Flask 项目小的时候,很多写法看起来都没问题:模块顶层连数据库、到处读环境变量、后台线程里顺手用 request,视图函数里临时拼配置。等服务上了多进程、多线程和灰度发布,问题就开始冒出来:连接泄漏、配置不一致、请求对象跨线程失效、偶发的“working outside of request context”。
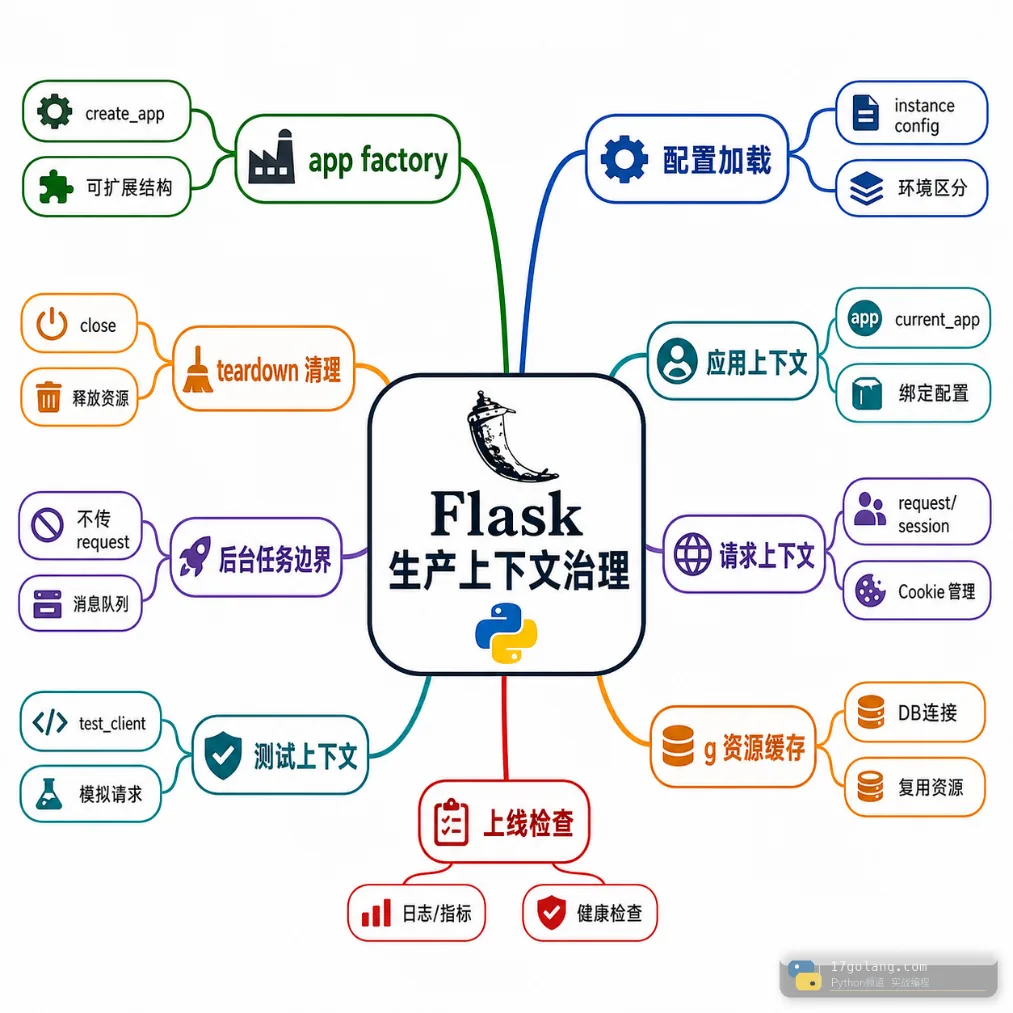
这篇文章不写 Flask 入门,而是按生产排障视角讲清楚:Flask 的应用上下文和请求上下文到底该怎么用,为什么 g 适合请求内资源缓存,为什么资源释放要交给 teardown,配置为什么要集中到 app factory,而不是散落在代码各处。
业务场景:订单接口偶发连接耗尽
假设一个 Flask 订单服务最开始只有几个接口,开发为了省事,把数据库连接放在模块全局变量里。测试环境一切正常,上线后跑在多 worker 下,连接数开始莫名上涨。
# app.py
from flask import Flask, jsonify
app = Flask(__name__)
db = connect_db(app.config["DATABASE_URL"])
@app.get("/orders")
def orders():
rows = db.query("select * from orders limit 20")
return jsonify([dict(row) for row in rows])
这个写法最大的问题是生命周期不清楚:连接什么时候创建、被哪个进程持有、失败后怎么重建、请求结束后是否释放,都没有统一答案。Flask 给我们的上下文机制,就是用来把这些边界管清楚的。
先分清两层上下文
Flask 里常用的 current_app、g、request、session 都不是普通全局变量,它们是上下文局部对象。请求进来时,请求上下文和应用上下文被推入;请求结束后,再按顺序清理。
