线上服务最讨厌的一类问题,不是每分钟都慢,而是偶尔卡一下。日志看起来一切正常,pprof 抓到的时候现场已经没了,等你想开 trace,事情早就过去了。Go 1.25 里的 Flight Recorder,解决的就是这个“案发现场留不住”的问题。
这篇我不写成发布说明翻译。我们站在后端服务排障视角聊:Flight Recorder 适合抓什么问题,怎么设置触发条件,怎么控制内存和文件大小,最后怎么用 go tool trace 找到真正卡住的 goroutine。
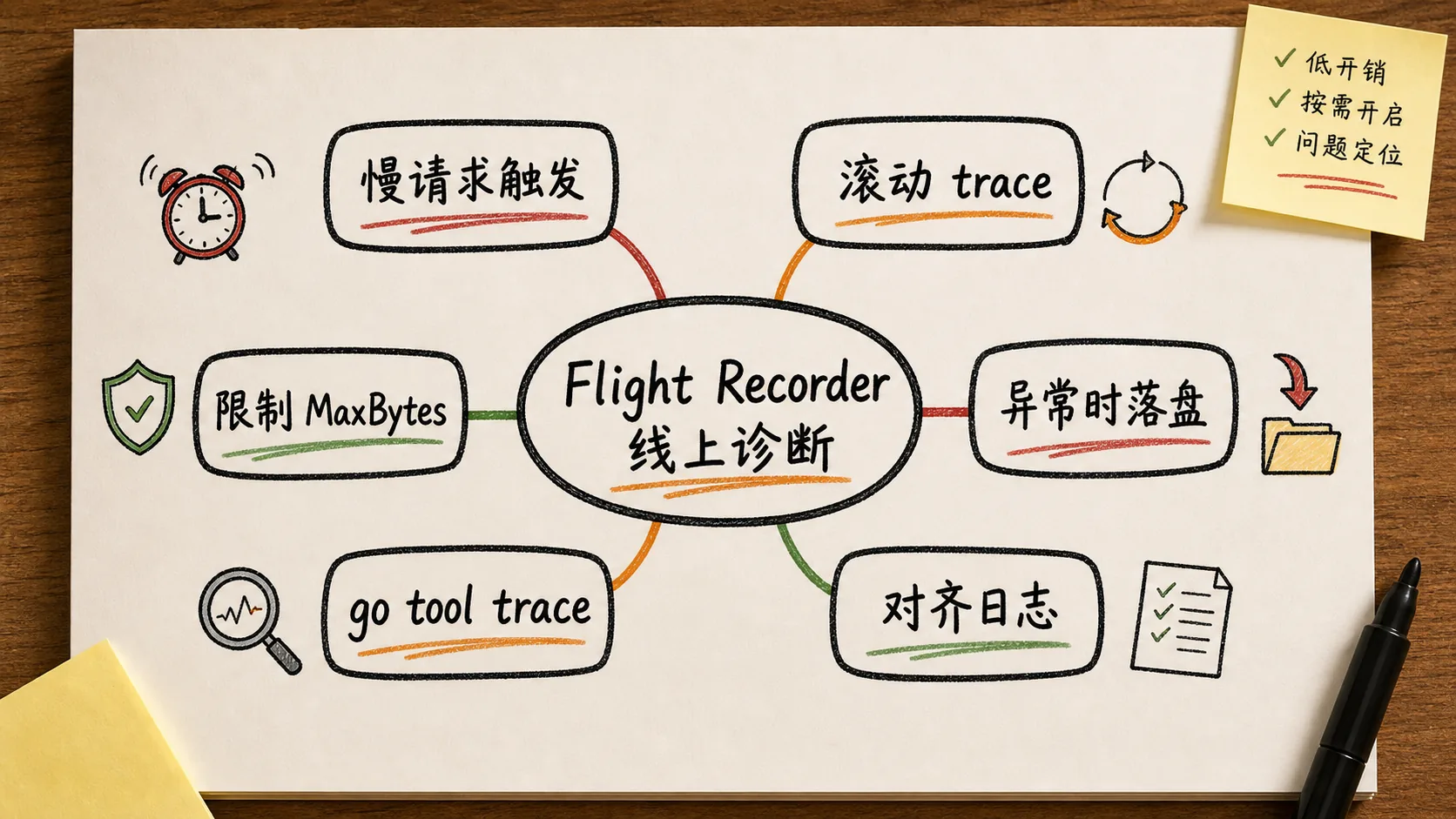
为什么光靠日志和 pprof 不够
日志回答的是“发生了什么业务事件”,pprof 更擅长回答“谁在消耗 CPU、内存、锁等待”。但偶发慢请求还有一个问题:你需要知道慢之前那几秒,goroutine 到底在运行、等待、唤醒还是被别的锁挡住。
普通 execution trace 很强,但长时间 Web 服务不可能从启动开始一直完整采集。数据量会很大,存储和分析成本也高。Flight Recorder 的思路更务实:在内存里滚动保存最近一小段 trace,只有当程序发现异常时才把这段现场快照写出来。
我会在哪些场景考虑它
第一类是慢请求:比如大部分请求 5ms,偶尔跳到 300ms,而且 pprof 看不到稳定热点。第二类是健康检查偶发超时:服务没挂,但调度或锁竞争短暂异常。第三类是后台任务把前台请求拖慢:比如统计任务、批量 flush、定时上报和主链路抢同一把锁。
这些问题有一个共同点:等你 SSH 上去再开工具,现场往往已经消失。Flight Recorder 的价值就是把“触发异常前的几秒”留下来。
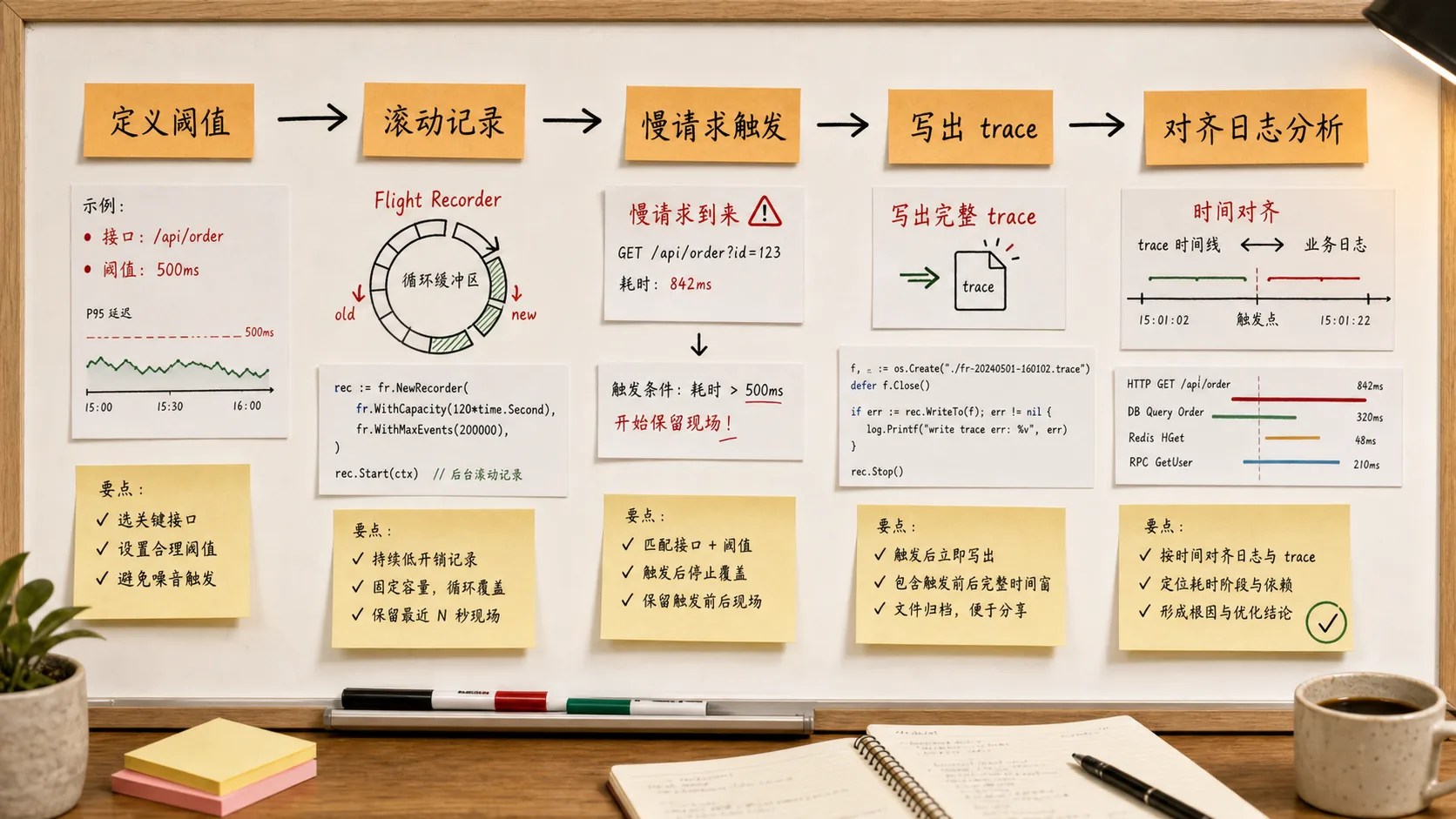
一个生产里更像样的接入方式
不要一上来就把所有请求都写 trace 文件。我的习惯是先定义触发条件,比如请求耗时超过 200ms,或者健康检查连续两次超过阈值。真正触发时只抓一次,避免故障期间疯狂写文件。
