线上排查 Python 服务问题时,最怕的不是报错,而是日志里只有一句 pay failed,没有 request_id、没有订单号、没有异常栈。更麻烦的是,同一个请求进入异步任务、线程池、后台回调后,日志上下文断了,搜索平台里只能靠时间窗口猜。
这篇文章从一个真实常见的故障写起:异步服务里 request_id 一会儿有、一会儿没有,慢日志 handler 还拖慢了请求线程。我们用 Python 标准库里的 logging、contextvars、QueueHandler 和 QueueListener 做一套够工程化的日志链路:字段可检索、异常栈完整、请求线程少做慢 I/O,适用于 Python 3.12/3.13,也兼容更高版本。
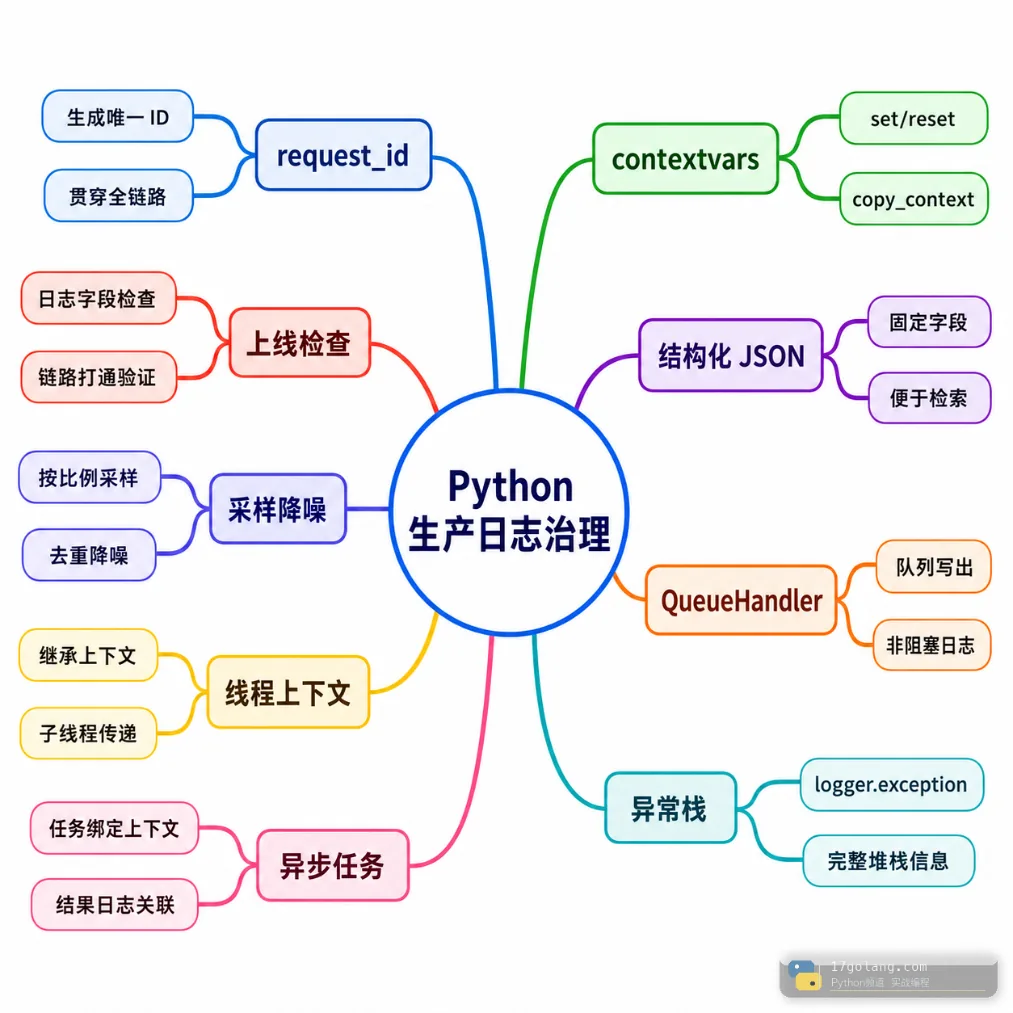
业务场景:支付失败,但日志串不起来
假设你维护一个订单服务。一次用户支付失败,网关日志里有 request_id=rid-7f3c2e1a,订单服务日志里只有用户 ID,支付客户端日志里只有 timeout,后台补偿任务又生成了新的日志上下文。最后大家在日志平台里按分钟翻,像在黑暗里摸钥匙。
# 看似正常,线上基本不可排查
logger.info("create order ok")
logger.error("pay failed: %s", exc)
# 更糟糕:全局变量在并发请求下会互相覆盖
current_request_id = "-"
def set_request_id(rid: str) -> None:
global current_request_id
current_request_id = rid
这个写法有三个坑:日志没有结构化字段,异常没有堆栈,全局变量在并发请求里会串。即使你把全局变量换成 threading.local(),在 asyncio 任务切换和线程池边界上也容易出现意料之外的上下文缺口。
先定标准:每条业务日志必须带上下文
我一般先定一条硬规则:业务路径上的日志必须能回答“哪个请求、哪个用户、哪个订单、哪个阶段、失败原因是什么”。这不是为了好看,而是为了让日志检索能直接定位问题。
{
"ts": "2026-06-05T10:20:31.012+08:00",
"level": "ERROR",
"logger": "service.pay",
"request_id": "rid-7f3c2e1a",
"order_id": "O20260605001",
"event": "pay_failed",
"message": "payment gateway timeout"
}
字段要少而稳定。不要今天叫 traceId,明天叫 request_id,后天叫 rid。Python 代码里也不要到处手写拼接字符串,应该由日志配置统一注入基础字段。
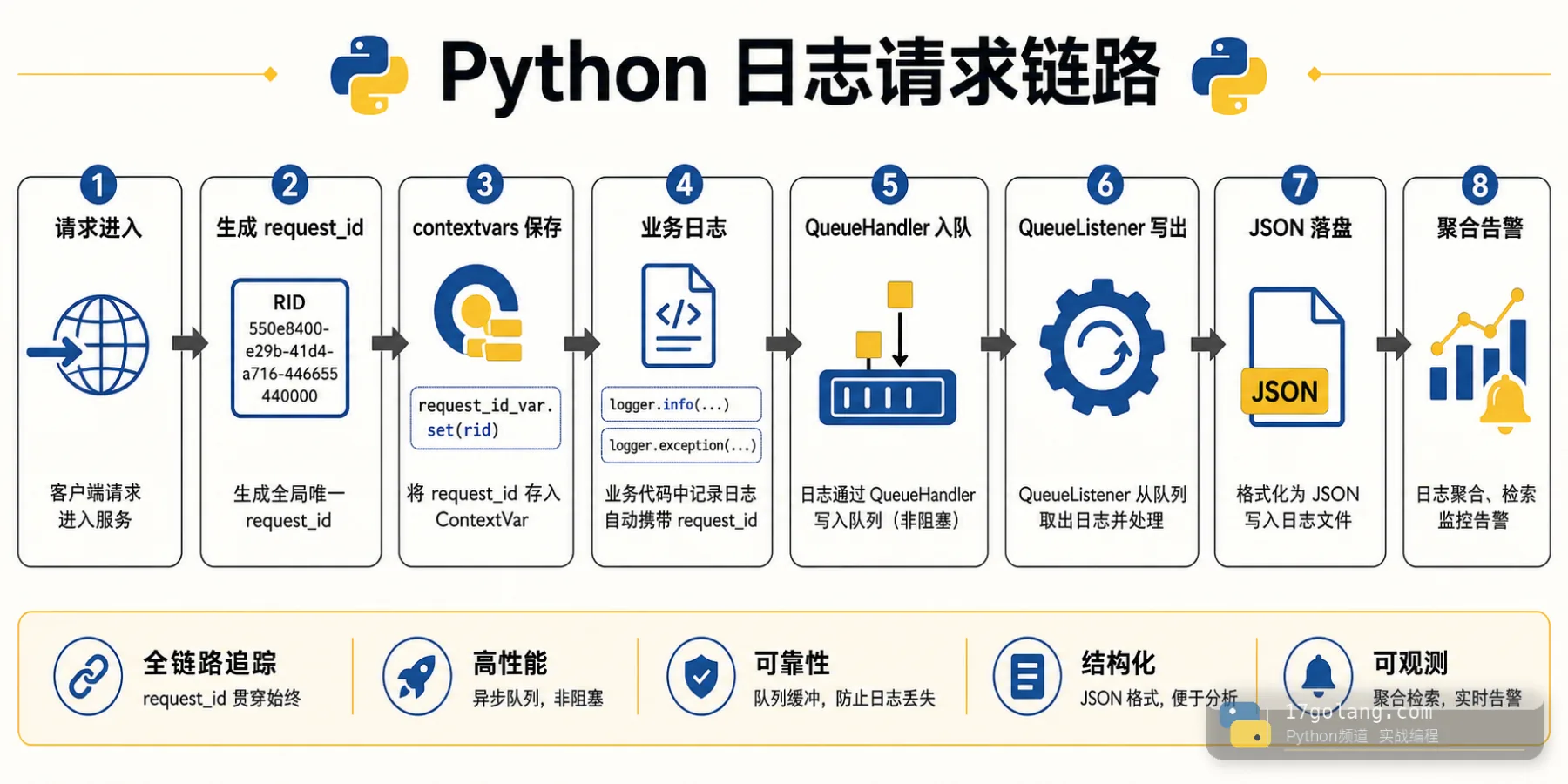
用 contextvars 保存 request_id
