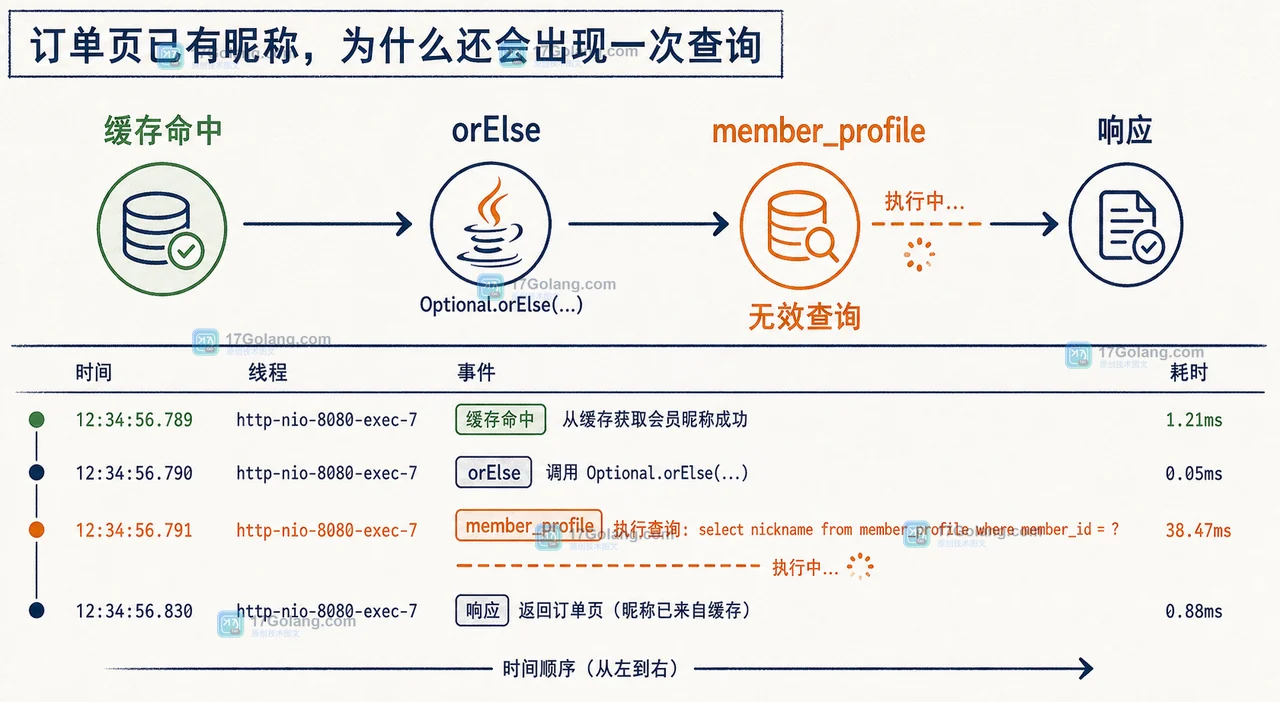
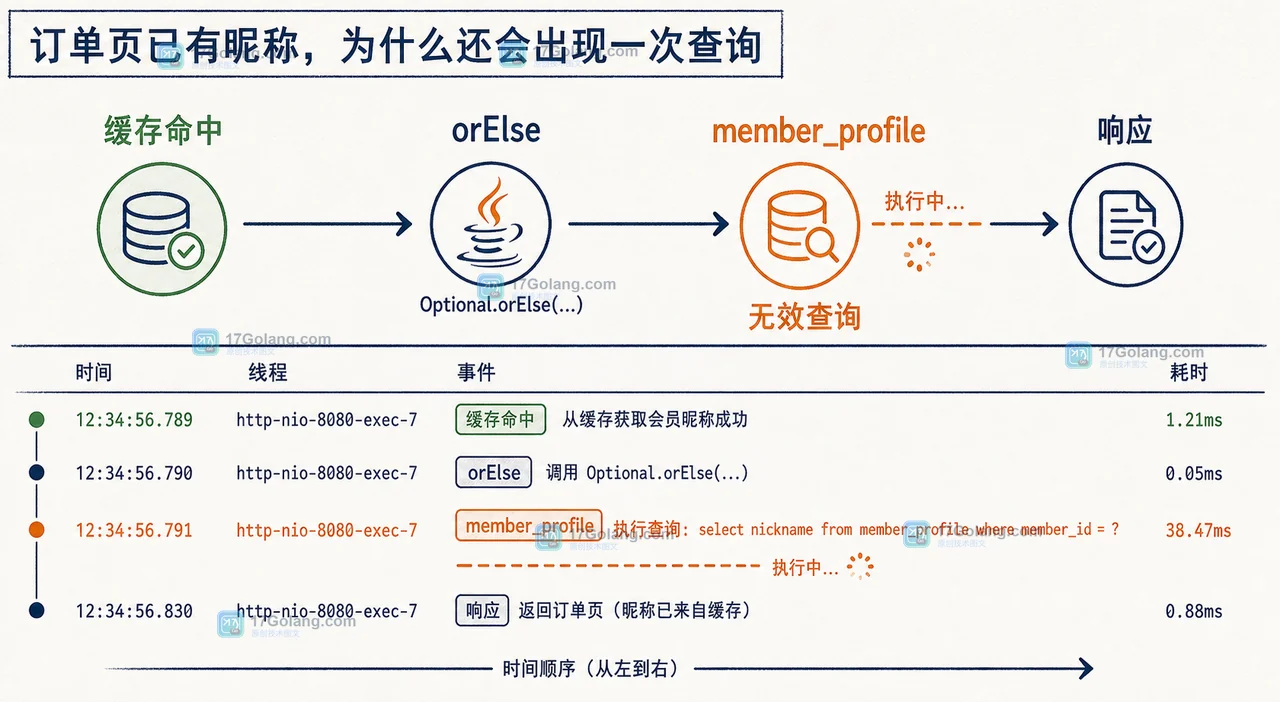
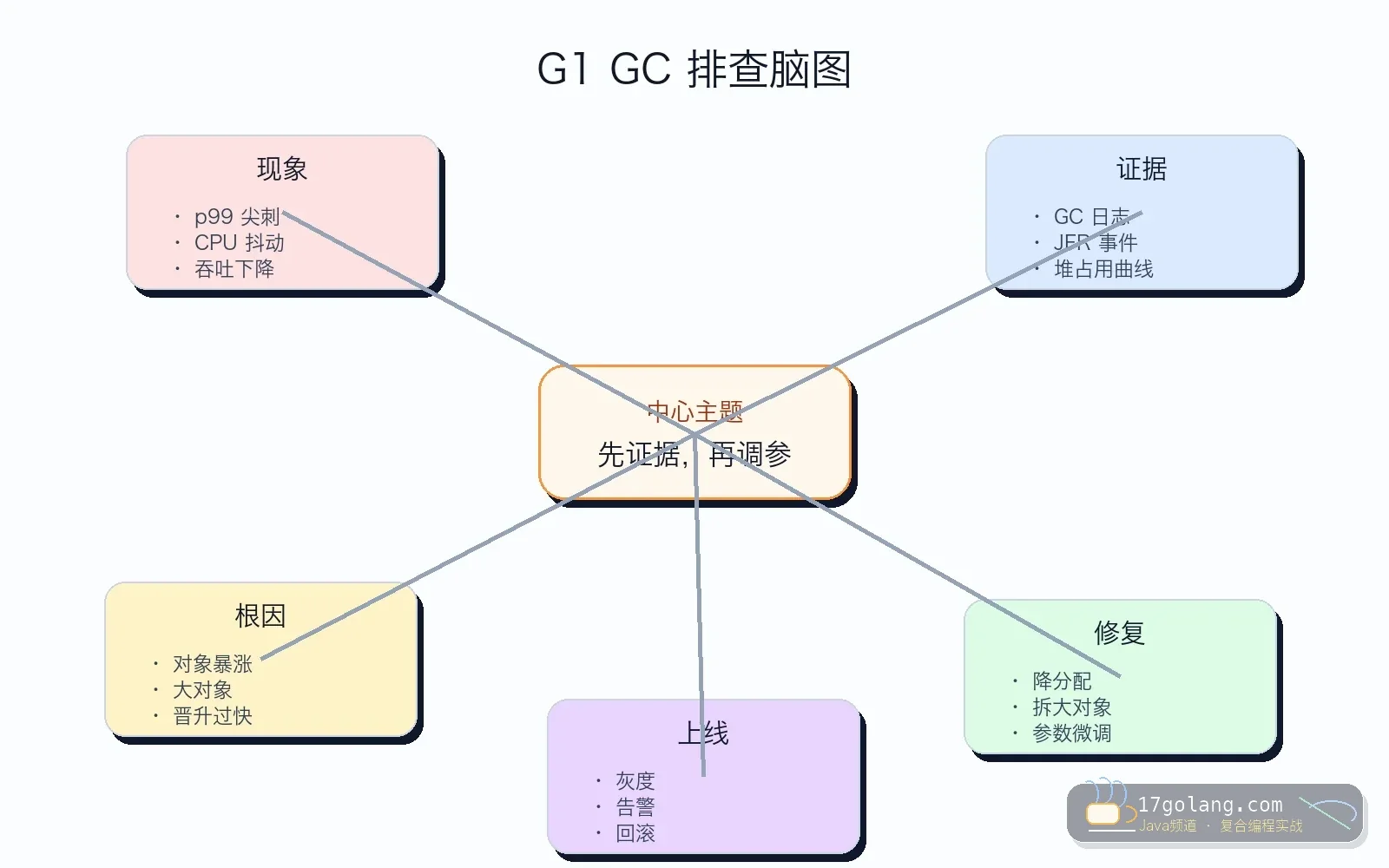
这篇写一个 Java 线上性能排查里最容易被“玄学参数”带偏的问题:接口 p99 突然出现尖刺,GC 日志里 G1 Pause 从几十毫秒变成两三百毫秒。很多人第一反应是去网上复制一串 JVM 参数,但真正有效的顺序应该是先拿证据,再小步调优。
本文适用于 Java 17/21、Spring Boot 服务和默认使用 G1 GC 的常见后端应用。资料只用于核对事实:G1 的暂停目标是软目标,官方也建议先从默认设置、最大堆和 GC 日志/JFR 证据出发。正文按生产复盘写,不搬调参清单。
业务场景:支付回调 p99 每隔几分钟尖一下
支付回调服务平时延迟很稳,某次活动后 p99 每隔几分钟就抬到 800ms。CPU 没满,数据库也没慢,但 GC 日志显示年轻代暂停明显变长,JFR 里还能看到大对象分配增多。
