很多 Go 后端接口变慢,不是因为 goroutine 不够,也不是因为数据库突然不行了,而是 database/sql 连接池被我们配置成了“排队机”。MaxOpenConns 太小,请求排队;太大,数据库被打穿;没有 QueryContext,慢 SQL 会把连接长期占住。今天这篇按生产排障的方式,把 Go 连接池调优讲清楚。
先纠正一个老误会:sql.DB 不是单连接
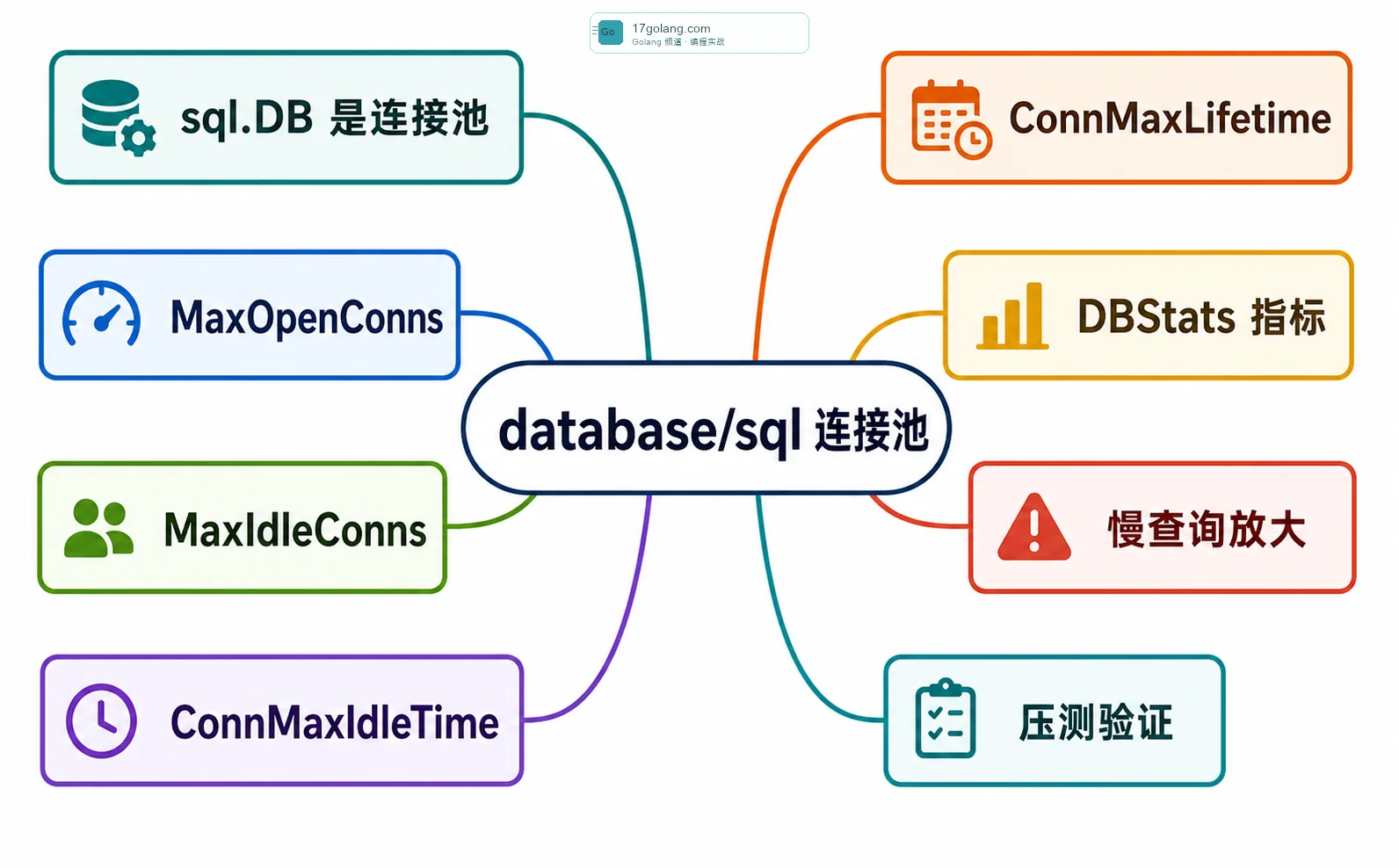
不少刚接触 Go 数据库开发的同学,会把 sql.DB 理解成“一条数据库连接”。这会直接带偏配置方式。官方文档说得很明确,sql.DB 是带连接池的数据库句柄,database/sql 会按需创建、复用和回收连接。你应该在服务里复用一个长生命周期的 sql.DB,而不是每次请求都 Open 一个。
线上真正难的是:这个池子到底开多大、留多少 idle、连接多久换一批、请求等连接时怎么被发现。连接池不是越大越好,它本质上是在 Go 服务和数据库之间加了一道限流阀。
一次常见事故:接口 P95 突然变成阶梯状
我见过一个订单列表接口,平时 P95 在 80ms,活动开始后突然变成 700ms 到 1.2s,而且延迟曲线像台阶一样往上爬。业务第一反应是 SQL 慢,DBA 看数据库 CPU 又不高。最后看 Go 侧 DBStats,WaitCount 和 WaitDuration 一直涨,说明大量请求不是卡在数据库执行,而是卡在等连接。
这个场景很典型:MaxOpenConns 设置得太小,慢查询又占着连接不放,新的请求只能在 Go 进程里排队。你从数据库看不到特别夸张的压力,但用户已经在接口层等疯了。
一套我常用的基础配置
下面这段不是万能参数,只是一个“有边界”的起点。真正数值要结合数据库最大连接数、服务实例数量、接口并发、SQL 耗时和压测结果来调。
func openDB(dsn string) (*sql.DB, error) {
db, err := sql.Open("mysql", dsn)
if err != nil {
return nil, err
}
db.SetMaxOpenConns(40)
db.SetMaxIdleConns(20)
db.SetConnMaxIdleTime(5 * time.Minute)
db.SetConnMaxLifetime(30 * time.Minute)
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
if err := db.PingContext(ctx); err != nil {
_ = db.Close()
return nil, err
}
return db, nil
}
MaxOpenConns 是最关键的上限。它限制这个 Go 进程最多同时打开多少数据库连接。MaxIdleConns 决定空闲时保留多少连接,太小会导致频繁建连,太大又会占着数据库资源。ConnMaxIdleTime 用来清理长时间不用的 idle 连接,ConnMaxLifetime 则适合应对数据库侧连接重启、负载均衡连接老化、云数据库连接生命周期这类问题。