contextvars.ContextVar 是 Python 标准库提供的上下文变量,适合在并发代码里保存“当前请求”这类上下文。它和普通全局变量最大的区别是:值属于当前执行上下文,不会简单地被另一个并发请求覆盖。
# logging_context.py
from __future__ import annotations
import contextvars
import uuid
request_id_var: contextvars.ContextVar[str] = contextvars.ContextVar(
"request_id",
default="-",
)
def new_request_id(header_value: str | None) -> str:
if header_value:
return header_value[:80]
return f"rid-{uuid.uuid4().hex[:12]}"
def get_request_id() -> str:
return request_id_var.get()
注意两个细节。第一,ContextVar 放在模块顶层创建,不要在闭包里临时创建。第二,请求结束时要恢复旧值,避免连接复用、测试复用或手写任务调度时残留上下文。
在请求入口 set/reset,而不是到处传 rid
真实项目里你可以在 ASGI/WSGI 中间件、RPC 拦截器、消息消费入口设置 request_id。下面用一个框架无关的异步函数模拟入口:
# request_entry.py
from collections.abc import Awaitable, Callable
from logging_context import new_request_id, request_id_var
async def run_with_request_id(
headers: dict[str, str],
handler: Callable[[], Awaitable[object]],
) -> object:
rid = new_request_id(headers.get("x-request-id"))
token = request_id_var.set(rid)
try:
return await handler()
finally:
request_id_var.reset(token)
不要偷懒省掉 reset。请求入口、消息入口、定时任务入口都应该形成这种“设置、执行业务、恢复”的结构。Python 3.14 给 token 增加了上下文管理器用法,但如果你的生产环境还是 Python 3.12/3.13,上面这种显式 try/finally 是最稳妥的写法。
用 Filter 给 LogRecord 注入字段
业务代码不应该每次都写 extra={"request_id": get_request_id()}。更好的做法是用 logging.Filter 在记录生成后统一补字段。
# logging_setup.py
import json
import logging
from datetime import datetime, timezone
