Python zipfile 批量打包实战:保留目录结构、过滤临时文件和写入校验
项目上线、资料归档、离线交付时,经常要把一个目录批量打成 zip 包。手动压缩看起来快,但一旦目录里混进缓存、日志、临时文件,或者压缩包里路径层级错了,后面解包就会很麻烦。本文用 Python 标准库 zipfile 写一个可复用的打包脚本。
摘要
这篇文章会完成一个实用脚本:从源目录递归收集文件,按规则跳过缓存和日志,写入 zip 时保留相对路径,最后读取压缩包做数量、路径和 CRC 校验。整个过程只依赖 Python 标准库,适合放进构建脚本或日常自动化任务。
适合人群
适合需要用 Python 做文件自动化、项目交付打包、静态资源归档、批量资料压缩的同学。你只需要熟悉基础函数、循环和 pathlib 的简单用法。
目录
- 打包流程先理清
- 最小可用脚本
- 过滤缓存、日志和临时文件
- 写入后做校验
- 常见坑和优化建议
打包流程先理清
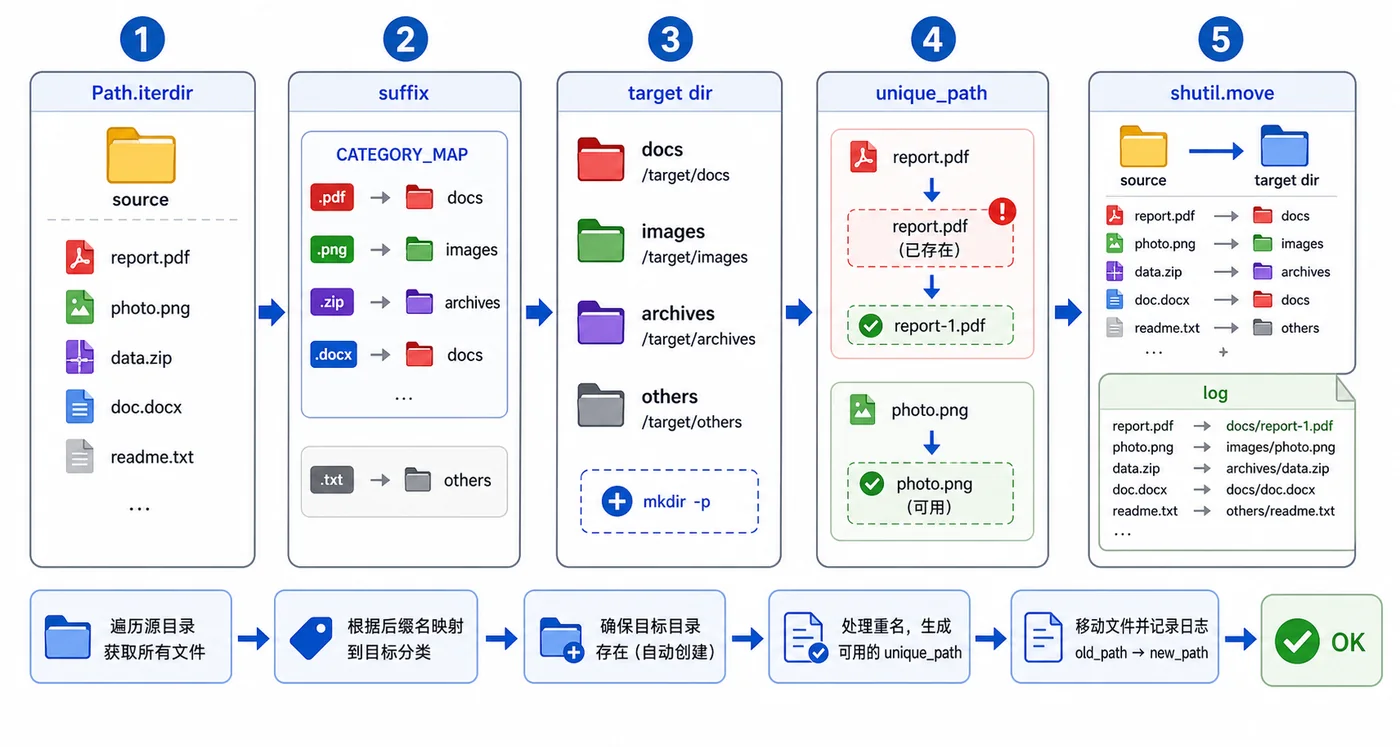
一个可靠的批量打包流程通常不是“遍历到文件就写入”这么简单。更稳的顺序是:先确定源目录,再判断文件是否应该进入压缩包,写入时使用相对路径,最后打开压缩包检查结果。
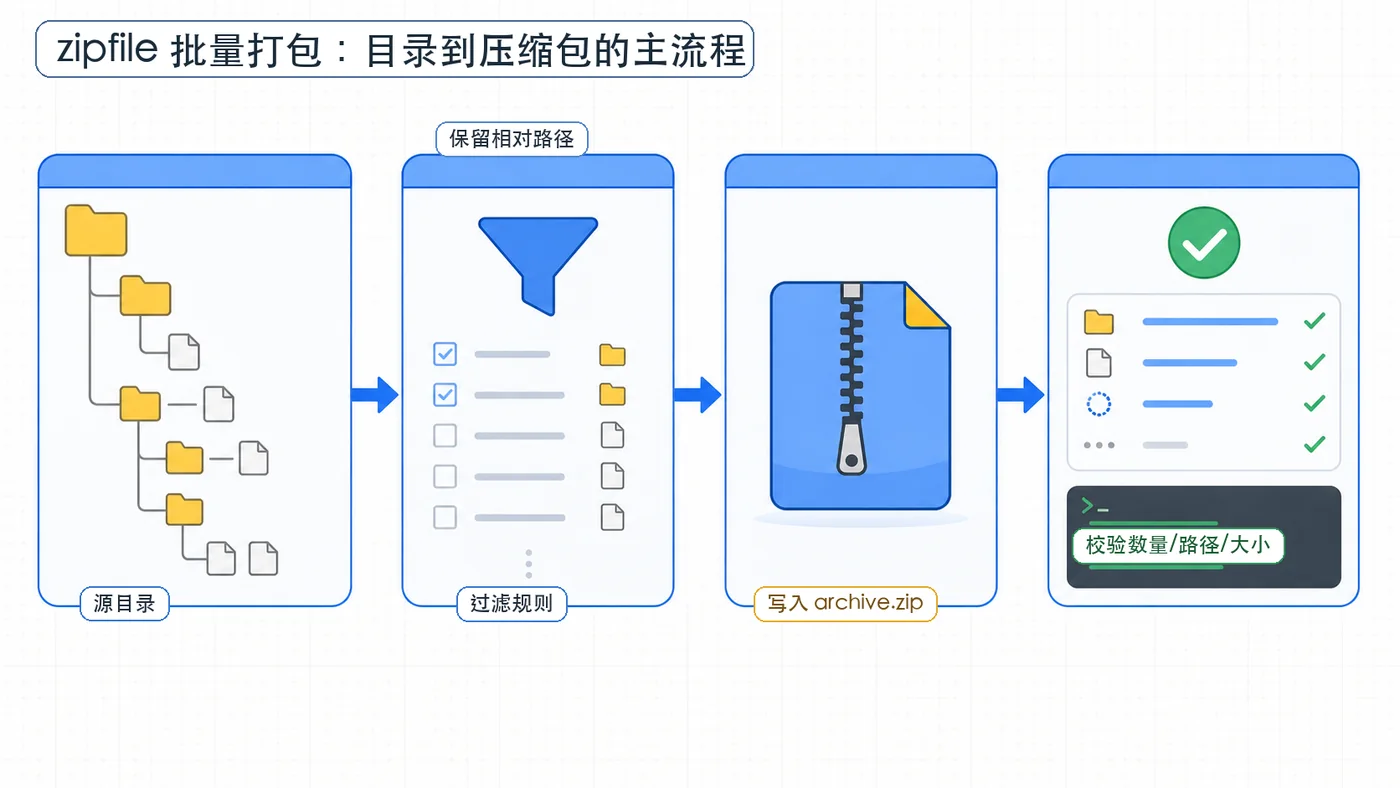
这里最容易忽略的是“相对路径”。如果直接把绝对路径写入压缩包,别人解压后可能看到很长的本机目录层级;正确做法是以源目录为根,只把根目录下面的相对路径写进去。
最小可用脚本
先写一个能跑通的版本。它会遍历 source_dir 下所有文件,并把它们写入 target_zip。
from pathlib import Path
from zipfile import ZipFile, ZIP_DEFLATED
def package_dir(source_dir: str, target_zip: str) -> int:
source = Path(source_dir).resolve()
target = Path(target_zip).resolve()
total = 0
with ZipFile(target, "w", ZIP_DEFLATED, compresslevel=6) as zf:
for path in sorted(source.rglob("*")):
if not path.is_file():
continue
arcname = path.relative_to(source).as_posix()
zf.write(path, arcname)
total += 1
