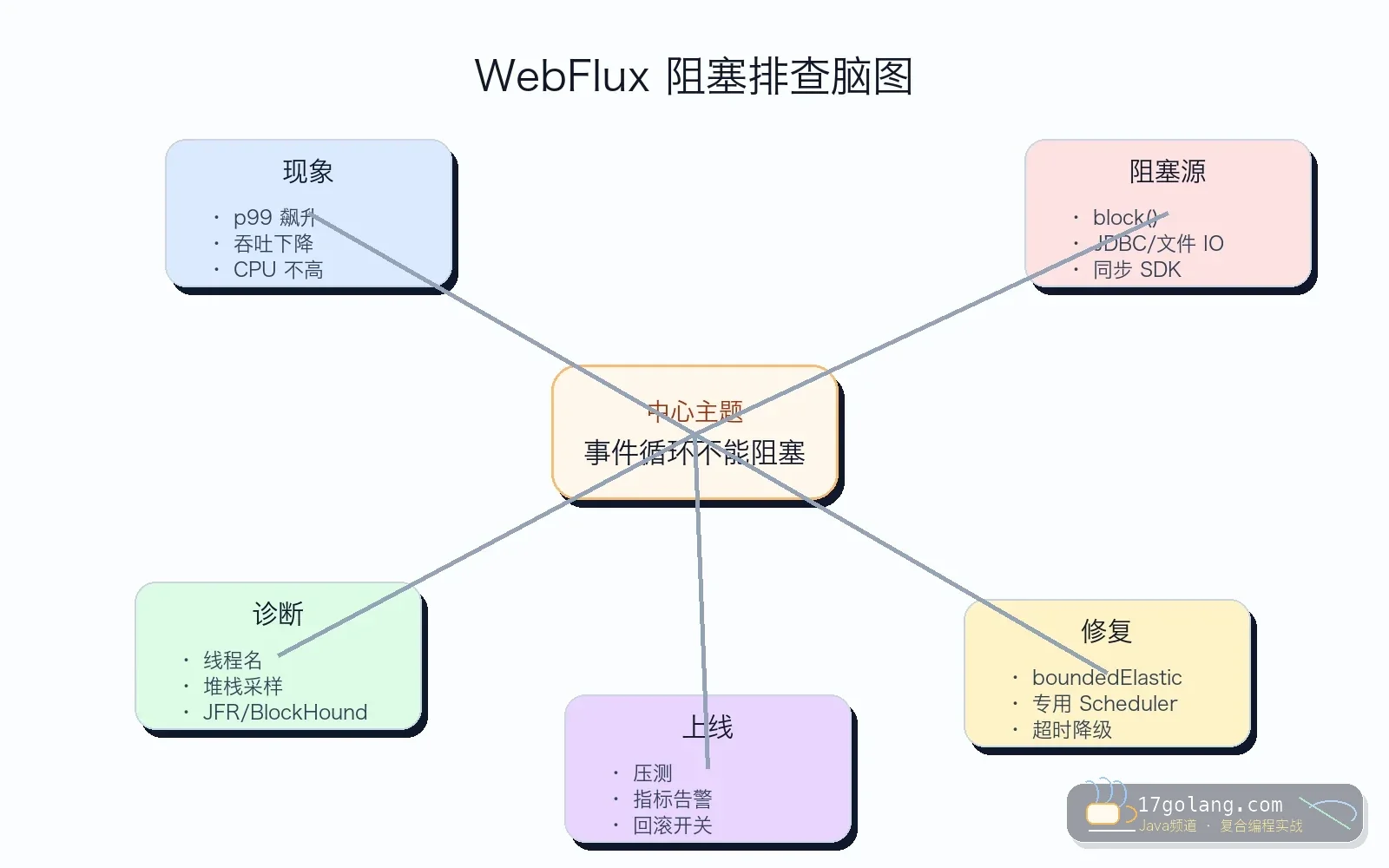
这篇写一个我见过很多次的 Java 线上问题:服务已经换成 Spring WebFlux,看起来是非阻塞架构,但一次促销流量进来,接口 p99 从一百多毫秒飙到四五秒,CPU 却不高。最后查到不是 Netty 不行,也不是 Reactor 神秘变慢,而是几个同步阻塞调用悄悄跑进了事件循环。
本文适用于 Java 17/21、Spring Boot 3.x、Spring WebFlux、Reactor Netty 场景。资料只用来核对事实:Spring WebFlux 建立在非阻塞运行时之上,Reactor 对同步阻塞源推荐放到专门调度器上执行。正文按生产复盘写,不照搬官方文档。