from logging_context import get_request_id
class RequestContextFilter(logging.Filter):
def filter(self, record: logging.LogRecord) -> bool:
record.request_id = get_request_id()
return True
class JsonFormatter(logging.Formatter):
def format(self, record: logging.LogRecord) -> str:
data = {
"ts": datetime.now(timezone.utc).isoformat(),
"level": record.levelname,
"logger": record.name,
"request_id": getattr(record, "request_id", "-"),
"message": record.getMessage(),
}
for key in ("event", "order_id", "user_id"):
value = getattr(record, key, None)
if value is not None:
data[key] = value
if record.exc_info:
data["exc_info"] = self.formatException(record.exc_info)
return json.dumps(data, ensure_ascii=False)
这里没有引入第三方 JSON 日志库,是为了看清机制。生产里你可以继续用团队标准库,但原则不变:字段由日志系统统一收口,业务代码只补业务字段。
异常日志要用 logger.exception
logger.error("pay failed: %s", exc) 只能留下异常字符串,堆栈会丢。排查支付超时、解析失败、数据库异常时,栈信息往往比错误消息更有价值。
# payment.py
import logging
logger = logging.getLogger("service.pay")
async def pay_order(order_id: str, user_id: str) -> None:
try:
await call_gateway(order_id)
except TimeoutError:
logger.exception(
"payment gateway timeout",
extra={
"event": "pay_failed",
"order_id": order_id,
"user_id": user_id,
},
)
raise
我的经验是,异常边界要少而准。真正处理异常的地方记录 exception,中间层不要层层重复打 ERROR,否则日志平台里会出现一串相同错误,看起来像多个故障。

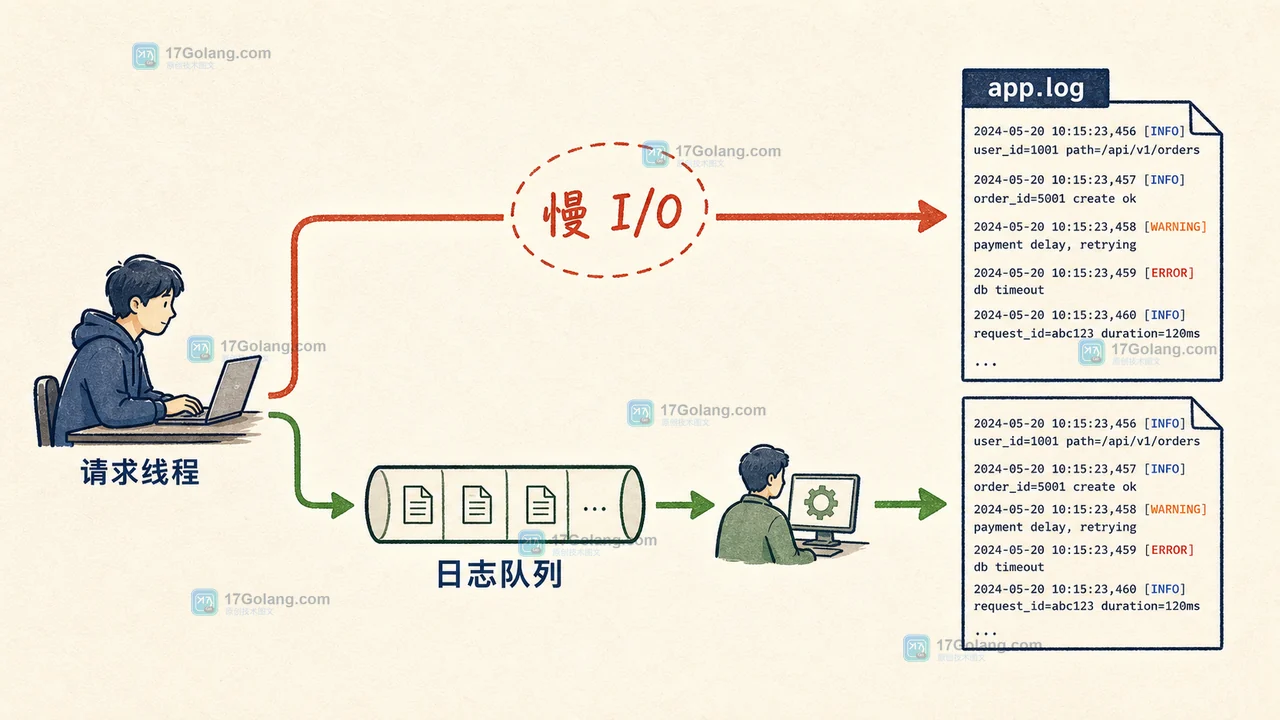