这类问题最怕只看平均值。平均耗时可能还行,但用户感受到的是尖刺。我们要把业务 p99、GC pause、堆占用、分配速率放到同一条时间线上看。
问题复现:批量查询加 JSON 序列化放大分配
最小复现是一个批量接口:一次查 2000 条订单,再把整批对象组装成大 JSON 返回。低峰没问题,高峰时 Eden 很快被填满,大对象还可能进入 humongous region,G1 为了回收和整理会产生更明显的暂停。
参数不是没有用,但如果业务代码持续制造大量短命对象和大对象,单靠 MaxGCPauseMillis 很难从根上解决问题。
踩坑原因:把暂停目标当硬指标
-XX:MaxGCPauseMillis 是目标,不是保证。目标设得太激进,G1 会尝试缩短暂停,但吞吐、并发回收压力和堆空间都会受影响。业务分配模式不变,暂停可能换一种方式继续出现。
我见过最危险的做法,是把一堆看不懂的 G1 参数复制到生产:新生代比例、IHOP、保留百分比、并发线程全改。短期似乎好了,下一次流量形态变化又出新问题,而且没人知道哪个参数起了作用。
代码案例:先打开可观测,再谈调参
下面这张图不是说参数永远不能调,而是建议先保留证据。没有 GC 日志、没有 JFR、没有分配来源,调参就是盲飞。

JAVA_OPTS=" -Xms4g -Xmx4g -Xlog:gc*,safepoint:file=/logs/gc-%t.log:time,level,tags:filecount=10,filesize=50M -XX:MaxGCPauseMillis=200 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/heapdump.hprof "
如果 JFR 显示分配集中在某个 JSON 转换、批量列表、缓存复制或日志拼接,优先改代码:分页、流式处理、减少中间对象、复用缓冲、限制响应大小。这些通常比把暂停目标从 200ms 改成 50ms 更靠谱。
