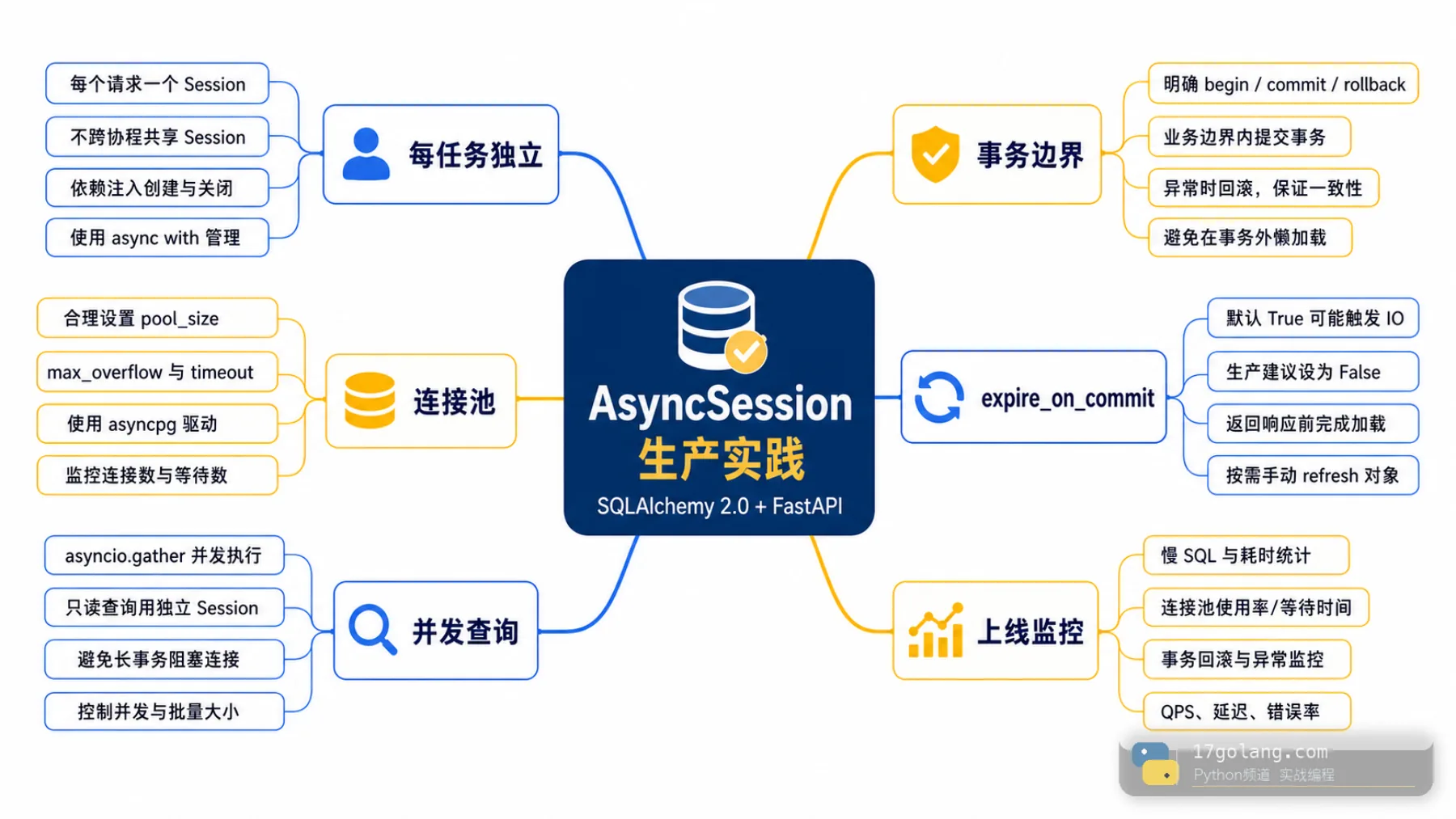
FastAPI 里接 SQLAlchemy async,最容易踩的坑不是语法,而是把 AsyncSession 当成“异步版连接池句柄”到处传。线上一旦并发上来,连接池等待、事务互相影响、偶发超时就会一起出现。
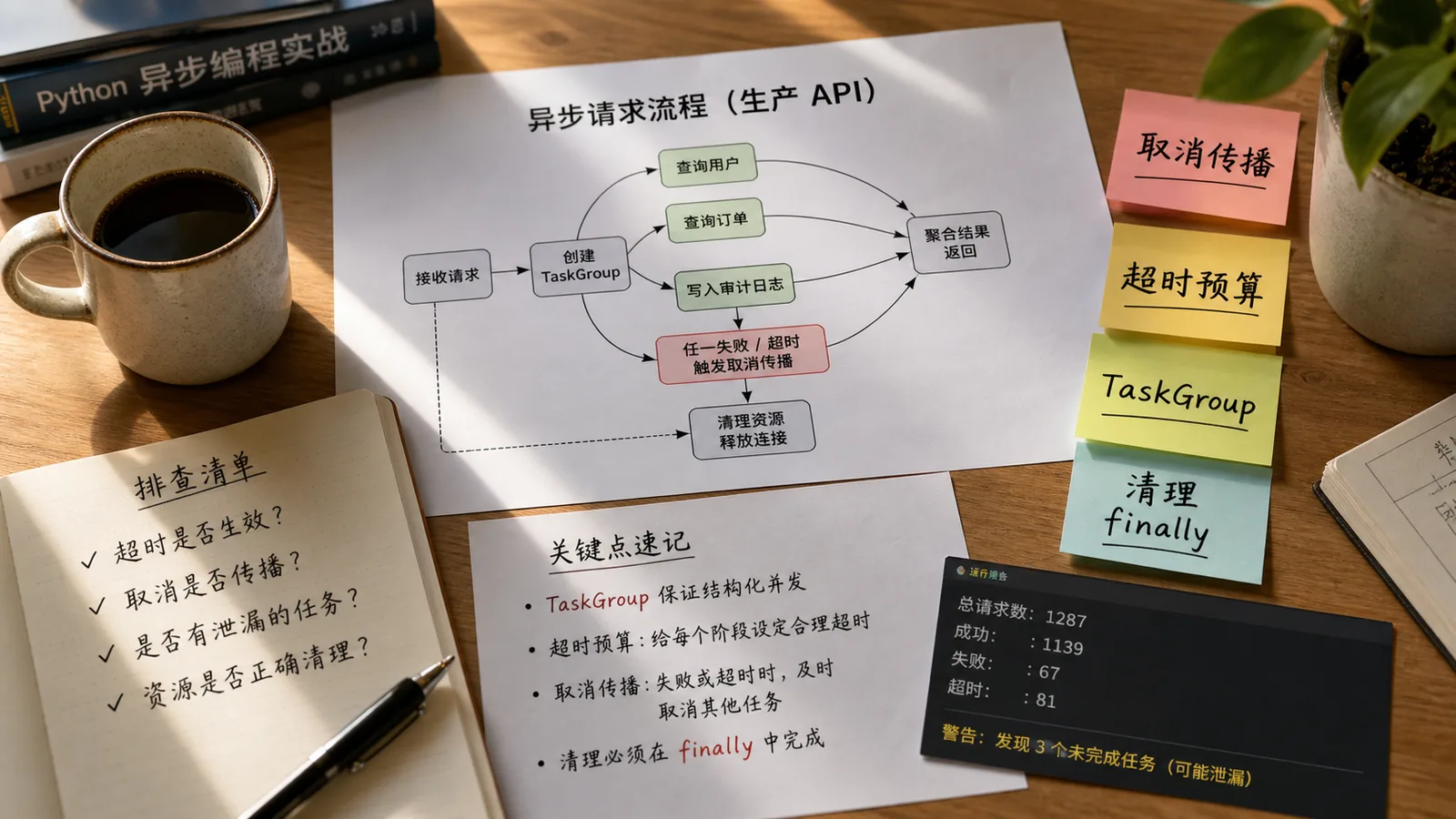
SQLAlchemy 官方文档对这件事说得很直白:AsyncSession 是有状态对象,代表一个事务单元;如果用 asyncio.gather() 这类方式并发跑多个任务,每个任务都应该使用独立 session。生产里我会把这条当成代码审查红线。
问题场景:一个请求里并发查多张表
订单详情接口常见写法是并发查用户、订单、库存、优惠券。很多人为了方便,把请求依赖注入进来的 session 直接传给多个协程。
async def detail(session: AsyncSession, order_id: int):
user, order, stock = await asyncio.gather(