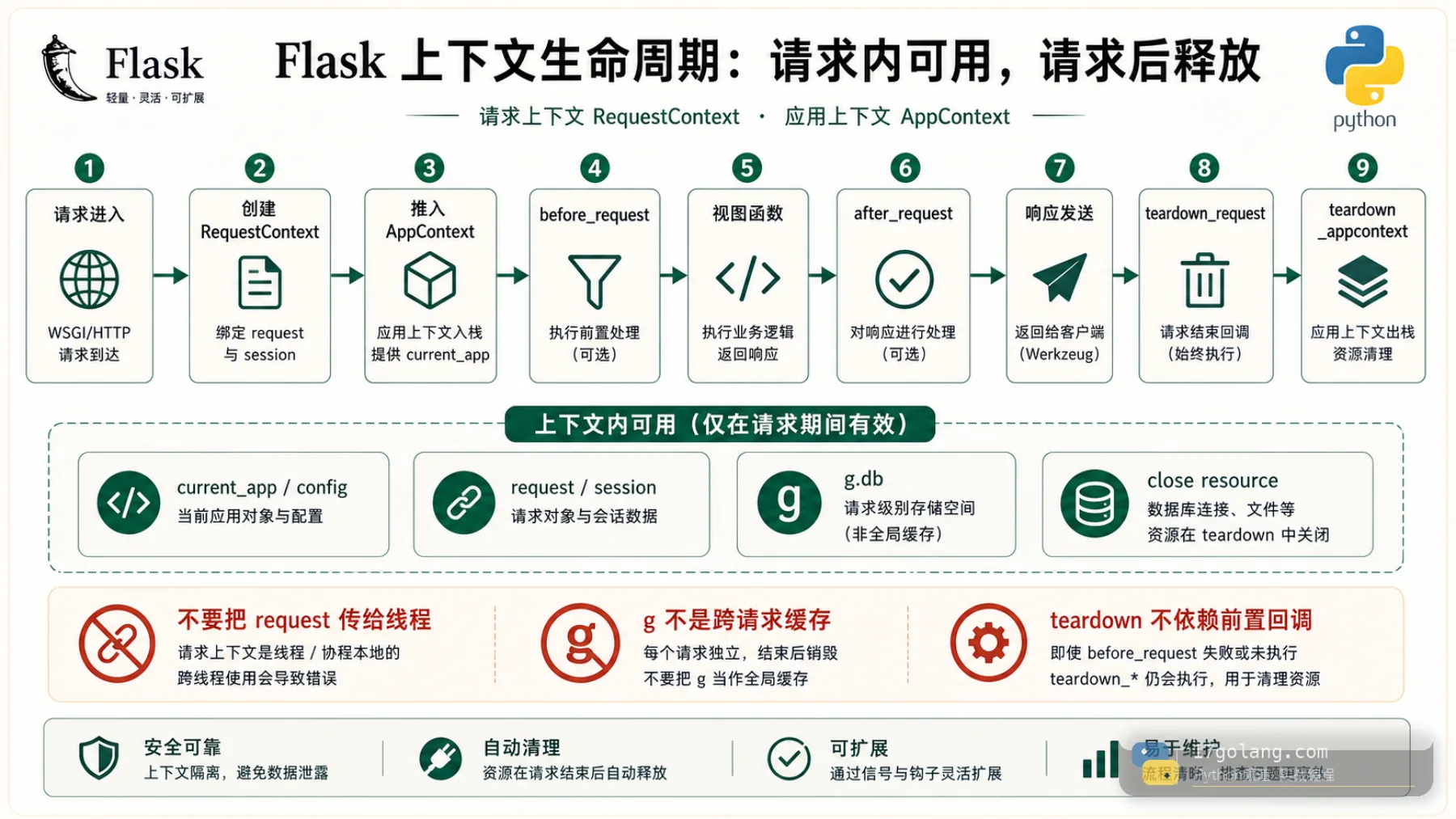
理解这一点后,就不会把 request 传给后台线程,也不会把 g 当跨请求缓存。它们的价值是“请求内稳定可用,请求后自动释放”,不是让你绕开参数传递。
用 app factory 收口配置
生产项目里,我更倾向用 create_app 创建应用,并在里面集中加载配置。默认配置、实例目录配置、环境变量、命令行覆盖,各有优先级,但不要在业务代码里到处读取。
# app_factory.py
from flask import Flask
def create_app(config_object: str | None = None) -> Flask:
app = Flask(__name__, instance_relative_config=True)
app.config.from_mapping(
DATABASE_URL="sqlite:///local.db",
REQUEST_TIMEOUT=2.0,
)
app.config.from_pyfile("config.py", silent=True)
if config_object:
app.config.from_object(config_object)
register_routes(app)
register_teardown(app)
return app
这样做的好处是测试、开发、生产都能明确知道配置从哪里来。更重要的是,业务模块不再偷偷读取环境变量,排查“为什么这个 worker 配置不一样”时少很多噪音。
用 g 做请求内资源缓存
数据库连接、轻量客户端、一次请求内需要复用的对象,可以放到 g。它不是全局缓存,而是当前上下文中的临时存储。
from flask import current_app, g
def get_db():
if "db" not in g:
g.db = connect_db(current_app.config["DATABASE_URL"])