业务场景:一个订单详情接口把整组 EventLoop 拖慢
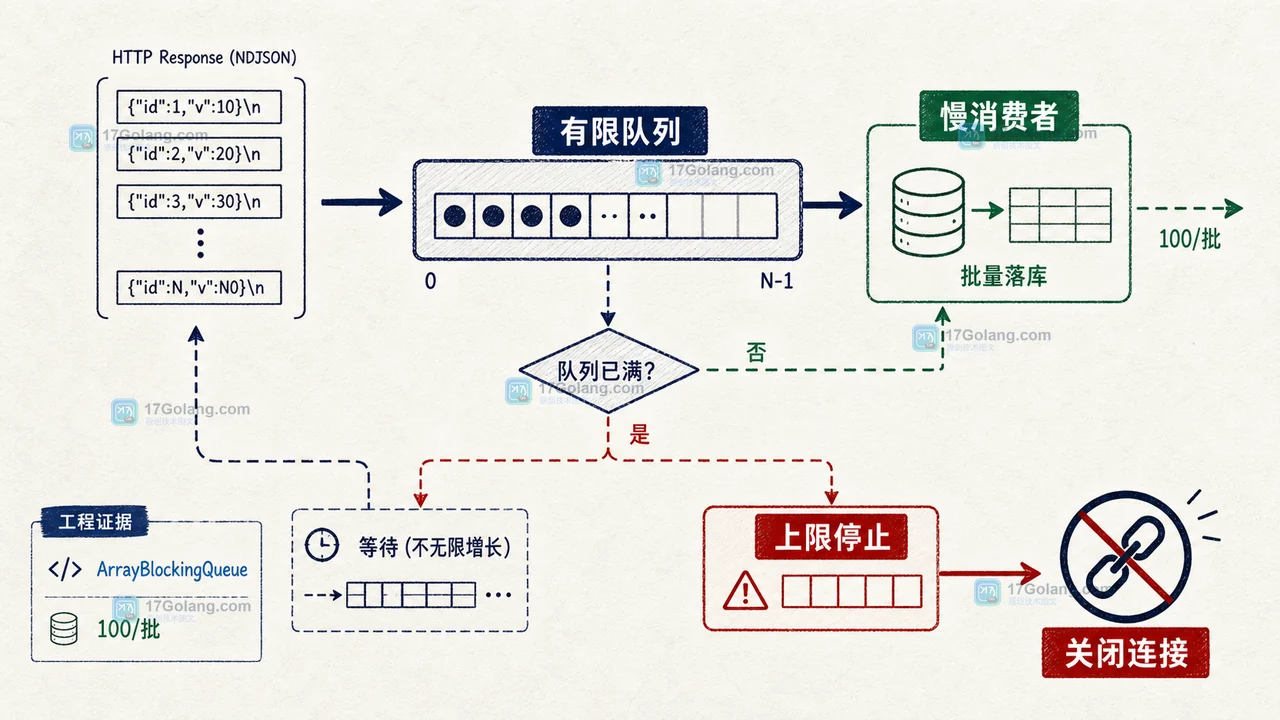
订单详情接口本身不复杂:查订单、查库存、拼一个 VO 返回。团队为了提升并发,把控制器改成了 Mono,压测低并发时数据不错。问题出在真实流量里:库存服务偶发 200ms 抖动,订单查询偶发慢 SQL,两个慢点叠在一起后,reactor-http-nio-* 线程开始排队。
最迷惑人的地方是 CPU 不高,内存也不爆,日志只有少量超时。很多人第一反应会怀疑数据库、网关、机器规格,但 WebFlux 场景下要先问一句:有没有阻塞调用跑在 EventLoop 上?