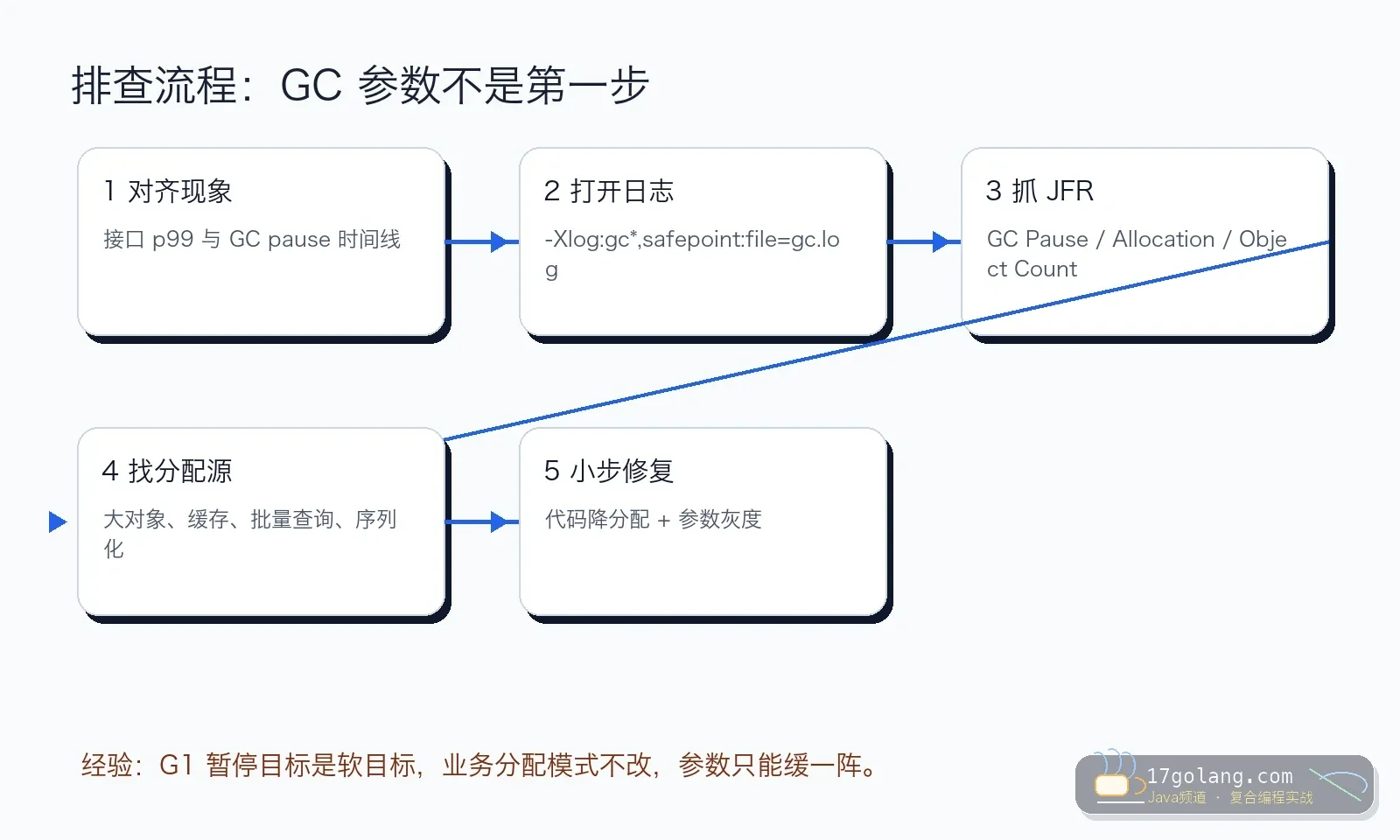
诊断步骤:我会按这六步走
第一步,对齐时间线。 把接口 p99、GC pause、CPU、堆占用、分配速率放在同一张图,不要只看单点日志。
第二步,打开 GC 日志。 看 young pause、mixed GC、humongous allocation、to-space exhausted、remark/cleanup 等关键信息。
第三步,抓 JFR。 重点看 GC Pause、Allocation in new TLAB/outside TLAB、Object Count、Socket/Thread Park 等事件。
第四步,找大对象和高频分配。 批量查询、一次性 JSON、图片/报表、日志拼接、大 Map 缓存都要重点查。
第五步,先改业务分配。 降低单请求对象量,拆批处理,限制列表大小,避免把大对象放进缓存。
第六步,再灰度参数。 每次只改少数参数,保留改前改后 GC 日志和业务指标。