load_user(session, order_id),
load_order(session, order_id),
load_stock(session, order_id),
)
return build_response(user, order, stock)
这段代码看着省事,但多个 task 正在共享同一个有状态事务对象。轻则连接占用时间变长,重则事务状态互相影响,异常发生时 rollback/commit 的边界也会变模糊。
更稳的写法:每个并发任务拿自己的 session
async_session = async_sessionmaker(
engine,
expire_on_commit=False,
)
async def load_user(order_id: int):
async with async_session() as session:
return await query_user(session, order_id)
async def detail(order_id: int):
return await asyncio.gather(
load_user(order_id),
load_order(order_id),
load_stock(order_id),
)
这样每个 task 有自己的 session 和事务边界,连接什么时候获取、什么时候释放都更清楚。别担心“session 多了是不是浪费”,真正持有连接的是执行 SQL 的阶段;关键是连接池大小和事务耗时要配合压测。
expire_on_commit=False 为什么常见
异步场景里,commit 后对象属性如果过期,再访问可能触发隐式 I/O。很多 FastAPI 项目会把 expire_on_commit=False 放进 async_sessionmaker,避免响应组装阶段突然访问数据库。它不是性能魔法,只是让对象生命周期更可控。
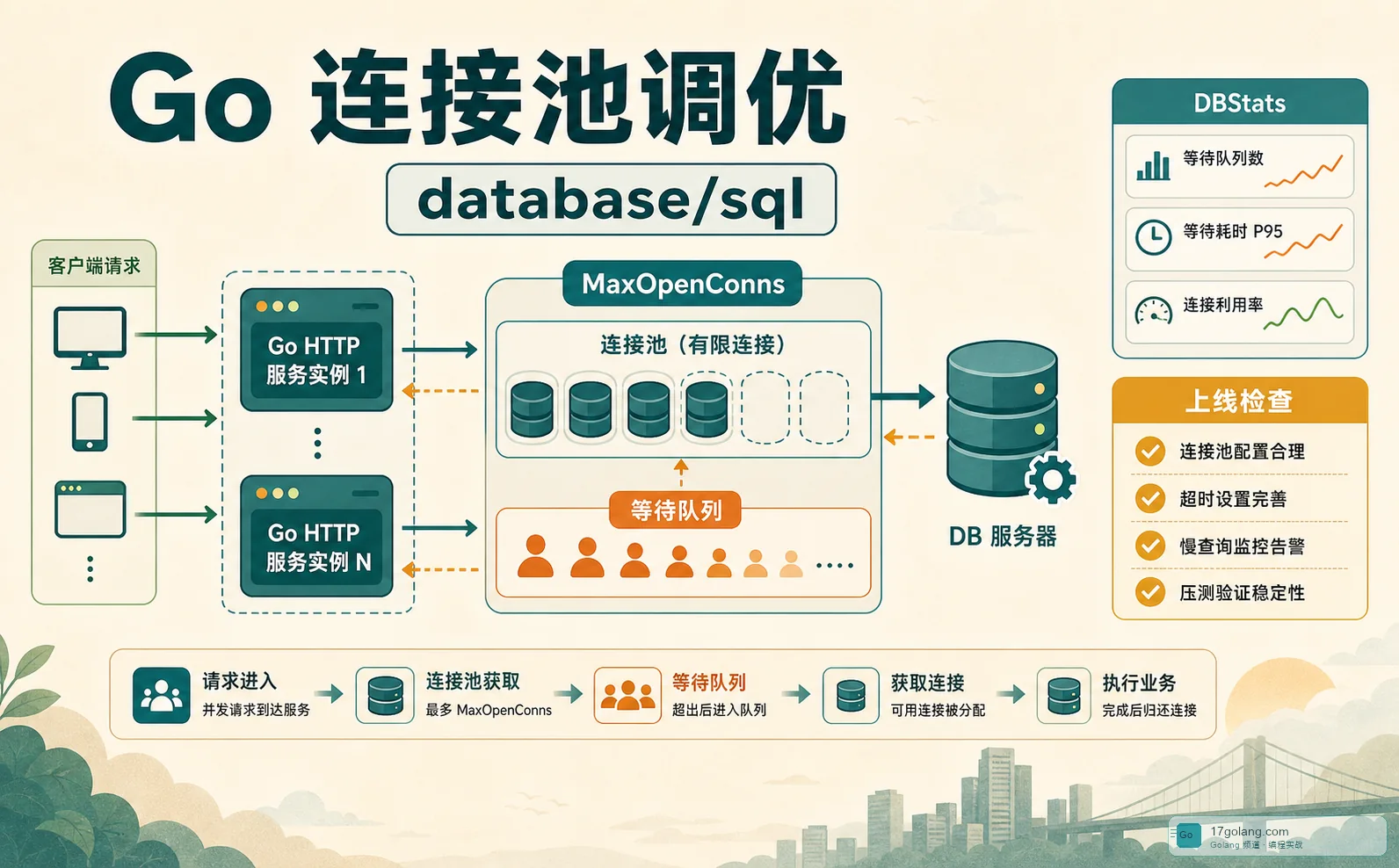
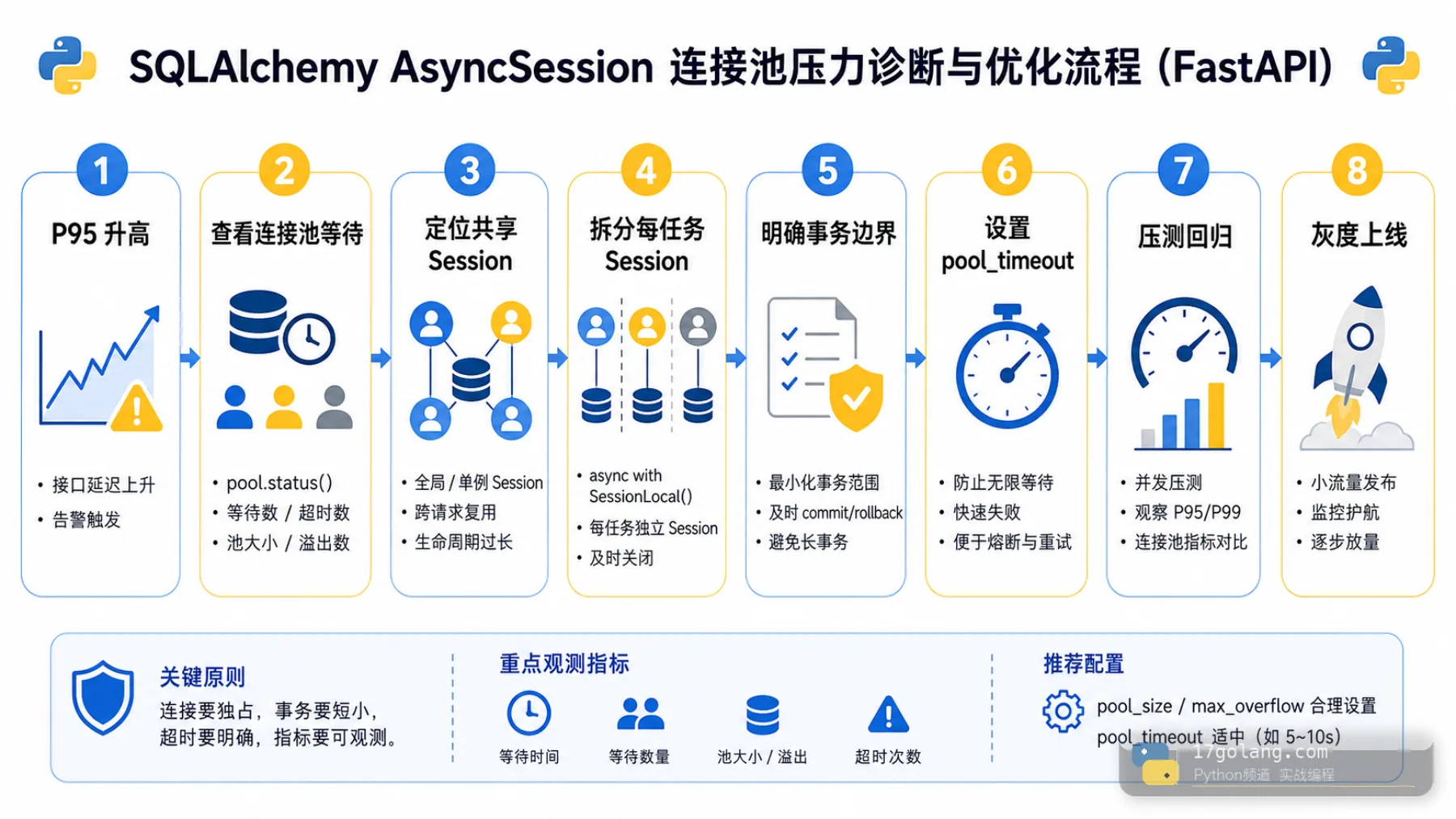
连接池参数要和业务一起看
pool_size、max_overflow、pool_timeout 不能拍脑袋。接口并发、单次事务耗时、慢 SQL 比例、数据库最大连接数,都要放在一起算。我的经验是先把慢查询和长事务压下去,再扩连接池;否则只是把问题推给数据库。

上线检查清单
- 有没有在
asyncio.gather的多个任务里共享同一个 AsyncSession? - 每个业务函数的事务边界是否能说清楚?
- 是否使用 async_sessionmaker 统一创建 session?
- 连接池等待、超时、慢 SQL、长事务是否有监控?
- 异常路径是否确保 rollback,并及时释放连接?
- 压测是否覆盖并发查询、失败回滚和数据库慢响应?
结语
AsyncSession 不是“随便共享的异步工具对象”,它背后有事务状态和连接生命周期。FastAPI 项目里,宁愿多写几行 session factory,也不要让一个 session 在多个 task 之间乱跑。
把事务边界写清楚,把连接池等待监控起来,再用压测验证,这才是 Python 异步数据库代码能稳定上线的底气。
 Go CrossOriginProtection 实战:别把 CSRF 防护只当成中间件
Go CrossOriginProtection 实战:别把 CSRF 防护只当成中间件