问题复现:小流量没事,高峰突然扩散
我通常会先做一个最小复现:把下游库存接口人为延迟 200ms,再用压测工具打订单详情。只要在事件循环里直接做 JDBC 查询、文件 IO、Thread.sleep、CompletableFuture#get 或 Mono#block,p99 会很快扩大,而且同一个 EventLoop 上的其他请求也会被连带拖慢。
这不是“WebFlux 性能差”,而是非阻塞模型里最基础的契约被破坏了:EventLoop 应该快速接收、分发、回调,不能被某个业务请求长期占住。
踩坑原因:返回 Mono 不等于全链路非阻塞
很多线上事故都卡在这个误区:方法签名变成 Mono,并不代表里面的代码自动非阻塞。你在 map 里查 JDBC,在 controller 方法里调用同步 SDK,在响应式链路里 block(),本质还是占住当前线程等结果。
如果这条链路运行在 reactor-http-nio 线程上,影响会比普通 Servlet 线程池更明显。Servlet 阻塞通常消耗的是请求线程;WebFlux 事件循环被阻塞时,拖住的是一批连接的调度入口。
代码案例:把阻塞源隔离出去
下面这个例子很贴近真实项目。左边的代码语法没错,单元测试也能过,但上生产就危险;右边不是万能模板,但它表达了几个关键动作:识别阻塞源、放到合适调度器、设置超时、让失败路径可控。

public Monodetail(String id) { Mono orderMono = Mono.fromCallable(() -> orderRepository.findById(id)) .subscribeOn(Schedulers.boundedElastic()) .timeout(Duration.ofMillis(300)); Mono stockMono = stockClient.query(id) .timeout(Duration.ofMillis(200)); return Mono.zip(orderMono, stockMono) .map(tuple -> toVO(tuple.getT1(), tuple.getT2())) .doOnError(ex -> log.warn("order detail failed, id={}", id, ex)); }