上线检查:别让调参变成新风险
- 确认
-Xms、-Xmx与容器内存限制匹配,避免 OOMKill。 - 确认 GC 日志滚动配置,别把磁盘写满。
- 确认 p95/p99、GC pause、分配速率、Old 区占用都有告警。
- 确认每次参数变更都有灰度和回滚方案。
- 确认代码层面的分配优化已经验证,不把所有压力甩给 GC。
我的经验总结
G1 GC 很强,但它不是魔法。暂停变长时,先问业务最近是不是分配更多对象、响应更大、缓存更重、批处理更猛。GC 往往只是把应用的对象分配习惯暴露出来。
我的建议很简单:默认参数起步,日志和 JFR 先行,代码降分配优先,参数小步灰度。Java 生产优化最怕一把梭,最稳的是每一步都有证据。
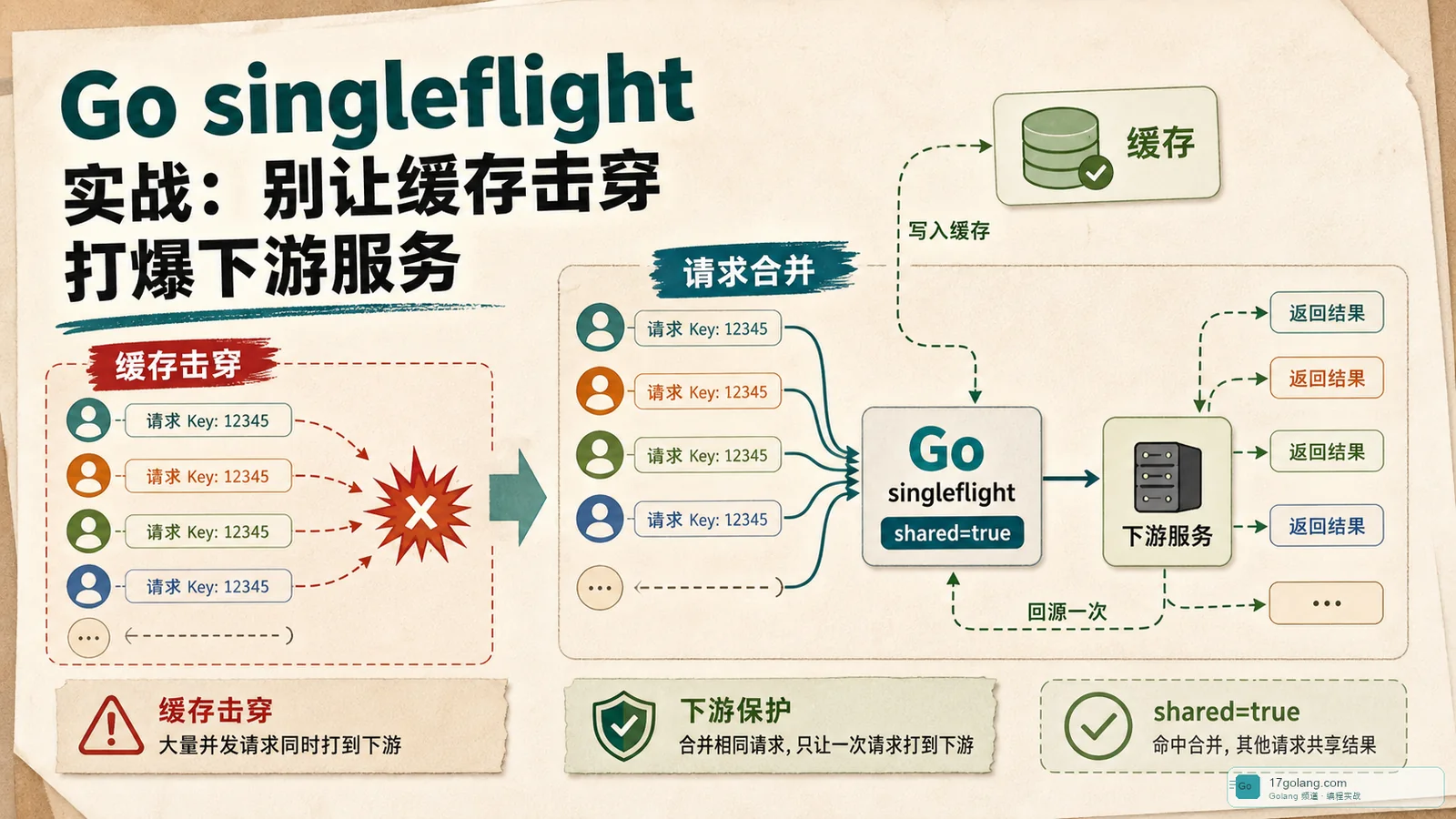 Go singleflight 实战:别让缓存击穿打爆下游服务
Go singleflight 实战:别让缓存击穿打爆下游服务