发布实战:别把运行依赖和开发依赖混在一起