sync.Pool 是我见过最容易被误会的 Go 工具之一。很多人一看到 Pool 就想做缓存,结果上线后命中率飘、数据被复用污染、GC 一来池子空了,还以为 Go runtime 在捣乱。它真正适合的是临时对象复用,不是业务缓存。
这篇我按线上接口压测和代码 review 的角度讲:什么时候值得用 sync.Pool,为什么 Get 后一定要 Reset,Put 后为什么不能再碰对象,以及怎么用 benchmark 证明它真的有收益。
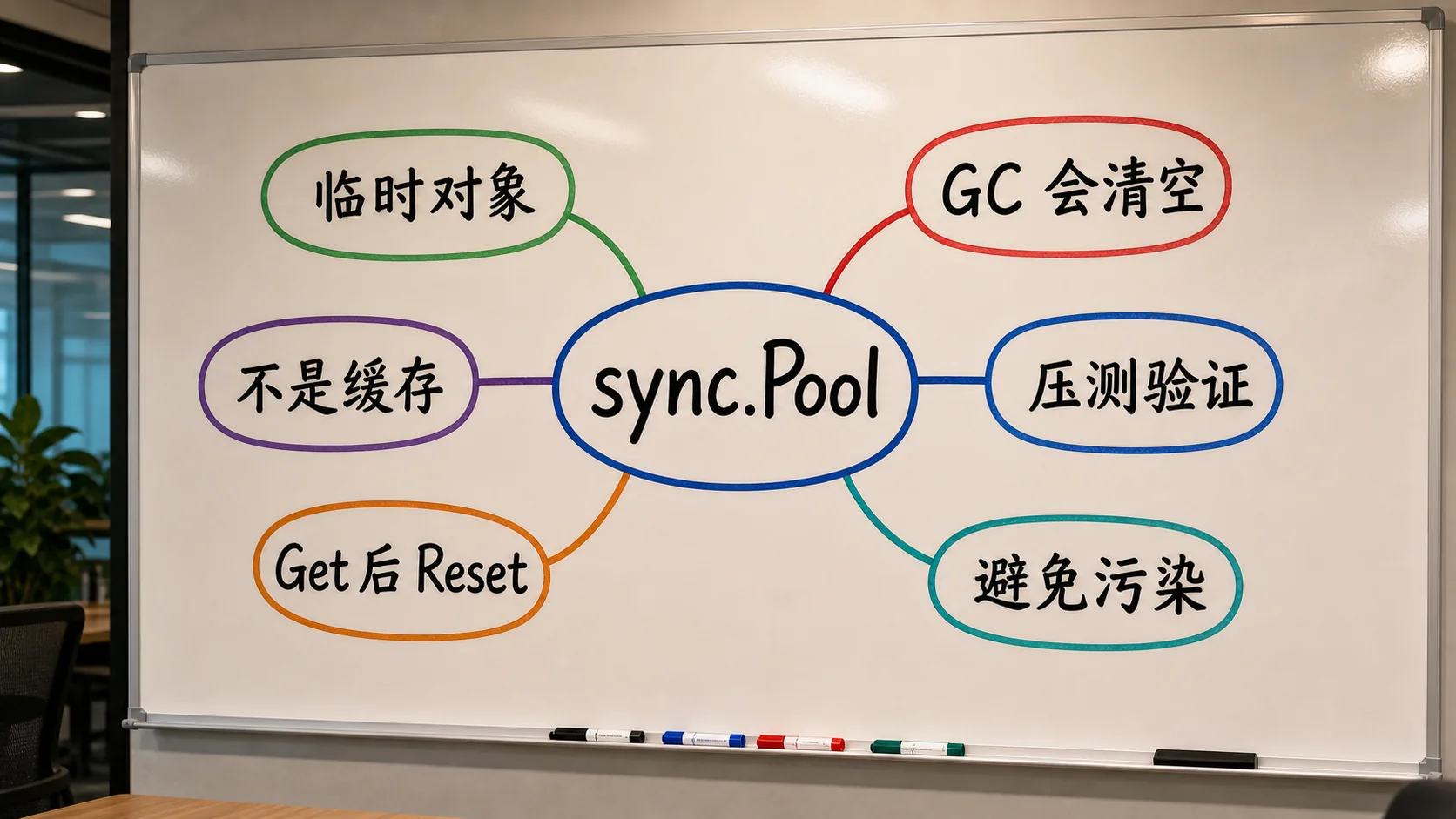
先把边界说清楚:它不是缓存
sync.Pool 里的对象随时可能被 GC 回收。你不能指望放进去的东西下次一定拿得到,也不能把业务状态、用户会话、连接对象这类有语义的数据塞进去。
它适合的是短生命周期、可丢弃、可重建、创建成本又不算低的临时对象。最典型的例子是 bytes.Buffer、临时 byte slice、编码解码中间对象、日志格式化缓冲区。
什么时候我会考虑 sync.Pool
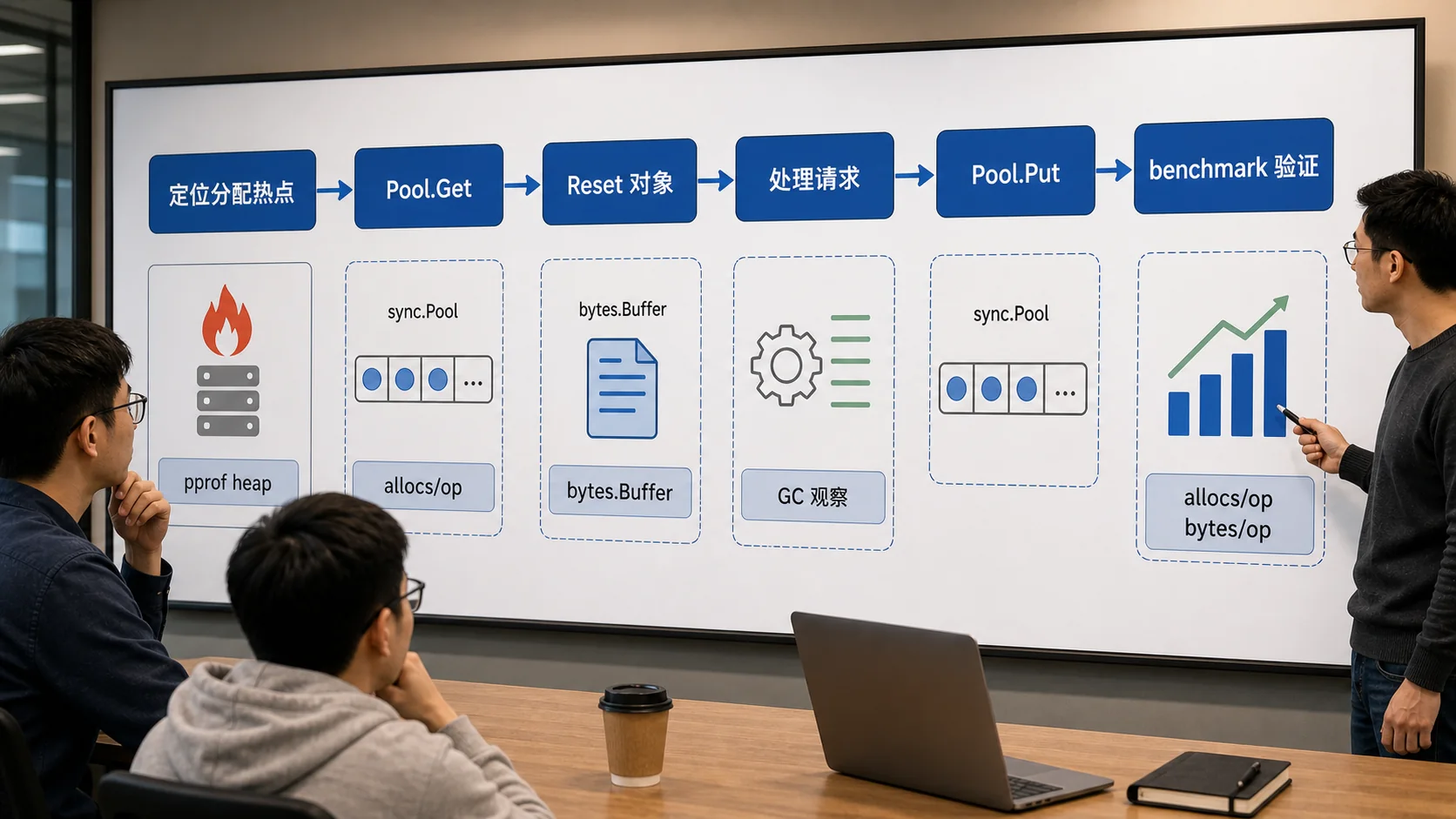
我一般不会在写第一版代码时就加 Pool。只有当 pprof 或 benchmark 告诉我某类临时对象分配很热,且对象能安全复用,我才会考虑。否则你很容易为了少量分配,换来更复杂的生命周期和隐藏 bug。
一个简单判断是:如果这个对象里有业务字段、有引用其他请求数据、有关闭资源的需求,那它大概率不适合进 Pool。Pool 里最好放“干净的工具对象”。
最容易漏掉的一步:Get 后 Reset
从 Pool 里拿出来的对象,很可能是上一个请求用过的。你不知道它里面残留了什么内容,所以第一步必须清理状态。比如 bytes.Buffer 要 Reset(),自定义结构体要把可变字段归零。
var bufPool = sync.Pool{
New: func() any {
return new(bytes.Buffer)
},
}
func Encode(v any) []byte {
buf := bufPool.Get().(*bytes.Buffer)
buf.Reset()
defer bufPool.Put(buf)
json.NewEncoder(buf).Encode(v)
return append([]byte(nil), buf.Bytes()...)