return total
if __name__ == "__main__":
count = package_dir("web_dist", "release-web.zip")
print(f"packed files: {count}")
这段代码有三个关键点:
source.rglob("*")用来递归遍历目录。path.relative_to(source).as_posix()保留相对路径,并统一成 zip 常见的斜杠路径。ZIP_DEFLATED开启常用压缩方式,适合文本、配置、静态资源等文件。
过滤缓存、日志和临时文件
真实项目里,目录里可能有 __pycache__、.git、日志文件、临时文件。它们通常不应该进入交付包。我们可以把过滤规则单独拆出来,让后续维护更清楚。
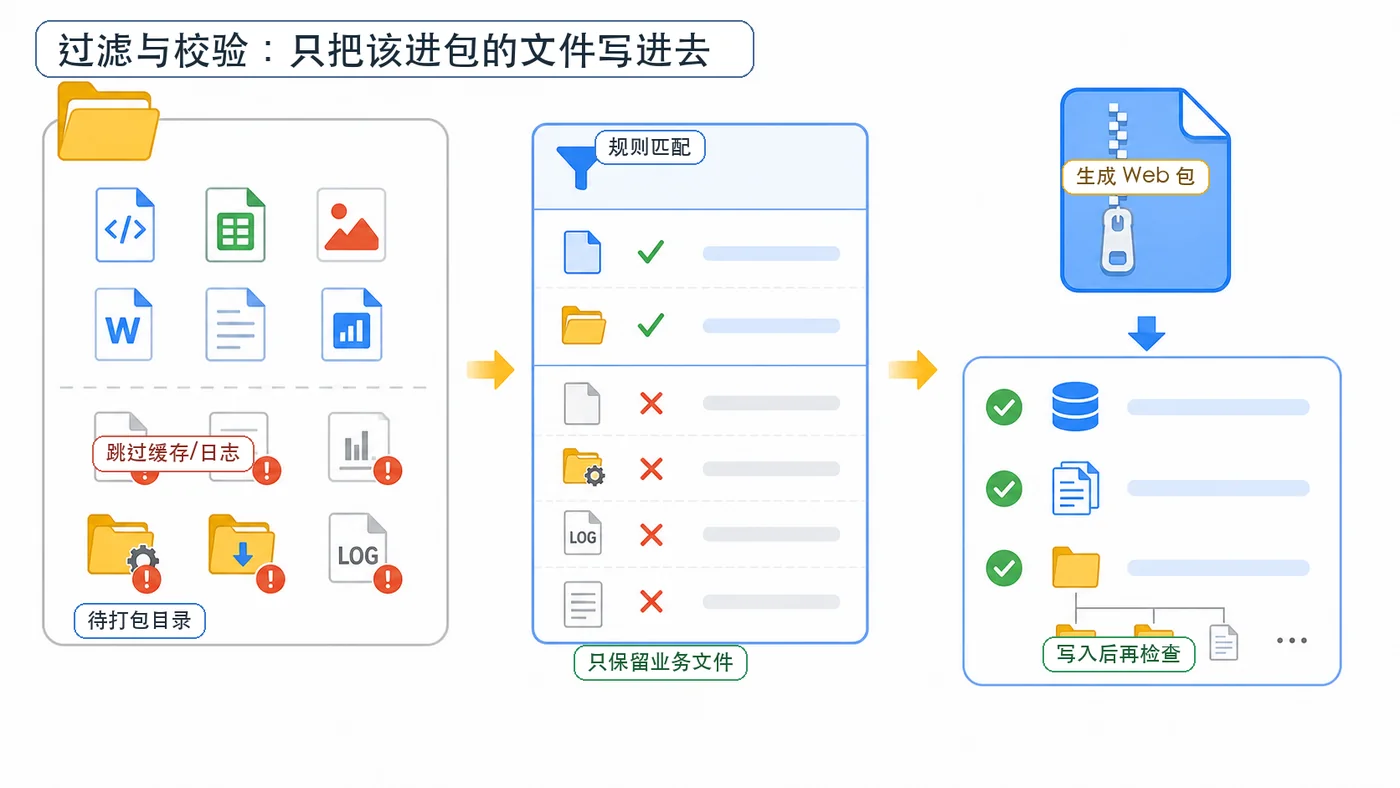
SKIP_DIR_NAMES = {"__pycache__", ".git", ".idea"}
SKIP_FILE_NAMES = {".DS_Store"}
SKIP_SUFFIXES = {".pyc", ".pyo", ".log", ".tmp"}
def should_keep(path: Path, source: Path, target: Path) -> bool:
if not path.is_file():
return False
if path.resolve() == target:
return False
relative_parts = path.relative_to(source).parts
if any(part in SKIP_DIR_NAMES for part in relative_parts):
return False
if path.name in SKIP_FILE_NAMES:
return False
if path.suffix.lower() in SKIP_SUFFIXES:
return False
return True
然后把 package_dir 改成使用这个判断函数:
def package_dir(source_dir: str, target_zip: str) -> int:
source = Path(source_dir).resolve()
target = Path(target_zip).resolve()
target.parent.mkdir(parents=True, exist_ok=True)
total = 0
with ZipFile(target, "w", ZIP_DEFLATED, compresslevel=6) as zf:
for path in sorted(source.rglob("*")):
if not should_keep(path, source, target):
continue
arcname = path.relative_to(source).as_posix()
zf.write(path, arcname)
total += 1
return total
注意 path.resolve() == target 这一行:如果你把压缩包输出到源目录里面,不加这条判断,脚本可能把刚生成的 zip 也写进 zip 包,造成结果越来越乱。
写入后做校验
打包结束后,不要只看文件存在就结束。至少应该重新打开压缩包,检查文件数量、部分路径,以及 testzip() 的 CRC 检查结果。
def inspect_zip(target_zip: str) -> dict:
target = Path(target_zip)
with ZipFile(target, "r") as zf:
bad_file = zf.testzip()
names = zf.namelist()
return {
"file_count": len(names),
"bad_file": bad_file,
"first_names": names[:5],
"size_bytes": target.stat().st_size,
}
if __name__ == "__main__":
zip_path = "release-web.zip"
count = package_dir("web_dist", zip_path)
info = inspect_zip(zip_path)
print(f"packed files: {count}")
print(f"zip files: {info['file_count']}")
print(f"bad file: {info['bad_file']}")
print(f"size bytes: {info['size_bytes']}")
print("first names:", info["first_names"])
如果 bad_file 不是 None,说明压缩包里有文件校验失败,需要重新生成或检查磁盘读写问题。如果 file_count 和脚本写入数量不一致,也要检查过滤规则或写入路径。
常见坑和优化建议
- 路径写成绝对路径:解压后会出现本机目录结构,应该使用
relative_to(source)。 - 输出包放在源目录里:一定要跳过目标 zip 自身,避免把压缩包写入压缩包。