慢 handler 放到 QueueListener 后面
文件轮转、网络发送、邮件告警、慢磁盘写入都可能拖慢请求线程。Python 标准库的 QueueHandler 可以把 LogRecord 放入队列,QueueListener 在后台线程里交给真正的 handler 处理。
# queue_logging.py
import logging
import queue
from logging.handlers import QueueHandler, QueueListener, RotatingFileHandler
from logging_setup import JsonFormatter, RequestContextFilter
def configure_logging() -> QueueListener:
log_queue: queue.Queue[logging.LogRecord] = queue.Queue(maxsize=10000)
root = logging.getLogger()
root.setLevel(logging.INFO)
root.handlers.clear()
queue_handler = QueueHandler(log_queue)
queue_handler.addFilter(RequestContextFilter())
root.addHandler(queue_handler)
file_handler = RotatingFileHandler(
"logs/app.jsonl",
maxBytes=256 * 1024 * 1024,
backupCount=10,
encoding="utf-8",
)
file_handler.setFormatter(JsonFormatter())
listener = QueueListener(log_queue, file_handler, respect_handler_level=True)
listener.start()
return listener
队列不是银弹。队列满了怎么办、进程退出前是否调用 listener.stop()、容器里文件由谁采集、日志是否会被重复采集,都要在上线前定清楚。如果你使用 multiprocessing.Queue,还要特别避开同一个队列被 multiprocessing 内部 logger 和 QueueHandler 互相递归使用。
线程池边界:显式复制上下文
contextvars 对 asyncio 支持很好,但你把函数丢进线程池时,要看清上下文是否被执行器自动传播。最稳妥的做法是在提交任务时复制当前上下文,再用 ctx.run 执行。
# thread_boundary.py
import contextvars
from concurrent.futures import ThreadPoolExecutor
executor = ThreadPoolExecutor(max_workers=8)