type Recorder struct {
fr *trace.FlightRecorder
once sync.Once
}
func NewRecorder() *Recorder {
fr := trace.NewFlightRecorder(trace.FlightRecorderConfig{
MinAge: 2 * time.Second,
MaxBytes: 32 << 20,
})
fr.Start()
return &Recorder{fr: fr}
}
func (r *Recorder) CaptureIfSlow(cost time.Duration) {
if cost < 200*time.Millisecond || !r.fr.Enabled() {
return
}
r.once.Do(func() {
go func() {
f, err := os.Create("slow-request.trace")
if err != nil {
slog.Warn("create trace failed", "err", err)
return
}
defer f.Close()
if _, err := r.fr.WriteTo(f); err != nil {
slog.Warn("write trace failed", "err", err)
return
}
r.fr.Stop()
}()
})
}
这里有几个细节别省:once 是为了防止大量慢请求同时触发;MaxBytes 是为了保护内存;写文件最好放到 goroutine 里,不要让慢请求在返回前继续背锅。
拿到 trace 后看什么
落盘之后,第一步通常是 go tool trace slow-request.trace。我会先看时间线里异常窗口附近有没有大段空白,再看 goroutine 是在 runnable、syscall、GC 相关等待,还是卡在同步原语上。
如果你能看到很多 goroutine 都被同一个 goroutine 的 unlock、channel send、timer 或网络返回唤醒,那就很接近真相了。这个时候不要急着改代码,先把调用栈、锁持有范围、慢请求时间点和业务日志对齐。

最容易踩的坑
第一个坑是阈值太低。你以为自己很谨慎,结果线上每分钟都触发,最后 trace 文件比业务日志还多。阈值应该从真实延迟分位出发,比如 P99 明显异常时再抓。
第二个坑是不限制体积。官方文章也提醒过,忙碌服务每秒可能产生几 MB 级别的 trace 数据。你必须用 MaxBytes 控制上限,别让诊断工具变成新的事故源。
第三个坑是只看截图不看调用栈。trace 时间线很直观,但真正能落到代码修改上的,往往是某个 goroutine 的栈、某个锁释放点,或者某个定时任务和请求路径之间的等待关系。
我的落地建议
- 先在预发环境接入,确认 trace 文件能生成、能下载、能用
go tool trace打开。 - 触发条件只选一两个高价值场景:慢请求、健康检查超时、后台任务超时。
- 文件名带上服务名、实例、时间、trace_id,别让排障时还要猜来源。
- 只抓一次或限频抓取,不要在故障期间无限制落盘。
- 把 Flight Recorder 当补充证据,不要替代 metrics、日志、pprof 和告警。
最后聊两句
Flight Recorder 让我比较喜欢的一点,是它很符合真实线上排障的节奏:问题不是一直发生,但你希望发生时能留下现场。它不是银弹,也不应该默认开得很激进,但对偶发延迟、锁竞争、调度异常这类问题,它能少走很多弯路。
我的建议是:别等事故来了再研究 trace。平时把触发条件、落盘目录、下载方式和分析流程走通,真到线上抖动那天,你才不会只能盯着日志说“再等等看”。
 Go pprof 排查慢接口:别只会看火焰图,先把问题问对
Go pprof 排查慢接口:别只会看火焰图,先把问题问对