- 过滤规则散落在循环里:建议集中到
should_keep(),后续新增规则更容易。 - 没有写后校验:至少检查
testzip()、数量和关键路径,别等交付后才发现包不完整。 - 超大目录一次性处理:可以先打印预计写入数量,或者按目录拆包,方便定位异常文件。
总结
用 Python zipfile 做批量打包,核心不是压缩这一行代码,而是把流程做完整:明确源目录,保留相对路径,过滤不该进包的文件,写完再校验。这样脚本既能用于临时打包,也能稳定放到日常构建和交付流程里。
 Go 问答:为什么接口变量明明装的是 nil,判断却不等于 nil
Go 问答:为什么接口变量明明装的是 nil,判断却不等于 nil
- 上一篇
- Go 问答:为什么接口变量明明装的是 nil,判断却不等于 nil
- 下一篇
- AI Agent 工具权限分级实战:读、写、发布三类操作怎么管
-
- 文章 · python教程 | 20小时前 | 日志 · 链路追踪 · Python教程 · contextvars · Python logging contextvars 日志追踪 trace_id 异步上下文
- Python 日志链路追踪实战:用 contextvars 自动带上 trace_id
- 370浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-
- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8144次使用
-
- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8572次使用
-
- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8397次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10306次使用
-
- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9193次使用
-
- GScript 编写标准库示例详解
- 2022-12-30 369浏览
-
- 关于Golang标准库flag的全面讲解
- 2023-02-25 344浏览
-
- Golang标准库unsafe源码解读
- 2022-12-29 464浏览
-
- 快速掌握Go语言HTTP标准库的实现方法
- 2022-12-30 327浏览
-
- 解析golang 标准库template的代码生成方法
- 2022-12-24 349浏览