}
注意最后一行复制了一份结果。如果你直接返回 buf.Bytes(),然后又把 buf 放回 Pool,调用方拿到的 slice 可能被后续请求改掉。这类 bug 非常隐蔽。
Put 后别再用
对象一旦 Put 回 Pool,就不再属于当前 goroutine。你继续读写它,等于和未来某个请求共享状态。这个 bug 低并发下不一定暴露,高并发压测时才会随机出现脏数据。
我的习惯是把 Put 放在 defer 里,并确保 defer 后面没有再使用对象的代码。如果函数比较长,宁愿拆短一点,也不要让对象生命周期模糊。

GC 会清空 Pool,这不是 bug
sync.Pool 的设计目标就是帮助缓解临时对象分配压力,而不是保证命中率。GC 周期后,Pool 里的对象可能被清掉。你看到命中率波动,不一定是异常,而是它本来就这么设计。
所以别把 Pool 当成性能承诺。它只是在高分配压力下给 runtime 一个复用机会。真正能不能变快,要看分配是否减少、GC 压力是否下降、P99 是否改善。
benchmark 要看 allocs/op 和 B/op
验证 sync.Pool 不要只看 ns/op。有些场景平均耗时变化不大,但 allocs/op 和 B/op 下降明显,长时间跑线上会减少 GC 压力。也有些场景加了 Pool 反而变慢,因为对象太小、竞争太多或者 Reset 成本太高。
func BenchmarkEncode(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = Encode(sample)
}
}
我通常会同时看 go test -bench . -benchmem、benchstat、pprof heap,以及压测下的 GC 次数和 P99。只在本机跑一次 benchmark 就下结论,风险很大。
几个常见误用
- 把数据库连接、HTTP client、业务缓存对象放进 Pool。
- Get 后不 Reset,导致上一个请求的数据串到下一个请求。
- Put 后继续使用对象,造成并发污染。
- 为了追求“零分配”,把代码写得又绕又难维护。
- 没做压测,只凭感觉认为 Pool 一定更快。
我的 review 清单
- 这个对象是不是临时对象?丢了能不能无损重建?
- 是否有 pprof 或 benchmark 证明它是分配热点?
- Get 后有没有清理状态?自定义结构体字段是否归零?
- Put 后有没有继续引用对象、slice 或内部 buffer?
- Pool 里的对象是否携带用户数据、业务状态或外部资源?
- 上线后是否观察 GC、heap、P99,而不是只看平均耗时?
最后说句实在话
sync.Pool 是一个运行时友好的对象复用工具,不是让你手写内存管理。用对了,它能减少分配和 GC 压力;用错了,它会把请求之间的数据污染变成偶现线上事故。
我的建议很简单:先写清楚代码,再用数据证明分配真的热;确认对象可复用、可清理、可丢弃之后,再引入 Pool。性能优化最怕的不是少一个技巧,而是多一个没人敢改的黑盒。
参考资料:Go 标准库 sync.Pool 文档、runtime GC 行为说明、Go 官方性能诊断资料。
 Go channel 关闭原则:别让 close 变成并发代码里的隐形炸弹
Go channel 关闭原则:别让 close 变成并发代码里的隐形炸弹