MaxOpenConns 怎么估,不要拍脑袋
我的做法是先从数据库总连接预算倒推。假设数据库允许业务使用 400 个连接,你有 8 个服务实例,先别一上来每个实例给 100。你还要给管理工具、迁移任务、只读实例、突发扩容留余地。一个更稳的起点可能是每实例 30 到 40,然后靠压测和 DBStats 调整。
如果 MaxOpenConns 设置后 WaitCount 快速上涨,并且 WaitDuration 也明显增加,说明连接上限正在影响请求。此时不要立刻加大连接池,先确认是不是某些慢 SQL 占着连接太久。连接池只能控制并发,不能治疗慢查询。
查询必须带 Context,否则排队会被放大
连接池调优里最容易被漏掉的是超时。没有 QueryContext 的请求,一旦下游慢了,就可能长时间占着连接。连接被占满后,后续请求排队,接口延迟就会从“一个慢 SQL”扩散成“整个接口族变慢”。
func listOrders(ctx context.Context, db *sql.DB, uid int64) ([]Order, error) {
ctx, cancel := context.WithTimeout(ctx, 800*time.Millisecond)
defer cancel()
rows, err := db.QueryContext(ctx, `
select id, status, amount, created_at
from orders
where user_id = ?
order by id desc
limit 50`, uid)
if err != nil {
return nil, err
}
defer rows.Close()
var orders []Order
for rows.Next() {
var o Order
if err := rows.Scan(&o.ID, &o.Status, &o.Amount, &o.CreatedAt); err != nil {
return nil, err
}
orders = append(orders, o)
}
return orders, rows.Err()
}
注意这里的 context 不是装饰品。它既限制等待连接的时间,也限制查询执行时间。超时后要把错误打清楚,区分是 ctx deadline、数据库错误、还是 rows scan 出错。排障时这几个原因完全不同。

DBStats 是你判断连接池的仪表盘
如果只看数据库 QPS 和接口 P95,你很难判断瓶颈在 SQL 执行还是 Go 侧排队。DBStats 里最值得盯的是 OpenConnections、InUse、Idle、WaitCount、WaitDuration。WaitCount 增长,说明请求拿连接时等过;WaitDuration 增长,说明等连接的总时间在变大。