def submit_with_context(fn, *args, **kwargs):
ctx = contextvars.copy_context()
return executor.submit(ctx.run, fn, *args, **kwargs)
这段代码解决的是“请求里开了线程池,子线程日志没有 request_id”的老问题。不要在子线程里重新生成一个 request_id,那会让一条链路变成两条链路。
问题复现:为什么全局 request_id 会串
下面这个小例子能复现全局变量的风险。两个请求并发执行时,后进入的请求会覆盖前一个请求的全局上下文。
import asyncio
current_request_id = "-"
async def bad_handler(rid: str):
global current_request_id
current_request_id = rid
await asyncio.sleep(0.01)
print("bad", rid, "log_rid=", current_request_id)
async def main():
await asyncio.gather(
bad_handler("rid-A"),
bad_handler("rid-B"),
)
asyncio.run(main())
换成 ContextVar 后,每个任务读取到的是自己的上下文值。这个差异在线上很关键:日志链路的可信度,来自上下文隔离,而不是来自“希望并发刚好不撞”。
上线检查清单
- 入口统一生成或接收
x-request-id,并在finally中 reset。 ContextVar在模块顶层创建,不在闭包里动态创建。- 日志输出为 JSON Lines,字段名稳定,至少包含
ts、level、logger、request_id、message。 - 业务字段通过
extra补充,禁止把订单号、用户 ID 只拼进自然语言消息。 - 异常边界使用
logger.exception,避免只记录str(exc)。 - 慢 handler 放到
QueueListener后面,请求线程只负责入队。 - 进程退出前调用
listener.stop(),避免队列里的日志来不及写出。 - 线程池任务用
contextvars.copy_context()显式传播上下文。 - 压测时观察队列长度、丢日志策略、日志落盘延迟和采集端背压。
总结
Python 日志治理的重点不是“把日志打多一点”,而是让每条日志都能被串起来、搜出来、解释清楚。contextvars 解决上下文隔离,logging.Filter 负责统一注入字段,QueueHandler 和 QueueListener 把慢处理从请求路径挪走。
如果你只改一件事,我建议先把 request_id 做成标准字段,并保证异步任务、线程池和异常日志都不丢它。等链路能串起来,再谈采样、告警和成本优化,团队排障效率会立刻上一个台阶。
 Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音