return g.db
@app.get("/orders")
def orders():
rows = get_db().query("select * from orders limit 20")
return jsonify([dict(row) for row in rows])
这个模式很适合“请求内复用,请求后释放”。同一次请求多次调用 get_db() 不会重复建连接;下一个请求会拿到新的上下文,不会共享上一次请求的临时状态。
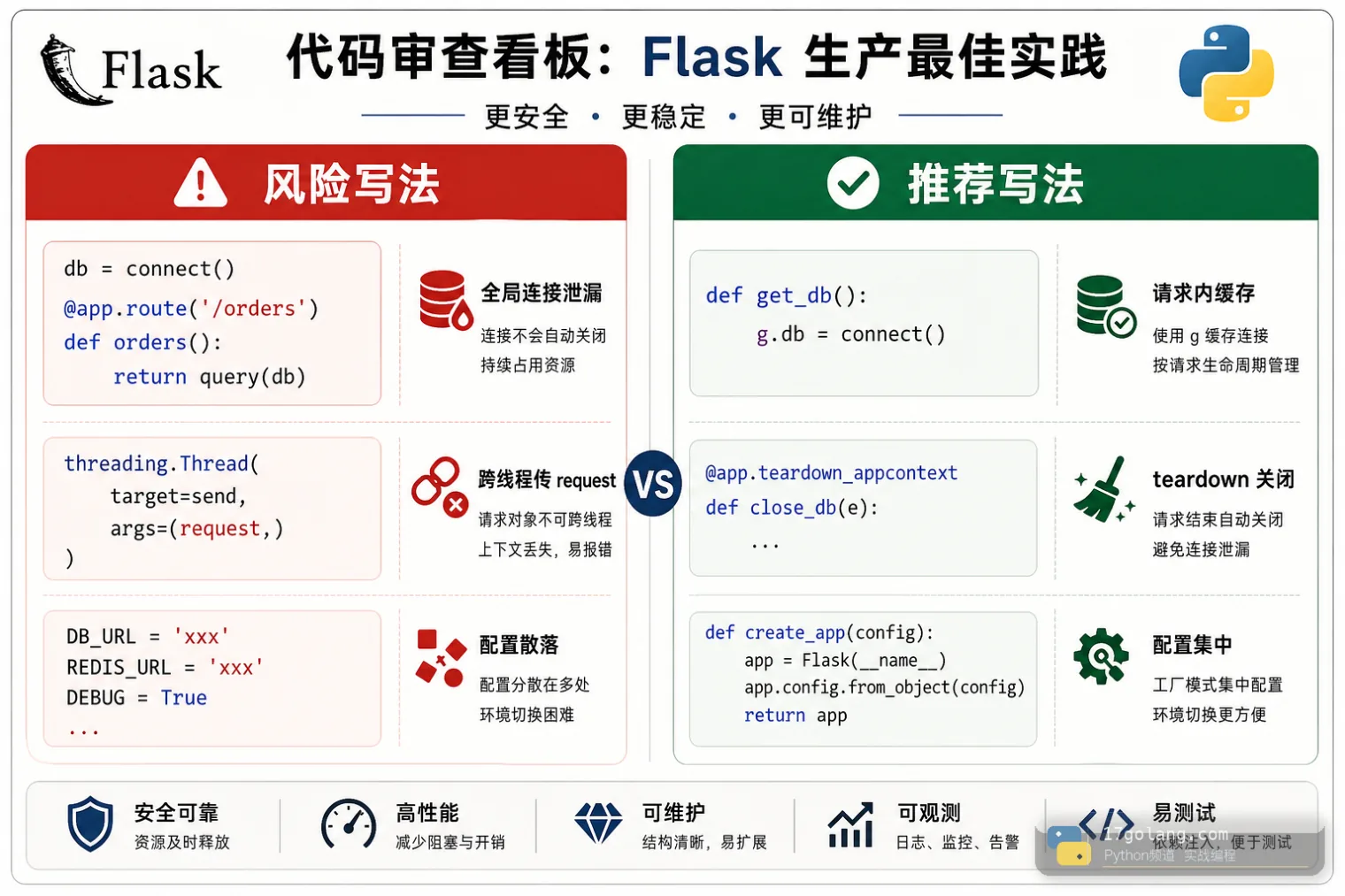
资源释放交给 teardown
只创建不关闭,是 Flask 小项目变成生产服务后最常见的坑。正确做法是注册 teardown 回调,让请求结束或应用上下文弹出时统一释放资源。
def close_db(error: BaseException | None = None) -> None:
db = g.pop("db", None)
if db is not None:
db.close()
def register_teardown(app: Flask) -> None:
app.teardown_appcontext(close_db)
注意 teardown 回调不应该假设前面的钩子一定执行成功。线上请求可能在路由前、视图中、响应构造时任意阶段失败,清理逻辑要写得幂等,拿不到资源就直接返回。
不要把 request 传给后台线程
有些接口响应后要发通知,于是有人把 request 或 current_app 直接塞给线程。这个写法很危险,因为请求上下文结束后,对象就不再处于可用边界内。
# 风险写法:后台线程使用请求上下文对象 threading.Thread(target=send_notice, args=(request,)).start()
更稳的做法是只提取必要的普通数据,比如用户 ID、请求 ID、业务参数,再交给队列或后台任务。关键任务还要有重试、幂等和告警,不要靠一个临时线程赌运气。