func exportDBStats(db *sql.DB) {
s := db.Stats()
log.Printf("db open=%d inuse=%d idle=%d wait=%d wait_duration=%s max_idle_closed=%d lifetime_closed=%d",
s.OpenConnections,
s.InUse,
s.Idle,
s.WaitCount,
s.WaitDuration,
s.MaxIdleClosed,
s.MaxLifetimeClosed,
)
}
生产里我会把这些指标上报到监控系统,至少按服务、库名、实例维度打出来。看到 InUse 长时间贴近 MaxOpenConns,同时 WaitDuration 增长,就要开始查慢 SQL、连接泄漏、事务没提交、rows 没 Close、连接池上限是否太保守。
几个很容易踩的坑
- 每次请求都 sql.Open,会制造多个连接池,最后把数据库连接数打爆。
- 忘记 rows.Close,会让连接迟迟回不到池里,高峰时排队越来越严重。
- 事务里夹太多业务逻辑,会把连接占用时间拉长,连带拖慢其他请求。
- MaxOpenConns 设置很大但数据库 max connections 很小,会把压力直接推给数据库。
- 只调连接池不看慢 SQL,本质是在调排队规则,不是在解决根因。
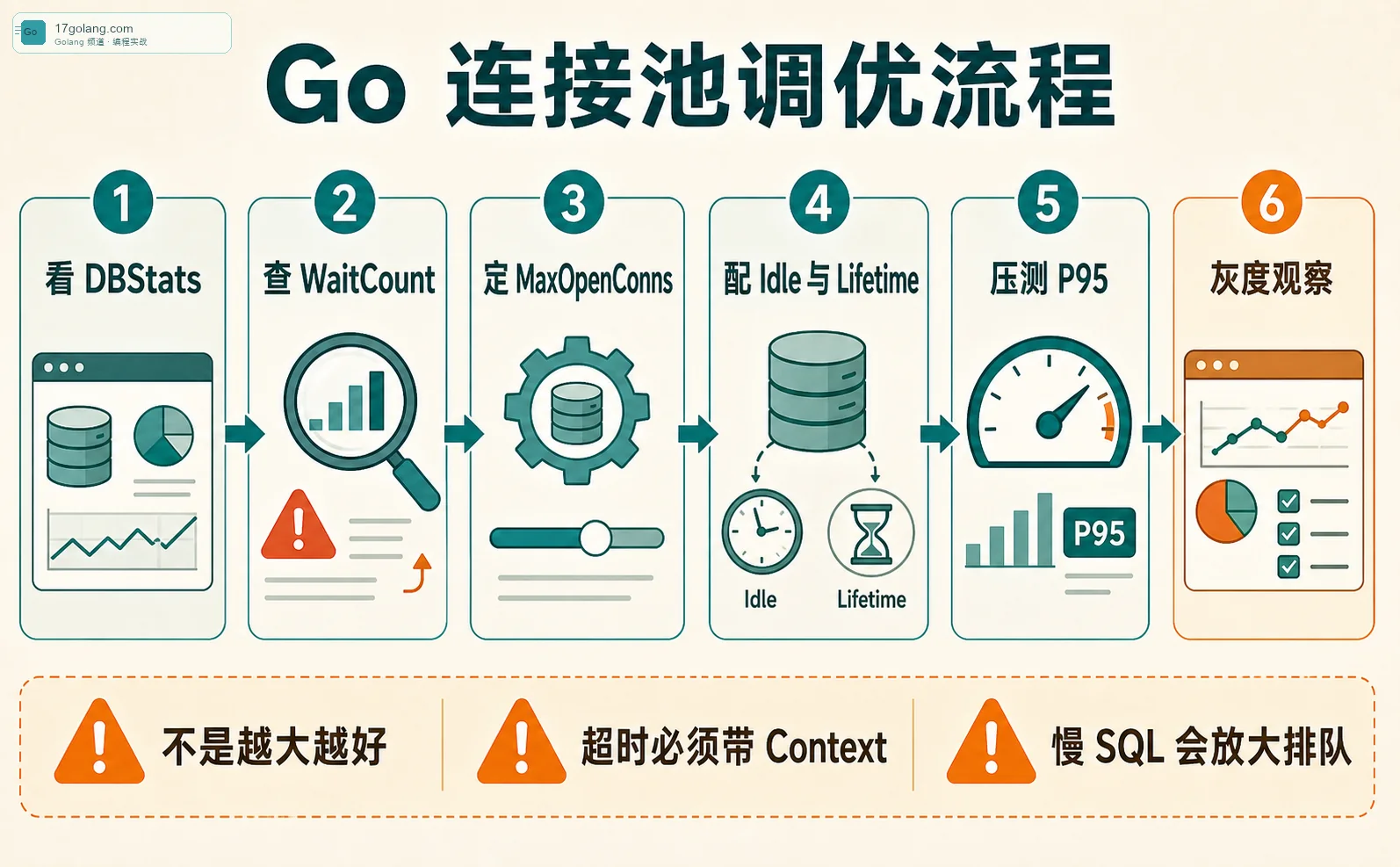
上线前我会怎么验证
第一步,压测正常流量,记录 P50、P95、P99、OpenConnections、InUse、WaitCount、WaitDuration。第二步,人为制造一个慢 SQL 或慢下游,看 QueryContext 能不能及时收住。第三步,调整 MaxOpenConns,观察数据库 CPU、活跃连接、Go 侧等待时间是否一起改善。第四步,灰度一小部分实例,看连接数是否按预期收敛。
我还会专门检查 release 窗口。连接池调优很容易在低峰看起来完美,高峰才露问题。不要只在本地跑 benchmark,然后直接全量上线。连接池参数是生产系统的一部分,不是配置文件里随便填的数字。
最后聊两句
Go 的 database/sql 已经把连接池能力放在标准库里了,真正难的是理解它背后的排队行为。MaxOpenConns 控制的是并发入口,Context 控制的是等待边界,DBStats 告诉你瓶颈是不是在池子里。
我的建议很朴素:一个服务复用一个 sql.DB;每个查询都带 Context;连接池参数从数据库预算倒推;用 DBStats 和压测说话;发现 WaitCount 上涨时先查慢 SQL 和连接泄漏。做到这些,连接池就不再是玄学配置,而是能解释、能验证、能上线的工程决策。
 Python SQLAlchemy AsyncSession 实战:别在并发任务里共享 Session
Python SQLAlchemy AsyncSession 实战:别在并发任务里共享 Session