如果阻塞调用非常重,我更偏向给它单独建一个有名字、有上限的 Scheduler,而不是所有东西都扔进 boundedElastic。例如报表导出、老系统 SOAP SDK、图片处理这类调用,最好按业务域隔离,方便限流和告警。
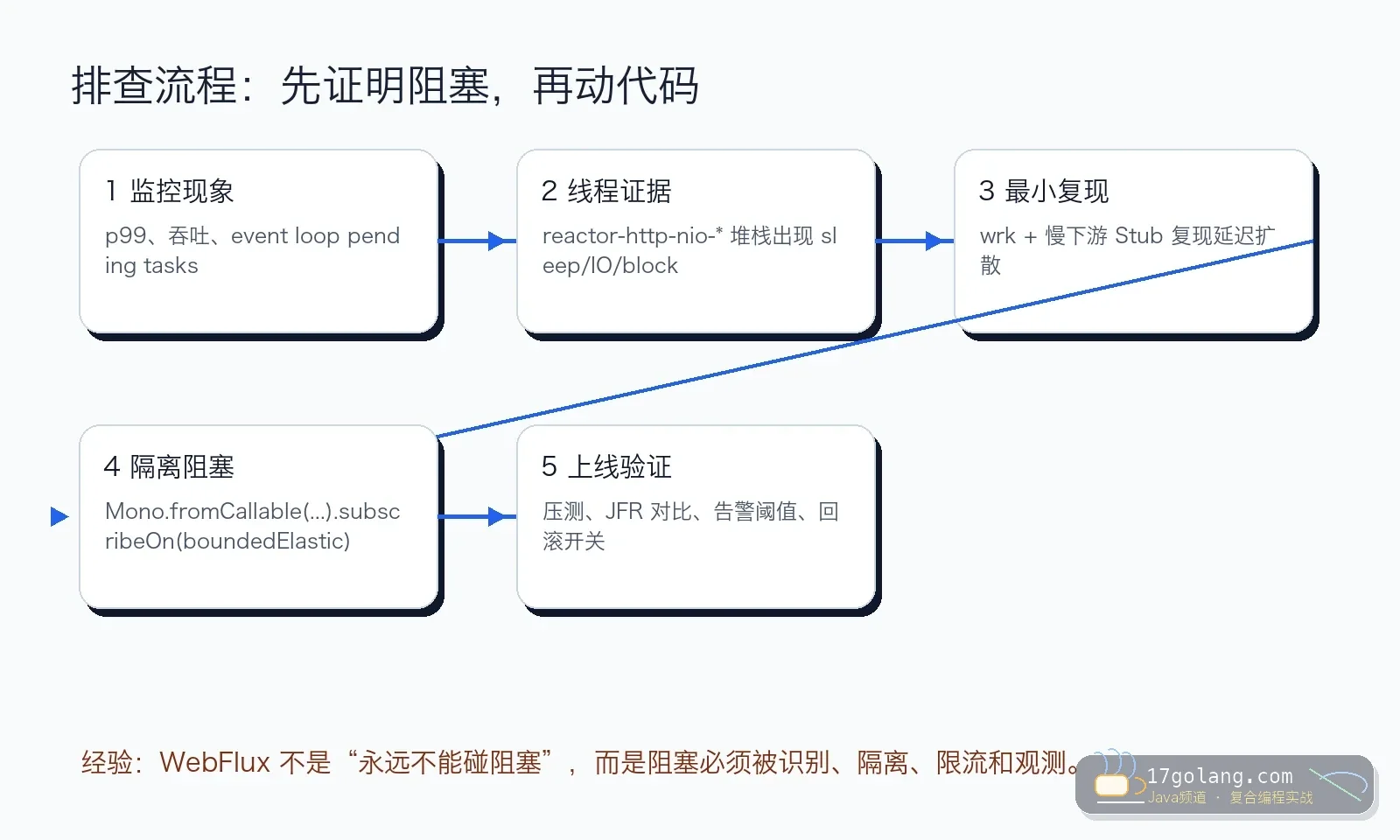
诊断步骤:我会按这五步走
第一步,看线程名。 日志 MDC 或堆栈里如果出现 reactor-http-nio-*,同时堆栈停在 JDBC、文件读取、同步 HTTP 客户端、锁等待,就要警惕。
第二步,抓 JFR。 重点看 Java Monitor Blocked、Socket Read、File Read、Thread Park 等事件是不是集中在事件循环线程。JFR 的好处是证据够硬,适合和业务团队对齐。
第三步,局部启用 BlockHound。 在测试环境或预发环境启用更合适,它能帮你较早发现阻塞调用。生产直接打开要谨慎,先评估兼容性和性能影响。
第四步,看 Reactor Netty 和接口指标。 把 p95/p99、响应码、下游耗时、连接池指标放在同一张图里。只看平均耗时,很容易把尖刺吞掉。
第五步,做改前改后压测。 只改代码不压测,等于没闭环。尤其要模拟下游慢 200ms、失败 5%、超时重试这些真实坏天气。
上线检查:别让修复变成新的事故
- 确认所有阻塞源都离开
reactor-http-nio线程。 - 确认 Scheduler 有上限,队列积压有指标,不要无限堆任务。
- 确认每个下游调用都有超时、降级或清晰的失败响应。
- 确认日志带业务 id、trace id、下游服务名和耗时。
- 确认灰度期间有 p99、错误率、线程池队列、JFR 采样对比。
我的经验总结
WebFlux 适合高并发 IO 场景,但它对工程纪律要求更高。你不能一边享受非阻塞模型的吞吐,一边把同步阻塞调用塞进事件循环。真正稳的做法,是把同步边界画清楚,把阻塞源隔离好,把超时和观测补齐。
最后一句很朴素:看到 Mono 不要自动放心,看到 reactor-http-nio 被阻塞要立刻紧张。生产里的 Java 性能优化,很多时候不是换一个更酷的框架,而是守住线程模型这条线。
 MySQL 8.4 锁等待治理实战:NOWAIT 和 SKIP LOCKED 怎么用才不乱
MySQL 8.4 锁等待治理实战:NOWAIT 和 SKIP LOCKED 怎么用才不乱