payload = {
"user_id": g.user_id,
"request_id": request.headers.get("X-Request-ID"),
}
enqueue_notice(payload)
诊断步骤:从上下文错误和连接数开始查
Flask 服务出现偶发上下文错误或连接数持续上涨,我通常按这个顺序查:
- 搜索模块级连接、模块级客户端、模块导入时读取配置的代码。
- 检查后台线程、定时任务、回调里是否直接使用
request、g、current_app。 - 检查数据库连接是否通过
g获取,并在 teardown 中关闭。 - 检查 teardown 是否幂等,异常请求是否也能释放资源。
- 用压测观察连接数、P99、错误率、请求 ID 日志是否连续。
上线检查清单
- 应用统一由
create_app创建,配置加载路径清晰可追踪。 - 业务代码不在模块导入阶段连接数据库或读取动态配置。
- 请求内资源通过
g缓存,避免重复创建。 - 资源释放统一注册到
teardown_appcontext,并保证幂等。 - 后台任务只接收普通数据,不接收
request、g等上下文对象。 - 测试覆盖
test_client、配置覆盖、异常请求下资源释放。 - 线上日志包含 request id,指标覆盖连接数、P99、异常类型和 teardown 错误。
总结
Flask 的轻量不是随便写的理由。它把很多边界交给工程师自己决定:应用怎么创建,配置从哪里来,请求内资源怎么复用,请求结束怎么清理,后台任务怎么脱离上下文。
我的经验是,Flask 项目越小,越要早点把这些规矩立住。app factory、g、teardown、集中配置并不复杂,但它们能让一个 Python 小服务在多进程、多线程和灰度发布里少很多隐性故障。
 MySQL 8.4 复制延迟排障:别只盯 Seconds_Behind_Source
MySQL 8.4 复制延迟排障:别只盯 Seconds_Behind_Source